 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Closer to Ground Truth: A Multi-Scale Residual-Aware Representation Learning Pipeline for Predicting Time Series Data
Jun 09, 2026Transformer-based models have emerged as leading paradigms in time-series forecasting in recent years, employing self-attention mechanisms to capture long-range dependencies. Despite their success, these single-stage forecasting architectures exhibit persistent systematic residual biases arising from structural discrepancies, unmodeled stochastic components, or inadequate multi-scale temporal representations. This limitation persists when residuals are treated as irreducible noise, precluding adaptive correction of structured error patterns. To address this limitation, we introduce a two-stage, model-agnostic framework that explicitly decouples forecasting and residual learning into distinct stages of representation learning. A base transformer first generates the initial predictions. Subsequently, a dedicated meta-corrector dynamically models structured error patterns across multivariate channels, preserves cross-variable dependencies, and iteratively refines the residual bias of the base transformer. By formalizing this pipeline as a hypothesis space expansion, our framework addresses approximation limitations inherent in single-stage architectures, removes reliance on restrictive assumptions, and enables end-to-end learning of complex error dynamics. Evaluated on eight popular benchmark datasets using established protocols, our approach achieves state-of-the-art performance, with significant improvements in standard metrics (MSE, MAE). The results demonstrate the framework's ability to mitigate systematic biases and enhance robustness to complex temporal dynamics, advancing the practical applicability of transformer-based forecasting models.
HyperVis: Continuous Latent Visual Relational Graphs on the Lorentz Hyperboloid for Compositional Reasoning
Jun 04, 2026Vision-Language Models (VLMs) struggle with compositional reasoning that requires understanding inter-object relationships. A natural remedy is to inject explicit scene graph triplets $\langle s, p, o \rangle$ from an off-the-shelf scene graph generator (SGG), but we show this backfires: discrete text labels collide with the continuous visual modality, degrading GQA accuracy from 60.38\% to 58.86\%. We propose \textbf{HyperVis}, which bypasses the SGG semantic bottleneck entirely. From $N$ class-agnostic region proposals, we compute a dense $O(N^2)$ visual relation tensor via spatially-biased cross-attention, project it onto a Lorentz hyperboloid, and enforce hierarchy through spatial physics, namely IoA-driven entailment cones and exterior-angle repulsion. We discover that HyperVis contributes in two complementary ways: (1) as a \emph{training-time regularizer}, the hyperbolic relational losses shape LoRA representations that improve generative VQA (GQA 61.03\% vs.\ 57.21\% for LoRA fine-tuning without relational losses, recovering and surpassing the baseline); and (2) as an \emph{inference-time relational encoder}, hyperbolic prefix tokens boost discriminative compositional scoring (SugarCrepe 79.94\%, $+$6.25pp over baseline). The learned curvature stabilises at $κ{=}4.0$, an order of magnitude above prior hyperbolic VLMs where $κ$ typically collapses toward zero, indicating that continuous visual features genuinely require the exponential volume of strongly curved space. A controlled Euclidean ablation confirms this decomposition: the relational pipeline regularises LoRA comparably in flat space (GQA 60.81\%), but the compositionality gain is specifically hyperbolic (SugarCrepe $+$4.58pp over Euclidean), with entailment loss ${\sim}6{\times}$ higher in Euclidean training. Codes are available at TBA.
Beyond Real Weights: Hypercomplex Representations for Stable Quantization
Dec 09, 2025Multimodal language models (MLLMs) require large parameter capacity to align high-dimensional visual features with linguistic representations, making them computationally heavy and difficult to deploy efficiently. We introduce a progressive reparameterization strategy that compresses these models by gradually replacing dense feed-forward network blocks with compact Parameterized Hypercomplex Multiplication (PHM) layers. A residual interpolation schedule, together with lightweight reconstruction and knowledge distillation losses, ensures that the PHM modules inherit the functional behavior of their dense counterparts during training. This transition yields substantial parameter and FLOP reductions while preserving strong multimodal alignment, enabling faster inference without degrading output quality. We evaluate the approach on multiple vision-language models (VLMs). Our method maintains performance comparable to the base models while delivering significant reductions in model size and inference latency. Progressive PHM substitution thus offers an architecture-compatible path toward more efficient multimodal reasoning and complements existing low-bit quantization techniques.
