 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
Structural Energy-Guided Sampling for View-Consistent Text-to-3D
Aug 23, 2025Text-to-3D generation often suffers from the Janus problem, where objects look correct from the front but collapse into duplicated or distorted geometry from other angles. We attribute this failure to viewpoint bias in 2D diffusion priors, which propagates into 3D optimization. To address this, we propose Structural Energy-Guided Sampling (SEGS), a training-free, plug-and-play framework that enforces multi-view consistency entirely at sampling time. SEGS defines a structural energy in a PCA subspace of intermediate U-Net features and injects its gradients into the denoising trajectory, steering geometry toward the intended viewpoint while preserving appearance fidelity. Integrated seamlessly into SDS/VSD pipelines, SEGS significantly reduces Janus artifacts, achieving improved geometric alignment and viewpoint consistency without retraining or weight modification.
GS-2DGS: Geometrically Supervised 2DGS for Reflective Object Reconstruction
Jun 16, 20253D modeling of highly reflective objects remains challenging due to strong view-dependent appearances. While previous SDF-based methods can recover high-quality meshes, they are often time-consuming and tend to produce over-smoothed surfaces. In contrast, 3D Gaussian Splatting (3DGS) offers the advantage of high speed and detailed real-time rendering, but extracting surfaces from the Gaussians can be noisy due to the lack of geometric constraints. To bridge the gap between these approaches, we propose a novel reconstruction method called GS-2DGS for reflective objects based on 2D Gaussian Splatting (2DGS). Our approach combines the rapid rendering capabilities of Gaussian Splatting with additional geometric information from foundation models. Experimental results on synthetic and real datasets demonstrate that our method significantly outperforms Gaussian-based techniques in terms of reconstruction and relighting and achieves performance comparable to SDF-based methods while being an order of magnitude faster. Code is available at https://github.com/hirotong/GS2DGS
Enhancing Features in Long-tailed Data Using Large Vision Mode
Apr 15, 2025Language-based foundation models, such as large language models (LLMs) or large vision-language models (LVLMs), have been widely studied in long-tailed recognition. However, the need for linguistic data is not applicable to all practical tasks. In this study, we aim to explore using large vision models (LVMs) or visual foundation models (VFMs) to enhance long-tailed data features without any language information. Specifically, we extract features from the LVM and fuse them with features in the baseline network's map and latent space to obtain the augmented features. Moreover, we design several prototype-based losses in the latent space to further exploit the potential of the augmented features. In the experimental section, we validate our approach on two benchmark datasets: ImageNet-LT and iNaturalist2018.
Maintain Plasticity in Long-timescale Continual Test-time Adaptation
Dec 28, 2024



Continual test-time domain adaptation (CTTA) aims to adjust pre-trained source models to perform well over time across non-stationary target environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: can the model adapt to continually-changing environments with preserved plasticity over a long time? The plasticity refers to the model's capability to adjust predictions in response to non-stationary environments continually. In this work, we explore plasticity, this essential but often overlooked aspect of continual adaptation to facilitate more sustained adaptation in the long run. First, we observe that most CTTA methods experience a steady and consistent decline in plasticity during the long-timescale continual adaptation phase. Moreover, we find that the loss of plasticity is strongly associated with the change in label flip. Based on this correlation, we propose a simple yet effective policy, Adaptive Shrink-Restore (ASR), towards preserving the model's plasticity. In particular, ASR does the weight re-initialization by the adaptive intervals. The adaptive interval is determined based on the change in label flipping. Our method is validated on extensive CTTA benchmarks, achieving excellent performance.
DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Monocular Dynamic 3D Reconstruction
Dec 05, 2024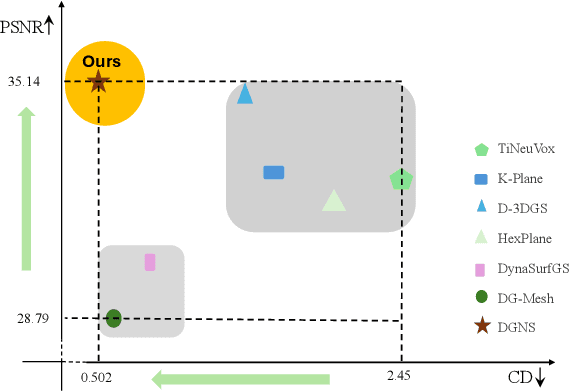
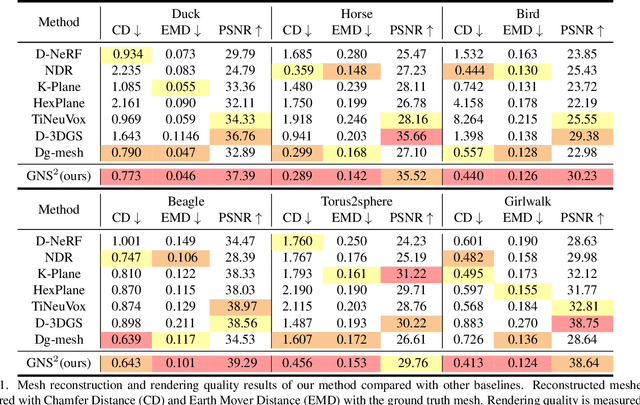

