 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Energy Guidance for View-Consistent Text-to-3D Generation
May 19, 2026Text-to-3D generation based on diffusion models often suffers from the Janus problem, leading to inconsistent geometry across viewpoints. This work identifies viewpoint bias in 2D diffusion priors as the main cause and proposes Structural Energy-Guided Sampling (SEGS), a training-free and plug-and-play framework to improve multi-view consistency. SEGS constructs a structural energy in the PCA subspace of U-Net features and injects its gradient into the denoising process. It can be easily integrated into SDS/VSD pipelines without retraining. Experiments show that SEGS reduces the Janus Rate by about 10% on average and improves View-CS scores across multiple baselines, including DreamFusion, Magic3D, and LucidDreamer. This method effectively alleviates viewpoint artifacts while preserving appearance fidelity, providing a flexible solution for high-quality text-to-3D content generation.
EgoSelf: From Memory to Personalized Egocentric Assistant
Apr 22, 2026Egocentric assistants often rely on first-person view data to capture user behavior and context for personalized services. Since different users exhibit distinct habits, preferences, and routines, such personalization is essential for truly effective assistance. However, effectively integrating long-term user data for personalization remains a key challenge. To address this, we introduce EgoSelf, a system that includes a graph-based interaction memory constructed from past observations and a dedicated learning task for personalization. The memory captures temporal and semantic relationships among interaction events and entities, from which user-specific profiles are derived. The personalized learning task is formulated as a prediction problem where the model predicts possible future interactions from individual user's historical behavior recorded in the graph. Extensive experiments demonstrate the effectiveness of EgoSelf as a personalized egocentric assistant. Code is available at https://abie-e.github.io/EgoSelf/.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
Structural Energy-Guided Sampling for View-Consistent Text-to-3D
Aug 23, 2025Text-to-3D generation often suffers from the Janus problem, where objects look correct from the front but collapse into duplicated or distorted geometry from other angles. We attribute this failure to viewpoint bias in 2D diffusion priors, which propagates into 3D optimization. To address this, we propose Structural Energy-Guided Sampling (SEGS), a training-free, plug-and-play framework that enforces multi-view consistency entirely at sampling time. SEGS defines a structural energy in a PCA subspace of intermediate U-Net features and injects its gradients into the denoising trajectory, steering geometry toward the intended viewpoint while preserving appearance fidelity. Integrated seamlessly into SDS/VSD pipelines, SEGS significantly reduces Janus artifacts, achieving improved geometric alignment and viewpoint consistency without retraining or weight modification.
Enhancing Features in Long-tailed Data Using Large Vision Mode
Apr 15, 2025Language-based foundation models, such as large language models (LLMs) or large vision-language models (LVLMs), have been widely studied in long-tailed recognition. However, the need for linguistic data is not applicable to all practical tasks. In this study, we aim to explore using large vision models (LVMs) or visual foundation models (VFMs) to enhance long-tailed data features without any language information. Specifically, we extract features from the LVM and fuse them with features in the baseline network's map and latent space to obtain the augmented features. Moreover, we design several prototype-based losses in the latent space to further exploit the potential of the augmented features. In the experimental section, we validate our approach on two benchmark datasets: ImageNet-LT and iNaturalist2018.
Maintain Plasticity in Long-timescale Continual Test-time Adaptation
Dec 28, 2024



Continual test-time domain adaptation (CTTA) aims to adjust pre-trained source models to perform well over time across non-stationary target environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: can the model adapt to continually-changing environments with preserved plasticity over a long time? The plasticity refers to the model's capability to adjust predictions in response to non-stationary environments continually. In this work, we explore plasticity, this essential but often overlooked aspect of continual adaptation to facilitate more sustained adaptation in the long run. First, we observe that most CTTA methods experience a steady and consistent decline in plasticity during the long-timescale continual adaptation phase. Moreover, we find that the loss of plasticity is strongly associated with the change in label flip. Based on this correlation, we propose a simple yet effective policy, Adaptive Shrink-Restore (ASR), towards preserving the model's plasticity. In particular, ASR does the weight re-initialization by the adaptive intervals. The adaptive interval is determined based on the change in label flipping. Our method is validated on extensive CTTA benchmarks, achieving excellent performance.
DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Monocular Dynamic 3D Reconstruction
Dec 05, 2024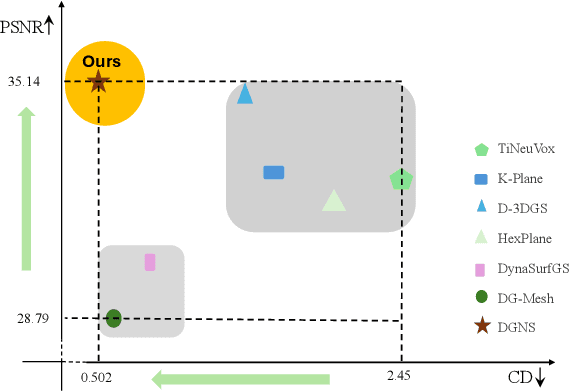
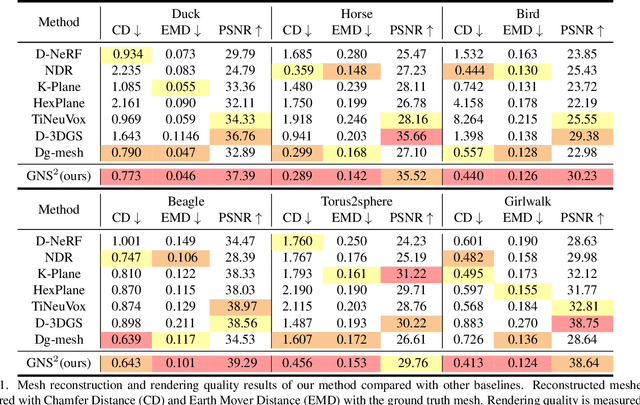

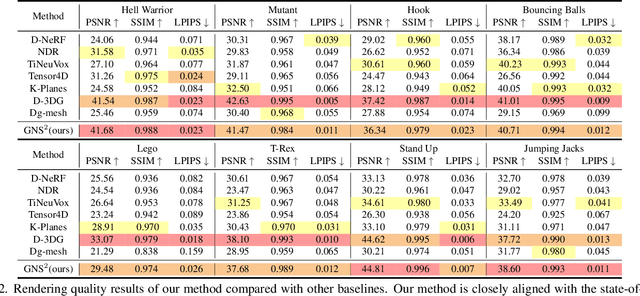
Dynamic scene reconstruction from monocular video is critical for real-world applications. This paper tackles the dual challenges of dynamic novel-view synthesis and 3D geometry reconstruction by introducing a hybrid framework: Deformable Gaussian Splatting and Dynamic Neural Surfaces (DGNS), in which both modules can leverage each other for both tasks. During training, depth maps generated by the deformable Gaussian splatting module guide the ray sampling for faster processing and provide depth supervision within the dynamic neural surface module to improve geometry reconstruction. Simultaneously, the dynamic neural surface directs the distribution of Gaussian primitives around the surface, enhancing rendering quality. To further refine depth supervision, we introduce a depth-filtering process on depth maps derived from Gaussian rasterization. Extensive experiments on public datasets demonstrate that DGNS achieves state-of-the-art performance in both novel-view synthesis and 3D reconstruction.
