 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
SVGBuilder: Component-Based Colored SVG Generation with Text-Guided Autoregressive Transformers
Dec 17, 2024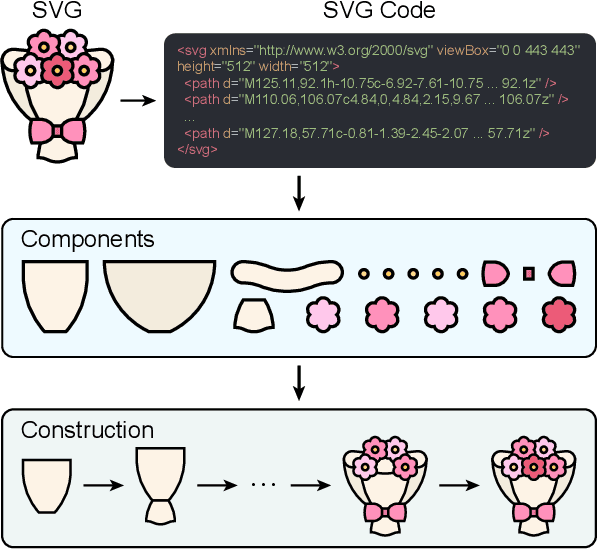
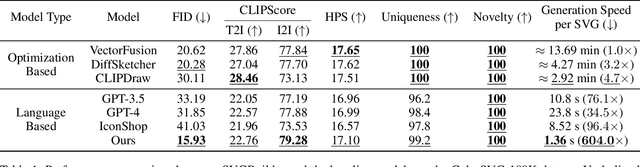
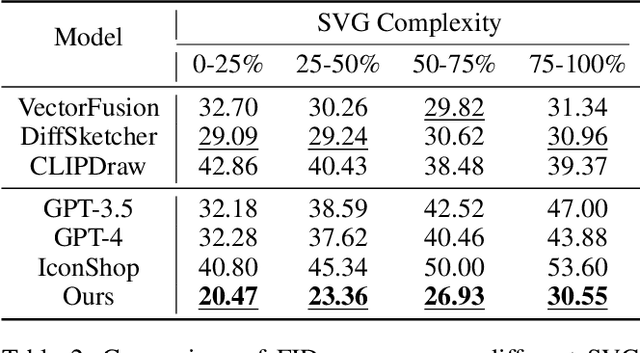
Scalable Vector Graphics (SVG) are essential XML-based formats for versatile graphics, offering resolution independence and scalability. Unlike raster images, SVGs use geometric shapes and support interactivity, animation, and manipulation via CSS and JavaScript. Current SVG generation methods face challenges related to high computational costs and complexity. In contrast, human designers use component-based tools for efficient SVG creation. Inspired by this, SVGBuilder introduces a component-based, autoregressive model for generating high-quality colored SVGs from textual input. It significantly reduces computational overhead and improves efficiency compared to traditional methods. Our model generates SVGs up to 604 times faster than optimization-based approaches. To address the limitations of existing SVG datasets and support our research, we introduce ColorSVG-100K, the first large-scale dataset of colored SVGs, comprising 100,000 graphics. This dataset fills the gap in color information for SVG generation models and enhances diversity in model training. Evaluation against state-of-the-art models demonstrates SVGBuilder's superior performance in practical applications, highlighting its efficiency and quality in generating complex SVG graphics.
Viewpoint Consistency in 3D Generation via Attention and CLIP Guidance
Dec 03, 2024



Despite recent advances in text-to-3D generation techniques, current methods often suffer from geometric inconsistencies, commonly referred to as the Janus Problem. This paper identifies the root cause of the Janus Problem: viewpoint generation bias in diffusion models, which creates a significant gap between the actual generated viewpoint and the expected one required for optimizing the 3D model. To address this issue, we propose a tuning-free approach called the Attention and CLIP Guidance (ACG) mechanism. ACG enhances desired viewpoints by adaptively controlling cross-attention maps, employs CLIP-based view-text similarities to filter out erroneous viewpoints, and uses a coarse-to-fine optimization strategy with staged prompts to progressively refine 3D generation. Extensive experiments demonstrate that our method significantly reduces the Janus Problem without compromising generation speed, establishing ACG as an efficient, plug-and-play component for existing text-to-3D frameworks.
Manipulated Face Detector: Joint Spatial and Frequency Domain Attention Network
May 06, 2020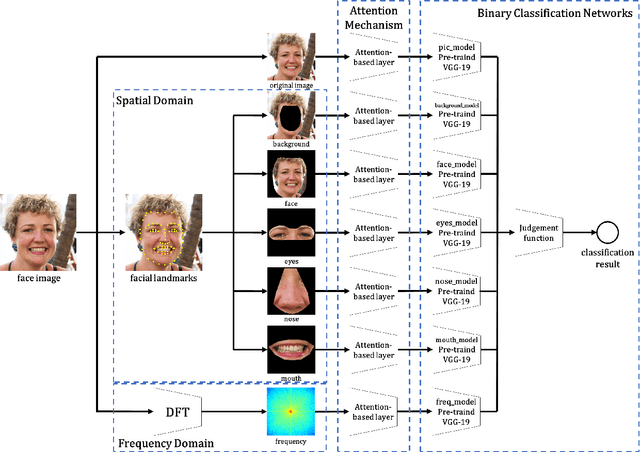



Face manipulation methods develop rapidly in recent years, which can generate high quality manipulated face images. However, detection methods perform not well on data produced by state-of-the-art manipulation methods, and they lack of generalization ability. In this paper, we propose a novel manipulated face detector, which is based on spatial and frequency domain combination and attention mechanism. Spatial domain features are extracted by facial semantic segmentation, and frequency domain features are extracted by Discrete Fourier Transform. We use features both in spatial domain and frequency domain as inputs in proposed model. And we add attention-based layers to backbone networks, in order to improve its generalization ability. We evaluate proposed model on several datasets and compare it with other state-of-the-art manipulated face detection methods. The results show our model performs best on both seen and unseen data.