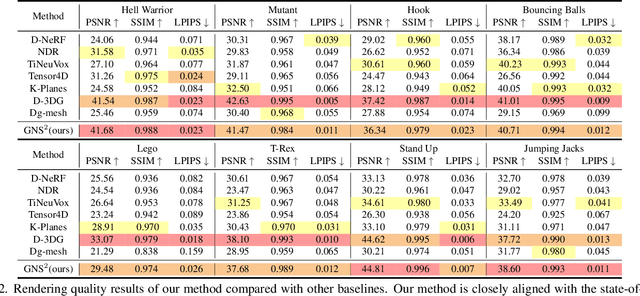
Dynamic scene reconstruction from monocular video is critical for real-world applications. This paper tackles the dual challenges of dynamic novel-view synthesis and 3D geometry reconstruction by introducing a hybrid framework: Deformable Gaussian Splatting and Dynamic Neural Surfaces (DGNS), in which both modules can leverage each other for both tasks. During training, depth maps generated by the deformable Gaussian splatting module guide the ray sampling for faster processing and provide depth supervision within the dynamic neural surface module to improve geometry reconstruction. Simultaneously, the dynamic neural surface directs the distribution of Gaussian primitives around the surface, enhancing rendering quality. To further refine depth supervision, we introduce a depth-filtering process on depth maps derived from Gaussian rasterization. Extensive experiments on public datasets demonstrate that DGNS achieves state-of-the-art performance in both novel-view synthesis and 3D reconstruction.
Viewpoint Consistency in 3D Generation via Attention and CLIP Guidance
Dec 03, 2024



Despite recent advances in text-to-3D generation techniques, current methods often suffer from geometric inconsistencies, commonly referred to as the Janus Problem. This paper identifies the root cause of the Janus Problem: viewpoint generation bias in diffusion models, which creates a significant gap between the actual generated viewpoint and the expected one required for optimizing the 3D model. To address this issue, we propose a tuning-free approach called the Attention and CLIP Guidance (ACG) mechanism. ACG enhances desired viewpoints by adaptively controlling cross-attention maps, employs CLIP-based view-text similarities to filter out erroneous viewpoints, and uses a coarse-to-fine optimization strategy with staged prompts to progressively refine 3D generation. Extensive experiments demonstrate that our method significantly reduces the Janus Problem without compromising generation speed, establishing ACG as an efficient, plug-and-play component for existing text-to-3D frameworks.
Seeing Through the Glass: Neural 3D Reconstruction of Object Inside a Transparent Container
Mar 24, 2023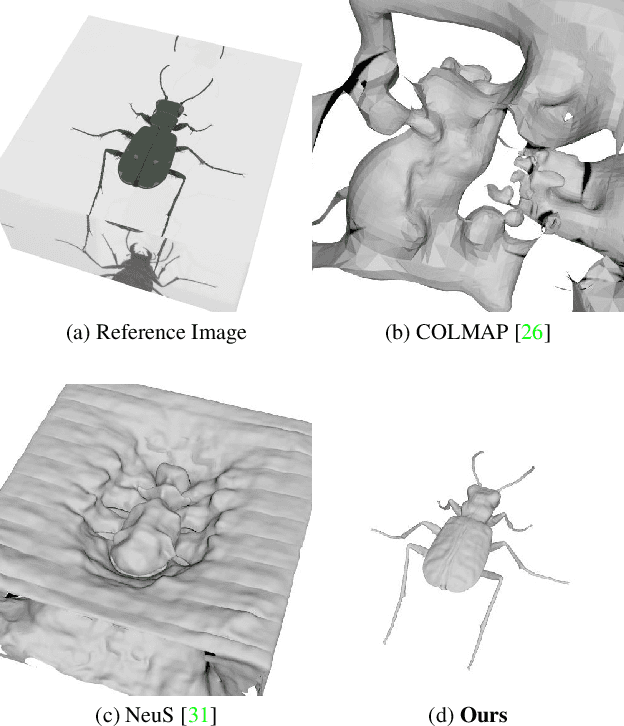
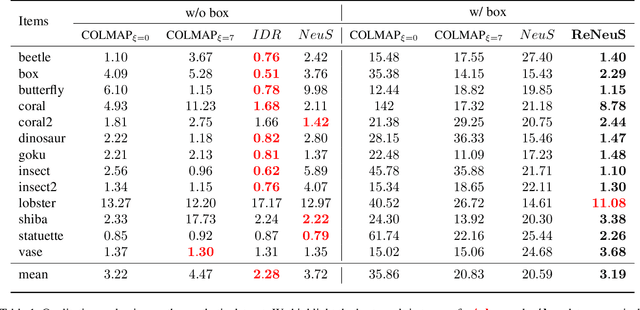
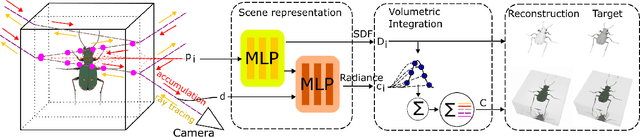

