 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Non-Monolithic Policy Approach of Offline-to-Online Reinforcement Learning
Oct 31, 2024Offline-to-online reinforcement learning (RL) leverages both pre-trained offline policies and online policies trained for downstream tasks, aiming to improve data efficiency and accelerate performance enhancement. An existing approach, Policy Expansion (PEX), utilizes a policy set composed of both policies without modifying the offline policy for exploration and learning. However, this approach fails to ensure sufficient learning of the online policy due to an excessive focus on exploration with both policies. Since the pre-trained offline policy can assist the online policy in exploiting a downstream task based on its prior experience, it should be executed effectively and tailored to the specific requirements of the downstream task. In contrast, the online policy, with its immature behavioral strategy, has the potential for exploration during the training phase. Therefore, our research focuses on harmonizing the advantages of the offline policy, termed exploitation, with those of the online policy, referred to as exploration, without modifying the offline policy. In this study, we propose an innovative offline-to-online RL method that employs a non-monolithic exploration approach. Our methodology demonstrates superior performance compared to PEX.
Foundation Model-Powered 3D Few-Shot Class Incremental Learning via Training-free Adaptor
Oct 11, 2024Recent advances in deep learning for processing point clouds hold increased interest in Few-Shot Class Incremental Learning (FSCIL) for 3D computer vision. This paper introduces a new method to tackle the Few-Shot Continual Incremental Learning (FSCIL) problem in 3D point cloud environments. We leverage a foundational 3D model trained extensively on point cloud data. Drawing from recent improvements in foundation models, known for their ability to work well across different tasks, we propose a novel strategy that does not require additional training to adapt to new tasks. Our approach uses a dual cache system: first, it uses previous test samples based on how confident the model was in its predictions to prevent forgetting, and second, it includes a small number of new task samples to prevent overfitting. This dynamic adaptation ensures strong performance across different learning tasks without needing lots of fine-tuning. We tested our approach on datasets like ModelNet, ShapeNet, ScanObjectNN, and CO3D, showing that it outperforms other FSCIL methods and demonstrating its effectiveness and versatility. The code is available at \url{https://github.com/ahmadisahar/ACCV_FCIL3D}.
Decoupling Exploration and Exploitation for Unsupervised Pre-training with Successor Features
May 04, 2024Unsupervised pre-training has been on the lookout for the virtue of a value function representation referred to as successor features (SFs), which decouples the dynamics of the environment from the rewards. It has a significant impact on the process of task-specific fine-tuning due to the decomposition. However, existing approaches struggle with local optima due to the unified intrinsic reward of exploration and exploitation without considering the linear regression problem and the discriminator supporting a small skill sapce. We propose a novel unsupervised pre-training model with SFs based on a non-monolithic exploration methodology. Our approach pursues the decomposition of exploitation and exploration of an agent built on SFs, which requires separate agents for the respective purpose. The idea will leverage not only the inherent characteristics of SFs such as a quick adaptation to new tasks but also the exploratory and task-agnostic capabilities. Our suggested model is termed Non-Monolithic unsupervised Pre-training with Successor features (NMPS), which improves the performance of the original monolithic exploration method of pre-training with SFs. NMPS outperforms Active Pre-training with Successor Features (APS) in a comparative experiment.
An Autonomous Non-monolithic Agent with Multi-mode Exploration based on Options Framework
May 04, 2023Most exploration research on reinforcement learning (RL) has paid attention to `the way of exploration', which is `how to explore'. The other exploration research, `when to explore', has not been the main focus of RL exploration research. The issue of `when' of a monolithic exploration in the usual RL exploration behaviour binds an exploratory action to an exploitational action of an agent. Recently, a non-monolithic exploration research has emerged to examine the mode-switching exploration behaviour of humans and animals. The ultimate purpose of our research is to enable an agent to decide when to explore or exploit autonomously. We describe the initial research of an autonomous multi-mode exploration of non-monolithic behaviour in an options framework. The higher performance of our method is shown against the existing non-monolithic exploration method through comparative experimental results.