Dynamic Temperature Scheduler for Knowledge Distillation
Nov 14, 2025Knowledge Distillation (KD) trains a smaller student model using a large, pre-trained teacher model, with temperature as a key hyperparameter controlling the softness of output probabilities. Traditional methods use a fixed temperature throughout training, which is suboptimal. Moreover, architectural differences between teacher and student often result in mismatched logit magnitudes. We demonstrate that students benefit from softer probabilities early in training but require sharper probabilities in later stages. We introduce Dynamic Temperature Scheduler (DTS), which adjusts temperature dynamically based on the cross-entropy loss gap between teacher and student. To our knowledge, this is the first temperature scheduling method that adapts based on the divergence between teacher and student distributions. Our method integrates seamlessly with existing KD frameworks. We validate DTS across multiple KD strategies on vision (CIFAR-100, Tiny-ImageNet) and NLP tasks (GLUE, Dolly, SelfIns, UnNI, S-NI), consistently outperforming static-temperature baselines. Code is available at https://github.com/Sibgat-Ul/DTS.
LAET: A Layer-wise Adaptive Ensemble Tuning Framework for Pretrained Language Models
Nov 14, 2025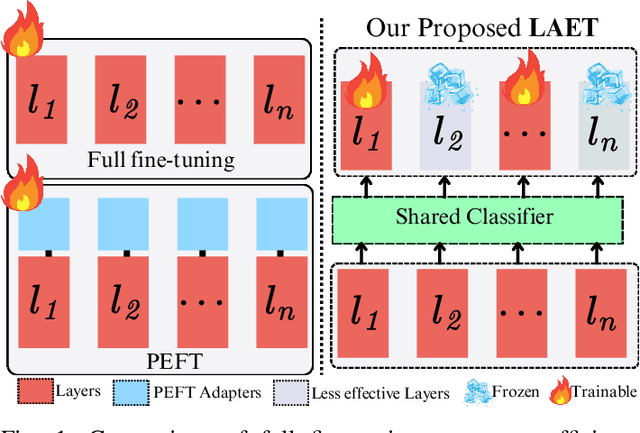
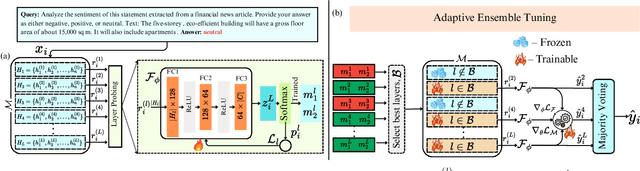
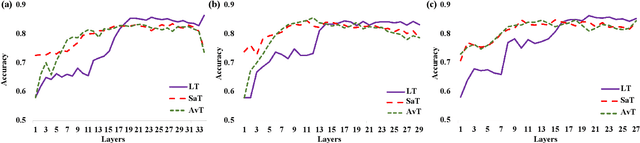
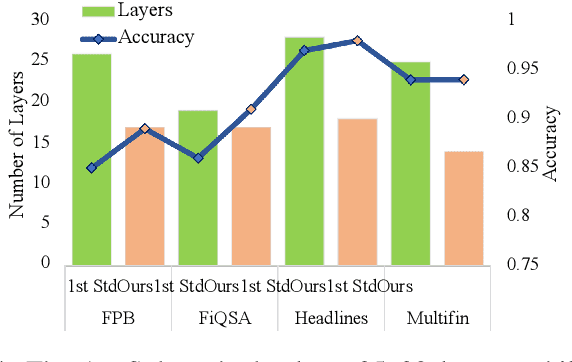
Natural Language Processing (NLP) has transformed the financial industry, enabling advancements in areas such as textual analysis, risk management, and forecasting. Large language models (LLMs) like BloombergGPT and FinMA have set new benchmarks across various financial NLP tasks, including sentiment analysis, stock movement prediction, and credit risk assessment. Furthermore, FinMA-ES, a bilingual financial LLM, has also demonstrated strong performance using the FLARE and FLARE-ES benchmarks. However, the high computational demands of these models limit the accessibility of many organizations. To address this, we propose Layer-wise Adaptive Ensemble Tuning (LAET), a novel strategy that selectively fine-tunes the most effective layers of pre-trained LLMs by analyzing hidden state representations while freezing less critical layers. LAET significantly reduces computational overhead while enhancing task-specific performance. Our approach shows strong results in financial NLP tasks, outperforming existing benchmarks and state-of-the-art LLMs such as GPT-4, even with smaller LLMs ($\sim$3B parameters). This work bridges cutting-edge financial NLP research and real-world deployment with efficient and scalable models for financial applications.
