 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception
Feb 16, 2026Multimodal Large Language Models (MLLMs) excel at broad visual understanding but still struggle with fine-grained perception, where decisive evidence is small and easily overwhelmed by global context. Recent "Thinking-with-Images" methods alleviate this by iteratively zooming in and out regions of interest during inference, but incur high latency due to repeated tool calls and visual re-encoding. To address this, we propose Region-to-Image Distillation, which transforms zooming from an inference-time tool into a training-time primitive, thereby internalizing the benefits of agentic zooming into a single forward pass of an MLLM. In particular, we first zoom in to micro-cropped regions to let strong teacher models generate high-quality VQA data, and then distill this region-grounded supervision back to the full image. After training on such data, the smaller student model improves "single-glance" fine-grained perception without tool use. To rigorously evaluate this capability, we further present ZoomBench, a hybrid-annotated benchmark of 845 VQA data spanning six fine-grained perceptual dimensions, together with a dual-view protocol that quantifies the global--regional "zooming gap". Experiments show that our models achieve leading performance across multiple fine-grained perception benchmarks, and also improve general multimodal cognition on benchmarks such as visual reasoning and GUI agents. We further discuss when "Thinking-with-Images" is necessary versus when its gains can be distilled into a single forward pass. Our code is available at https://github.com/inclusionAI/Zooming-without-Zooming.
VideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
Feb 09, 2026The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
Up to 36x Speedup: Mask-based Parallel Inference Paradigm for Key Information Extraction in MLLMs
Jan 27, 2026Key Information Extraction (KIE) from visually-rich documents (VrDs) is a critical task, for which recent Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) have demonstrated strong potential. However, their reliance on autoregressive inference, which generates outputs sequentially, creates a significant efficiency bottleneck, especially as KIE tasks often involve extracting multiple, semantically independent fields. To overcome this limitation, we introduce PIP: a Parallel Inference Paradigm for KIE. Our approach reformulates the problem by using "[mask]" tokens as placeholders for all target values, enabling their simultaneous generation in a single forward pass. To facilitate this paradigm, we develop a tailored mask pre-training strategy and construct large-scale supervised datasets. Experimental results show that our PIP-models achieve a 5-36x inference speedup with negligible performance degradation compared to traditional autoregressive base models. By substantially improving efficiency while maintaining high accuracy, PIP paves the way for scalable and practical real-world KIE solutions.
EchoingPixels: Cross-Modal Adaptive Token Reduction for Efficient Audio-Visual LLMs
Dec 11, 2025
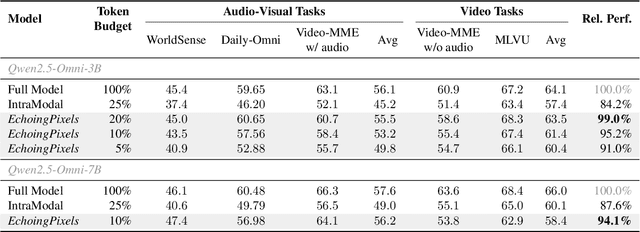
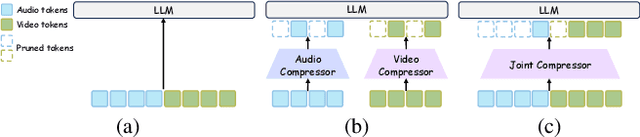
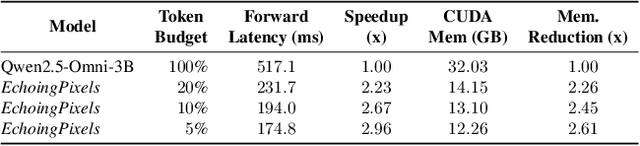
Audio-Visual Large Language Models (AV-LLMs) face prohibitive computational overhead from massive audio and video tokens. Token reduction, while extensively explored for video-only LLMs, is insufficient for the audio-visual domain, as these unimodal methods cannot leverage audio-visual cross-modal synergies. Furthermore, the distinct and dynamic information densities of audio and video render static budgets per modality suboptimal. How to perform token reduction on a joint audio-visual stream thus remains an unaddressed bottleneck. To fill this gap, we introduce EchoingPixels, a framework inspired by the coexistence and interaction of visuals and sound in real-world scenes. The core of our framework is the Cross-Modal Semantic Sieve (CS2), a module enabling early audio-visual interaction. Instead of compressing modalities independently, CS2 co-attends to the joint multimodal stream and reduces tokens from an entire combined pool of audio-visual tokens rather than using fixed budgets per modality. This single-pool approach allows it to adaptively allocate the token budget across both modalities and dynamically identify salient tokens in concert. To ensure this aggressive reduction preserves the vital temporal modeling capability, we co-design a Synchronization-Augmented RoPE (Sync-RoPE) to maintain critical temporal relationships for the sparsely selected tokens. Extensive experiments demonstrate that EchoingPixels achieves performance comparable to strong baselines using only 5-20% of the original tokens, with a 2-3x speedup and memory reduction.