In this paper, we define a new problem of recovering the 3D geometry of an object confined in a transparent enclosure. We also propose a novel method for solving this challenging problem. Transparent enclosures pose challenges of multiple light reflections and refractions at the interface between different propagation media e.g. air or glass. These multiple reflections and refractions cause serious image distortions which invalidate the single viewpoint assumption. Hence the 3D geometry of such objects cannot be reliably reconstructed using existing methods, such as traditional structure from motion or modern neural reconstruction methods. We solve this problem by explicitly modeling the scene as two distinct sub-spaces, inside and outside the transparent enclosure. We use an existing neural reconstruction method (NeuS) that implicitly represents the geometry and appearance of the inner subspace. In order to account for complex light interactions, we develop a hybrid rendering strategy that combines volume rendering with ray tracing. We then recover the underlying geometry and appearance of the model by minimizing the difference between the real and hybrid rendered images. We evaluate our method on both synthetic and real data. Experiment results show that our method outperforms the state-of-the-art (SOTA) methods. Codes and data will be available at https://github.com/hirotong/ReNeuS
Voxelized 3D Feature Aggregation for Multiview Detection
Dec 07, 2021
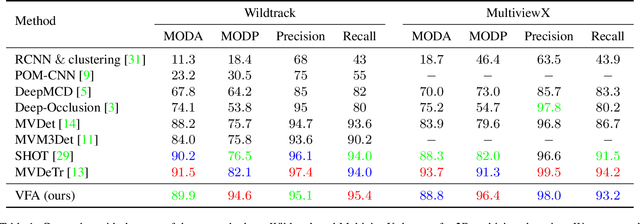


Multi-view detection incorporates multiple camera views to alleviate occlusion in crowded scenes, where the state-of-the-art approaches adopt homography transformations to project multi-view features to the ground plane. However, we find that these 2D transformations do not take into account the object's height, and with this neglection features along the vertical direction of same object are likely not projected onto the same ground plane point, leading to impure ground-plane features. To solve this problem, we propose VFA, voxelized 3D feature aggregation, for feature transformation and aggregation in multi-view detection. Specifically, we voxelize the 3D space, project the voxels onto each camera view, and associate 2D features with these projected voxels. This allows us to identify and then aggregate 2D features along the same vertical line, alleviating projection distortions to a large extent. Additionally, because different kinds of objects (human vs. cattle) have different shapes on the ground plane, we introduce the oriented Gaussian encoding to match such shapes, leading to increased accuracy and efficiency. We perform experiments on multiview 2D detection and multiview 3D detection problems. Results on four datasets (including a newly introduced MultiviewC dataset) show that our system is very competitive compared with the state-of-the-art approaches. %Our code and data will be open-sourced.Code and MultiviewC are released at https://github.com/Robert-Mar/VFA.