LegalRAG: A Hybrid RAG System for Multilingual Legal Information Retrieval
Apr 19, 2025Natural Language Processing (NLP) and computational linguistic techniques are increasingly being applied across various domains, yet their use in legal and regulatory tasks remains limited. To address this gap, we develop an efficient bilingual question-answering framework for regulatory documents, specifically the Bangladesh Police Gazettes, which contain both English and Bangla text. Our approach employs modern Retrieval Augmented Generation (RAG) pipelines to enhance information retrieval and response generation. In addition to conventional RAG pipelines, we propose an advanced RAG-based approach that improves retrieval performance, leading to more precise answers. This system enables efficient searching for specific government legal notices, making legal information more accessible. We evaluate both our proposed and conventional RAG systems on a diverse test set on Bangladesh Police Gazettes, demonstrating that our approach consistently outperforms existing methods across all evaluation metrics.
Tabular foundation model to detect empathy from visual cues
Apr 15, 2025Detecting empathy from video interactions is an emerging area of research. Video datasets, however, are often released as extracted features (i.e., tabular data) rather than raw footage due to privacy and ethical concerns. Prior research on such tabular datasets established tree-based classical machine learning approaches as the best-performing models. Motivated by the recent success of textual foundation models (i.e., large language models), we explore the use of tabular foundation models in empathy detection from tabular visual features. We experiment with two recent tabular foundation models $-$ TabPFN v2 and TabICL $-$ through in-context learning and fine-tuning setups. Our experiments on a public human-robot interaction benchmark demonstrate a significant boost in cross-subject empathy detection accuracy over several strong baselines (accuracy: $0.590 \rightarrow 0.730$; AUC: $0.564 \rightarrow 0.669$). In addition to performance improvement, we contribute novel insights and an evaluation setup to ensure generalisation on unseen subjects in this public benchmark. As the practice of releasing video features as tabular datasets is likely to persist due to privacy constraints, our findings will be widely applicable to future empathy detection video datasets as well.
Labels Generated by Large Language Model Helps Measuring People's Empathy in Vitro
Jan 01, 2025Large language models (LLMs) have revolutionised numerous fields, with LLM-as-a-service (LLMSaaS) having a strong generalisation ability that offers accessible solutions directly without the need for costly training. In contrast to the widely studied prompt engineering for task solving directly (in vivo), this paper explores its potential in in-vitro applications. These involve using LLM to generate labels to help the supervised training of mainstream models by (1) noisy label correction and (2) training data augmentation with LLM-generated labels. In this paper, we evaluate this approach in the emerging field of empathy computing -- automating the prediction of psychological questionnaire outcomes from inputs like text sequences. Specifically, crowdsourced datasets in this domain often suffer from noisy labels that misrepresent underlying empathy. By leveraging LLM-generated labels to train pre-trained language models (PLMs) like RoBERTa, we achieve statistically significant accuracy improvements over baselines, achieving a state-of-the-art Pearson correlation coefficient of 0.648 on NewsEmp benchmarks. In addition, we bring insightful discussions, including current challenges in empathy computing, data biases in training data and evaluation metric selection. Code and LLM-generated data are available at https://github.com/hasan-rakibul/LLMPathy (available once the paper is accepted).
