 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGAS: Value-Guided Action-Chunk Selection for Few-Shot Vision-Language-Action Adaptation
Feb 07, 2026Vision--Language--Action (VLA) models bridge multimodal reasoning with physical control, but adapting them to new tasks with scarce demonstrations remains unreliable. While fine-tuned VLA policies often produce semantically plausible trajectories, failures often arise from unresolved geometric ambiguities, where near-miss action candidates lead to divergent execution outcomes under limited supervision. We study few-shot VLA adaptation from a \emph{generation--selection} perspective and propose a novel framework \textbf{VGAS} (\textbf{V}alue-\textbf{G}uided \textbf{A}ction-chunk \textbf{S}election). It performs inference-time best-of-$N$ selection to identify action chunks that are both semantically faithful and geometrically precise. Specifically, \textbf{VGAS} employs a finetuned VLA as a high-recall proposal generator and introduces the \textrm{Q-Chunk-Former}, a geometrically grounded Transformer critic to resolve fine-grained geometric ambiguities. In addition, we propose \textit{Explicit Geometric Regularization} (\texttt{EGR}), which explicitly shapes a discriminative value landscape to preserve action ranking resolution among near-miss candidates while mitigating value instability under scarce supervision. Experiments and theoretical analysis demonstrate that \textbf{VGAS} consistently improves success rates and robustness under limited demonstrations and distribution shifts. Our code is available at https://github.com/Jyugo-15/VGAS.
Bandwidth-constrained Variational Message Encoding for Cooperative Multi-agent Reinforcement Learning
Dec 11, 2025Graph-based multi-agent reinforcement learning (MARL) enables coordinated behavior under partial observability by modeling agents as nodes and communication links as edges. While recent methods excel at learning sparse coordination graphs-determining who communicates with whom-they do not address what information should be transmitted under hard bandwidth constraints. We study this bandwidth-limited regime and show that naive dimensionality reduction consistently degrades coordination performance. Hard bandwidth constraints force selective encoding, but deterministic projections lack mechanisms to control how compression occurs. We introduce Bandwidth-constrained Variational Message Encoding (BVME), a lightweight module that treats messages as samples from learned Gaussian posteriors regularized via KL divergence to an uninformative prior. BVME's variational framework provides principled, tunable control over compression strength through interpretable hyperparameters, directly constraining the representations used for decision-making. Across SMACv1, SMACv2, and MPE benchmarks, BVME achieves comparable or superior performance while using 67--83% fewer message dimensions, with gains most pronounced on sparse graphs where message quality critically impacts coordination. Ablations reveal U-shaped sensitivity to bandwidth, with BVME excelling at extreme ratios while adding minimal overhead.
A Non-Monolithic Policy Approach of Offline-to-Online Reinforcement Learning
Oct 31, 2024Offline-to-online reinforcement learning (RL) leverages both pre-trained offline policies and online policies trained for downstream tasks, aiming to improve data efficiency and accelerate performance enhancement. An existing approach, Policy Expansion (PEX), utilizes a policy set composed of both policies without modifying the offline policy for exploration and learning. However, this approach fails to ensure sufficient learning of the online policy due to an excessive focus on exploration with both policies. Since the pre-trained offline policy can assist the online policy in exploiting a downstream task based on its prior experience, it should be executed effectively and tailored to the specific requirements of the downstream task. In contrast, the online policy, with its immature behavioral strategy, has the potential for exploration during the training phase. Therefore, our research focuses on harmonizing the advantages of the offline policy, termed exploitation, with those of the online policy, referred to as exploration, without modifying the offline policy. In this study, we propose an innovative offline-to-online RL method that employs a non-monolithic exploration approach. Our methodology demonstrates superior performance compared to PEX.
