 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-based Camera-Agnostic Feature Learning for Intra-camera Person Re-Identification
Paper and Code
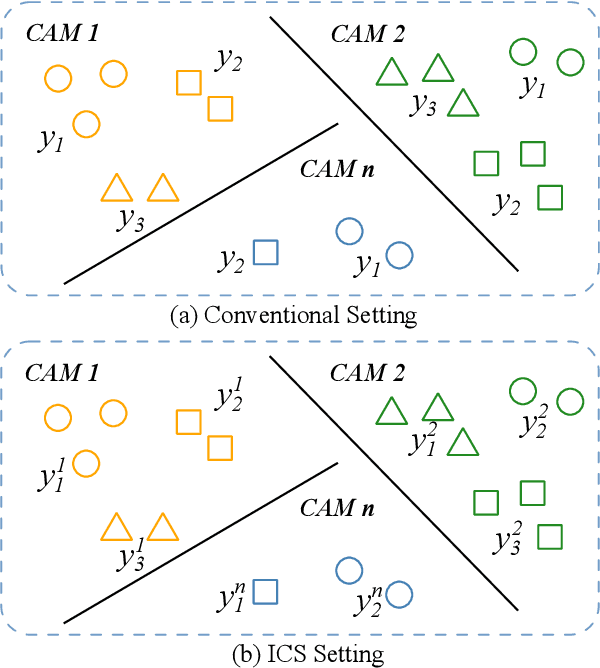
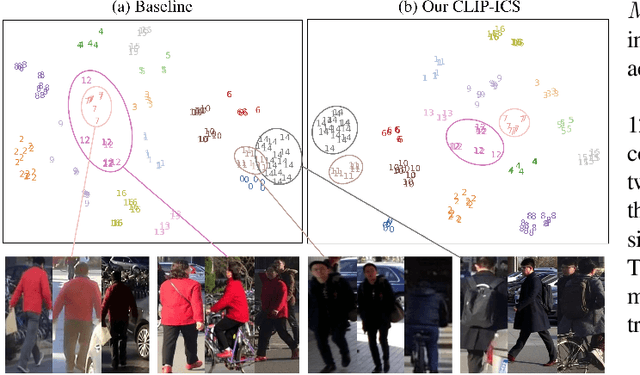
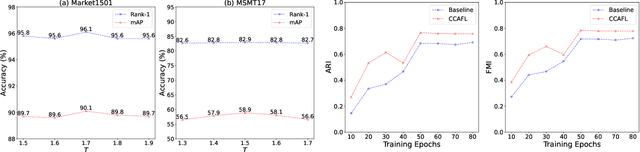
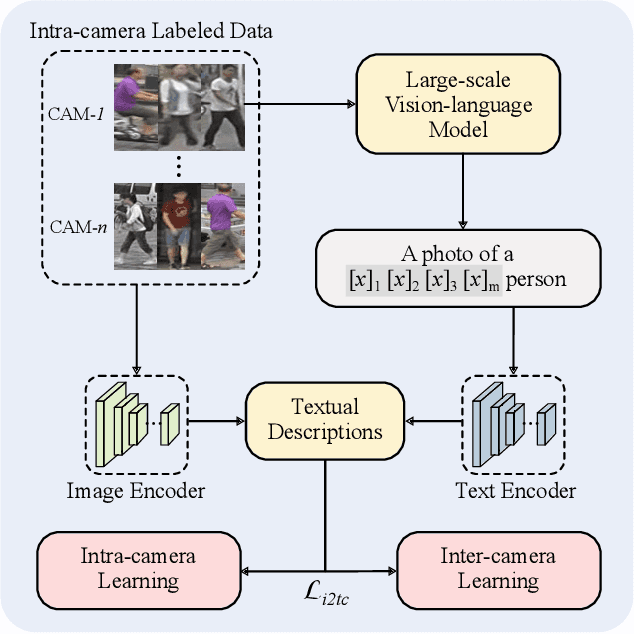
Contrastive Language-Image Pre-Training (CLIP) model excels in traditional person re-identification (ReID) tasks due to its inherent advantage in generating textual descriptions for pedestrian images. However, applying CLIP directly to intra-camera supervised person re-identification (ICS ReID) presents challenges. ICS ReID requires independent identity labeling within each camera, without associations across cameras. This limits the effectiveness of text-based enhancements. To address this, we propose a novel framework called CLIP-based Camera-Agnostic Feature Learning (CCAFL) for ICS ReID. Accordingly, two custom modules are designed to guide the model to actively learn camera-agnostic pedestrian features: Intra-Camera Discriminative Learning (ICDL) and Inter-Camera Adversarial Learning (ICAL). Specifically, we first establish learnable textual prompts for intra-camera pedestrian images to obtain crucial semantic supervision signals for subsequent intra- and inter-camera learning. Then, we design ICDL to increase inter-class variation by considering the hard positive and hard negative samples within each camera, thereby learning intra-camera finer-grained pedestrian features. Additionally, we propose ICAL to reduce inter-camera pedestrian feature discrepancies by penalizing the model's ability to predict the camera from which a pedestrian image originates, thus enhancing the model's capability to recognize pedestrians from different viewpoints. Extensive experiments on popular ReID datasets demonstrate the effectiveness of our approach. Especially, on the challenging MSMT17 dataset, we arrive at 58.9\% in terms of mAP accuracy, surpassing state-of-the-art methods by 7.6\%. Code will be available at: https://github.com/Trangle12/CCAFL.