Veritas: Generalizable Deepfake Detection via Pattern-Aware Reasoning
Aug 28, 2025



Deepfake detection remains a formidable challenge due to the complex and evolving nature of fake content in real-world scenarios. However, existing academic benchmarks suffer from severe discrepancies from industrial practice, typically featuring homogeneous training sources and low-quality testing images, which hinder the practical deployments of current detectors. To mitigate this gap, we introduce HydraFake, a dataset that simulates real-world challenges with hierarchical generalization testing. Specifically, HydraFake involves diversified deepfake techniques and in-the-wild forgeries, along with rigorous training and evaluation protocol, covering unseen model architectures, emerging forgery techniques and novel data domains. Building on this resource, we propose Veritas, a multi-modal large language model (MLLM) based deepfake detector. Different from vanilla chain-of-thought (CoT), we introduce pattern-aware reasoning that involves critical reasoning patterns such as "planning" and "self-reflection" to emulate human forensic process. We further propose a two-stage training pipeline to seamlessly internalize such deepfake reasoning capacities into current MLLMs. Experiments on HydraFake dataset reveal that although previous detectors show great generalization on cross-model scenarios, they fall short on unseen forgeries and data domains. Our Veritas achieves significant gains across different OOD scenarios, and is capable of delivering transparent and faithful detection outputs.
Interpretable and Reliable Detection of AI-Generated Images via Grounded Reasoning in MLLMs
Jun 08, 2025
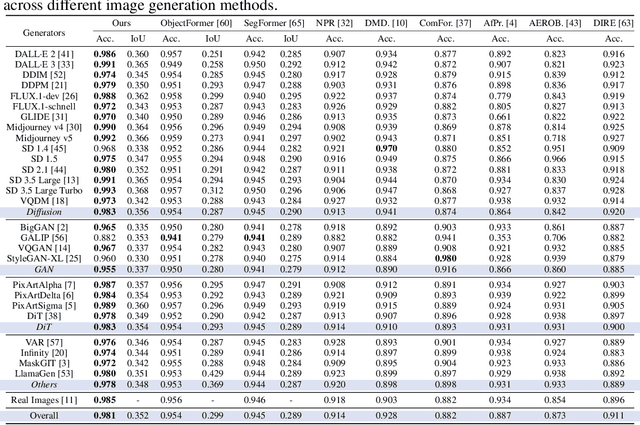


The rapid advancement of image generation technologies intensifies the demand for interpretable and robust detection methods. Although existing approaches often attain high accuracy, they typically operate as black boxes without providing human-understandable justifications. Multi-modal Large Language Models (MLLMs), while not originally intended for forgery detection, exhibit strong analytical and reasoning capabilities. When properly fine-tuned, they can effectively identify AI-generated images and offer meaningful explanations. However, existing MLLMs still struggle with hallucination and often fail to align their visual interpretations with actual image content and human reasoning. To bridge this gap, we construct a dataset of AI-generated images annotated with bounding boxes and descriptive captions that highlight synthesis artifacts, establishing a foundation for human-aligned visual-textual grounded reasoning. We then finetune MLLMs through a multi-stage optimization strategy that progressively balances the objectives of accurate detection, visual localization, and coherent textual explanation. The resulting model achieves superior performance in both detecting AI-generated images and localizing visual flaws, significantly outperforming baseline methods.
BR-ASR: Efficient and Scalable Bias Retrieval Framework for Contextual Biasing ASR in Speech LLM
May 25, 2025While speech large language models (SpeechLLMs) have advanced standard automatic speech recognition (ASR), contextual biasing for named entities and rare words remains challenging, especially at scale. To address this, we propose BR-ASR: a Bias Retrieval framework for large-scale contextual biasing (up to 200k entries) via two innovations: (1) speech-and-bias contrastive learning to retrieve semantically relevant candidates; (2) dynamic curriculum learning that mitigates homophone confusion which negatively impacts the final performance. The is a general framework that allows seamless integration of the retrieved candidates into diverse ASR systems without fine-tuning. Experiments on LibriSpeech test-clean/-other achieve state-of-the-art (SOTA) biased word error rates (B-WER) of 2.8%/7.1% with 2000 bias words, delivering 45% relative improvement over prior methods. BR-ASR also demonstrates high scalability: when expanding the bias list to 200k where traditional methods generally fail, it induces only 0.3 / 2.9% absolute WER / B-WER degradation with a 99.99% pruning rate and only 20ms latency per query on test-other.