VideoLights: Feature Refinement and Cross-Task Alignment Transformer for Joint Video Highlight Detection and Moment Retrieval
Dec 02, 2024Video Highlight Detection and Moment Retrieval (HD/MR) are essential in video analysis. Recent joint prediction transformer models often overlook their cross-task dynamics and video-text alignment and refinement. Moreover, most models typically use limited, uni-directional attention mechanisms, resulting in weakly integrated representations and suboptimal performance in capturing the interdependence between video and text modalities. Although large-language and vision-language models (LLM/LVLMs) have gained prominence across various domains, their application in this field remains relatively underexplored. Here we propose VideoLights, a novel HD/MR framework addressing these limitations through (i) Convolutional Projection and Feature Refinement modules with an alignment loss for better video-text feature alignment, (ii) Bi-Directional Cross-Modal Fusion network for strongly coupled query-aware clip representations, and (iii) Uni-directional joint-task feedback mechanism enhancing both tasks through correlation. In addition, (iv) we introduce hard positive/negative losses for adaptive error penalization and improved learning, and (v) leverage LVLMs like BLIP-2 for enhanced multimodal feature integration and intelligent pretraining using synthetic data generated from LVLMs. Comprehensive experiments on QVHighlights, TVSum, and Charades-STA benchmarks demonstrate state-of-the-art performance. Codes and models are available at https://github.com/dpaul06/VideoLights .
Test-Time Adaptation of 3D Point Clouds via Denoising Diffusion Models
Nov 21, 2024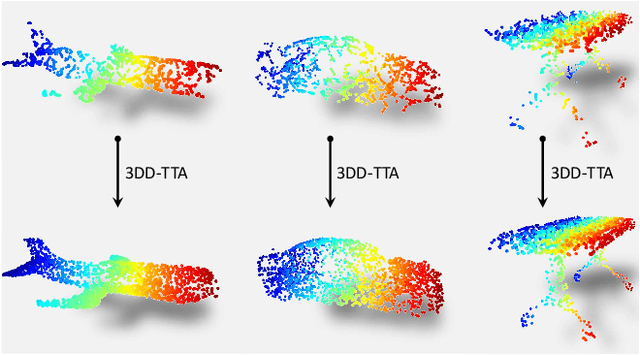
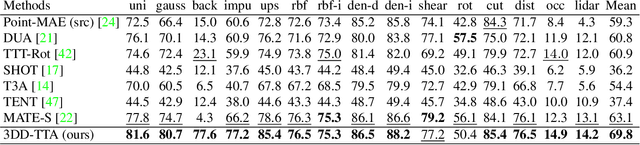
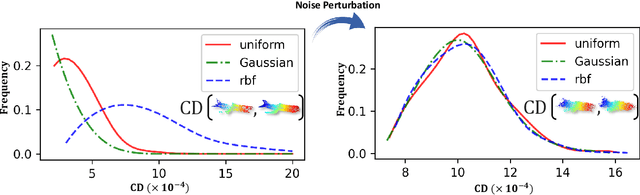
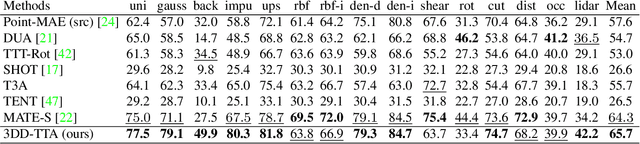
Test-time adaptation (TTA) of 3D point clouds is crucial for mitigating discrepancies between training and testing samples in real-world scenarios, particularly when handling corrupted point clouds. LiDAR data, for instance, can be affected by sensor failures or environmental factors, causing domain gaps. Adapting models to these distribution shifts online is crucial, as training for every possible variation is impractical. Existing methods often focus on fine-tuning pre-trained models based on self-supervised learning or pseudo-labeling, which can lead to forgetting valuable source domain knowledge over time and reduce generalization on future tests. In this paper, we introduce a novel 3D test-time adaptation method, termed 3DD-TTA, which stands for 3D Denoising Diffusion Test-Time Adaptation. This method uses a diffusion strategy that adapts input point cloud samples to the source domain while keeping the source model parameters intact. The approach uses a Variational Autoencoder (VAE) to encode the corrupted point cloud into a shape latent and latent points. These latent points are corrupted with Gaussian noise and subjected to a denoising diffusion process. During this process, both the shape latent and latent points are updated to preserve fidelity, guiding the denoising toward generating consistent samples that align more closely with the source domain. We conduct extensive experiments on the ShapeNet dataset and investigate its generalizability on ModelNet40 and ScanObjectNN, achieving state-of-the-art results. The code has been released at \url{https://github.com/hamidreza-dastmalchi/3DD-TTA}.