Viewpoint Consistency in 3D Generation via Attention and CLIP Guidance
Dec 03, 2024



Despite recent advances in text-to-3D generation techniques, current methods often suffer from geometric inconsistencies, commonly referred to as the Janus Problem. This paper identifies the root cause of the Janus Problem: viewpoint generation bias in diffusion models, which creates a significant gap between the actual generated viewpoint and the expected one required for optimizing the 3D model. To address this issue, we propose a tuning-free approach called the Attention and CLIP Guidance (ACG) mechanism. ACG enhances desired viewpoints by adaptively controlling cross-attention maps, employs CLIP-based view-text similarities to filter out erroneous viewpoints, and uses a coarse-to-fine optimization strategy with staged prompts to progressively refine 3D generation. Extensive experiments demonstrate that our method significantly reduces the Janus Problem without compromising generation speed, establishing ACG as an efficient, plug-and-play component for existing text-to-3D frameworks.
Latent-based Diffusion Model for Long-tailed Recognition
Apr 06, 2024Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
Backpropagation-free Network for 3D Test-time Adaptation
Mar 27, 2024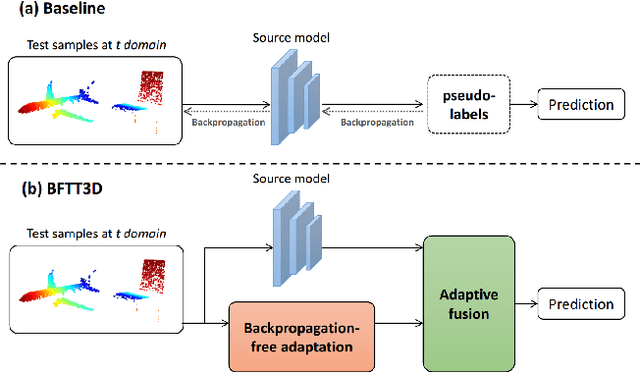
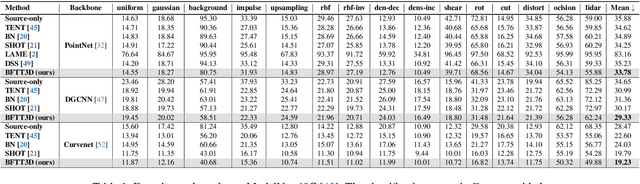
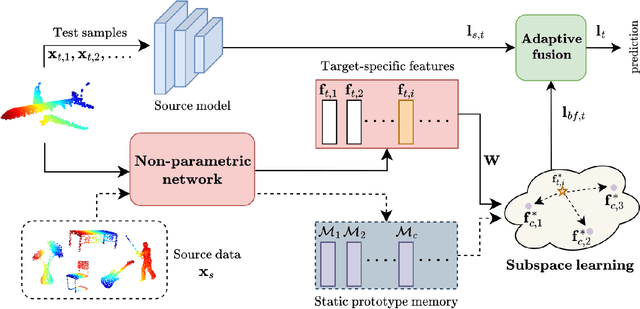
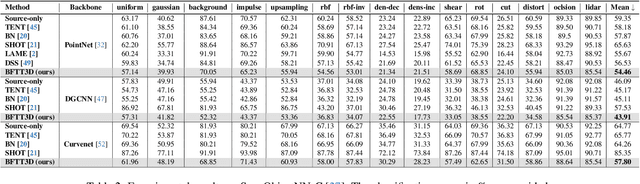
Real-world systems often encounter new data over time, which leads to experiencing target domain shifts. Existing Test-Time Adaptation (TTA) methods tend to apply computationally heavy and memory-intensive backpropagation-based approaches to handle this. Here, we propose a novel method that uses a backpropagation-free approach for TTA for the specific case of 3D data. Our model uses a two-stream architecture to maintain knowledge about the source domain as well as complementary target-domain-specific information. The backpropagation-free property of our model helps address the well-known forgetting problem and mitigates the error accumulation issue. The proposed method also eliminates the need for the usually noisy process of pseudo-labeling and reliance on costly self-supervised training. Moreover, our method leverages subspace learning, effectively reducing the distribution variance between the two domains. Furthermore, the source-domain-specific and the target-domain-specific streams are aligned using a novel entropy-based adaptive fusion strategy. Extensive experiments on popular benchmarks demonstrate the effectiveness of our method. The code will be available at https://github.com/abie-e/BFTT3D.