CDRec: Cayley-Dickson Recommender
Jan 14, 2022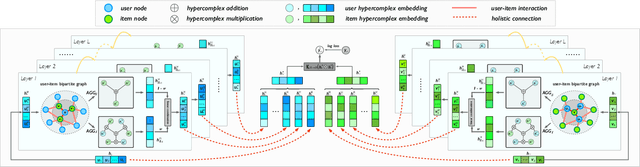


In this paper, we propose a recommendation framework named Cayley-Dickson Recommender. We introduce Cayley-Dickson construction which uses a recursive process to define hypercomplex algebras and their mathematical operations. We also design a graph convolution operator to learn representations in the hypercomplex space. To the best of our knowledge, it is the first time that Cayley-Dickson construction and graph convolution techniques have been used in hypercomplex recommendation. Compared with the state-of-the-art recommendation methods, our method achieves superior performance on real-world datasets.
Hierarchical Reinforcement Learning with Optimal Level Synchronization based on a Deep Generative Model
Jul 17, 2021
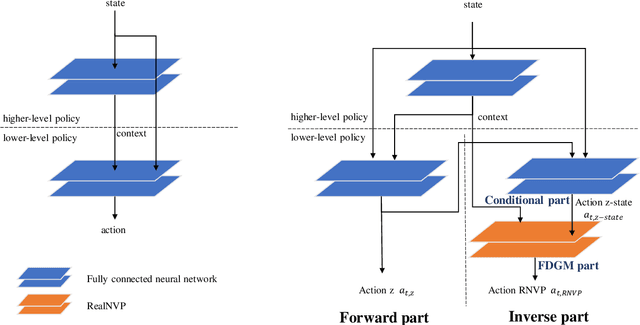
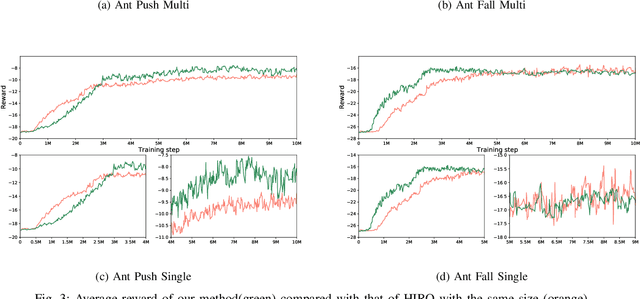
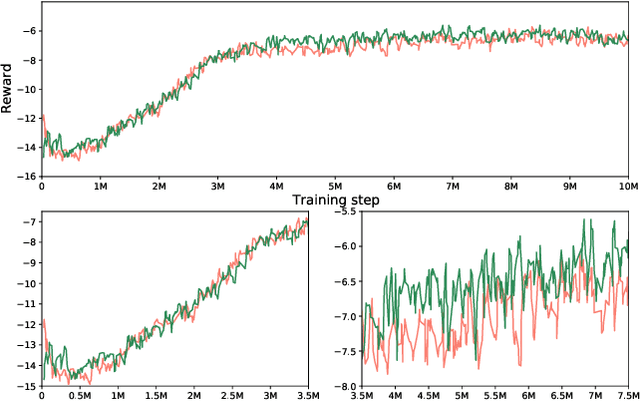
The high-dimensional or sparse reward task of a reinforcement learning (RL) environment requires a superior potential controller such as hierarchical reinforcement learning (HRL) rather than an atomic RL because it absorbs the complexity of commands to achieve the purpose of the task in its hierarchical structure. One of the HRL issues is how to train each level policy with the optimal data collection from its experience. That is to say, how to synchronize adjacent level policies optimally. Our research finds that a HRL model through the off-policy correction technique of HRL, which trains a higher-level policy with the goal of reflecting a lower-level policy which is newly trained using the off-policy method, takes the critical role of synchronizing both level policies at all times while they are being trained. We propose a novel HRL model supporting the optimal level synchronization using the off-policy correction technique with a deep generative model. This uses the advantage of the inverse operation of a flow-based deep generative model (FDGM) to achieve the goal corresponding to the current state of the lower-level policy. The proposed model also considers the freedom of the goal dimension between HRL policies which makes it the generalized inverse model of the model-free RL in HRL with the optimal synchronization method. The comparative experiment results show the performance of our proposed model.