Keep the General, Inject the Specific: Structured Dialogue Fine-Tuning for Knowledge Injection without Catastrophic Forgetting
Apr 27, 2025
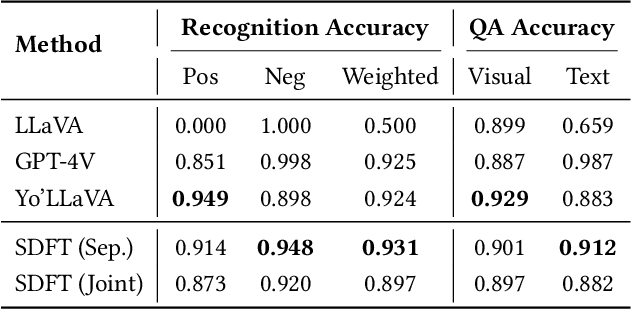
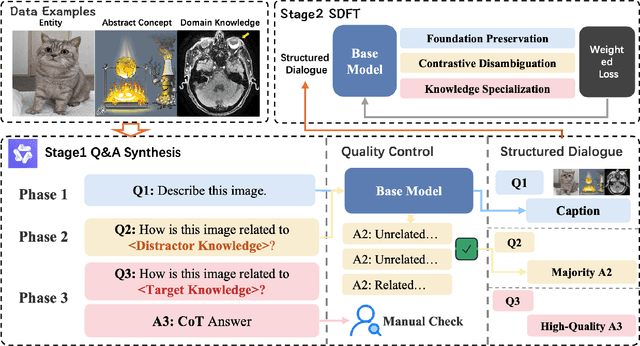

Large Vision Language Models have demonstrated impressive versatile capabilities through extensive multimodal pre-training, but face significant limitations when incorporating specialized knowledge domains beyond their training distribution. These models struggle with a fundamental dilemma: direct adaptation approaches that inject domain-specific knowledge often trigger catastrophic forgetting of foundational visual-linguistic abilities. We introduce Structured Dialogue Fine-Tuning (SDFT), an effective approach that effectively injects domain-specific knowledge while minimizing catastrophic forgetting. Drawing inspiration from supervised fine-tuning in LLMs and subject-driven personalization in text-to-image diffusion models, our method employs a three-phase dialogue structure: Foundation Preservation reinforces pre-trained visual-linguistic alignment through caption tasks; Contrastive Disambiguation introduces carefully designed counterfactual examples to maintain semantic boundaries; and Knowledge Specialization embeds specialized information through chain-of-thought reasoning. Experimental results across multiple domains confirm SDFT's effectiveness in balancing specialized knowledge acquisition with general capability retention. Our key contributions include a data-centric dialogue template that balances foundational alignment with targeted knowledge integration, a weighted multi-turn supervision framework, and comprehensive evaluation across diverse knowledge types.
COCO-Inpaint: A Benchmark for Image Inpainting Detection and Manipulation Localization
Apr 25, 2025
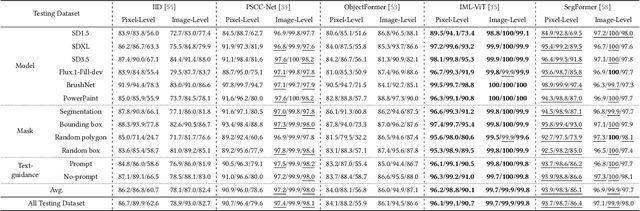


Recent advancements in image manipulation have achieved unprecedented progress in generating photorealistic content, but also simultaneously eliminating barriers to arbitrary manipulation and editing, raising concerns about multimedia authenticity and cybersecurity. However, existing Image Manipulation Detection and Localization (IMDL) methodologies predominantly focus on splicing or copy-move forgeries, lacking dedicated benchmarks for inpainting-based manipulations. To bridge this gap, we present COCOInpaint, a comprehensive benchmark specifically designed for inpainting detection, with three key contributions: 1) High-quality inpainting samples generated by six state-of-the-art inpainting models, 2) Diverse generation scenarios enabled by four mask generation strategies with optional text guidance, and 3) Large-scale coverage with 258,266 inpainted images with rich semantic diversity. Our benchmark is constructed to emphasize intrinsic inconsistencies between inpainted and authentic regions, rather than superficial semantic artifacts such as object shapes. We establish a rigorous evaluation protocol using three standard metrics to assess existing IMDL approaches. The dataset will be made publicly available to facilitate future research in this area.