Functional Stochastic Gradient MCMC for Bayesian Neural Networks
Sep 25, 2024



Classical variational inference for Bayesian neural networks (BNNs) in parameter space usually suffers from unresolved prior issues such as knowledge encoding intractability and pathological behaviors in deep networks, which could lead to an improper posterior inference. Hence, functional variational inference has been proposed recently to resolve these issues via stochastic process priors. Beyond variational inference, stochastic gradient Markov Chain Monte Carlo (SGMCMC) is another scalable and effective inference method for BNNs to asymptotically generate samples from true posterior by simulating a continuous dynamic. However, the existing SGMCMC methods only work in parametric space, which has the same issues of parameter-space variational inference, and extending the parameter-space dynamics to function-space dynamics is not a trivial undertaking. In this paper, we introduce a new functional SGMCMC scheme via newly designed diffusion dynamics, which can incorporate more informative functional priors. Moreover, we prove that the stationary distribution of these functional dynamics is the target posterior distribution over functions. We demonstrate better performance in both accuracy and uncertainty quantification of our functional SGMCMC on several tasks compared with naive SGMCMC and functional variational inference methods.
LSTM Autoencoder-based Deep Neural Networks for Barley Genotype-to-Phenotype Prediction
Jul 21, 2024Artificial Intelligence (AI) has emerged as a key driver of precision agriculture, facilitating enhanced crop productivity, optimized resource use, farm sustainability, and informed decision-making. Also, the expansion of genome sequencing technology has greatly increased crop genomic resources, deepening our understanding of genetic variation and enhancing desirable crop traits to optimize performance in various environments. There is increasing interest in using machine learning (ML) and deep learning (DL) algorithms for genotype-to-phenotype prediction due to their excellence in capturing complex interactions within large, high-dimensional datasets. In this work, we propose a new LSTM autoencoder-based model for barley genotype-to-phenotype prediction, specifically for flowering time and grain yield estimation, which could potentially help optimize yields and management practices. Our model outperformed the other baseline methods, demonstrating its potential in handling complex high-dimensional agricultural datasets and enhancing crop phenotype prediction performance.
A Behavior-Aware Approach for Deep Reinforcement Learning in Non-stationary Environments without Known Change Points
May 23, 2024Deep reinforcement learning is used in various domains, but usually under the assumption that the environment has stationary conditions like transitions and state distributions. When this assumption is not met, performance suffers. For this reason, tracking continuous environmental changes and adapting to unpredictable conditions is challenging yet crucial because it ensures that systems remain reliable and flexible in practical scenarios. Our research introduces Behavior-Aware Detection and Adaptation (BADA), an innovative framework that merges environmental change detection with behavior adaptation. The key inspiration behind our method is that policies exhibit different global behaviors in changing environments. Specifically, environmental changes are identified by analyzing variations between behaviors using Wasserstein distances without manually set thresholds. The model adapts to the new environment through behavior regularization based on the extent of changes. The results of a series of experiments demonstrate better performance relative to several current algorithms. This research also indicates significant potential for tackling this long-standing challenge.
Decoupling Exploration and Exploitation for Unsupervised Pre-training with Successor Features
May 04, 2024Unsupervised pre-training has been on the lookout for the virtue of a value function representation referred to as successor features (SFs), which decouples the dynamics of the environment from the rewards. It has a significant impact on the process of task-specific fine-tuning due to the decomposition. However, existing approaches struggle with local optima due to the unified intrinsic reward of exploration and exploitation without considering the linear regression problem and the discriminator supporting a small skill sapce. We propose a novel unsupervised pre-training model with SFs based on a non-monolithic exploration methodology. Our approach pursues the decomposition of exploitation and exploration of an agent built on SFs, which requires separate agents for the respective purpose. The idea will leverage not only the inherent characteristics of SFs such as a quick adaptation to new tasks but also the exploratory and task-agnostic capabilities. Our suggested model is termed Non-Monolithic unsupervised Pre-training with Successor features (NMPS), which improves the performance of the original monolithic exploration method of pre-training with SFs. NMPS outperforms Active Pre-training with Successor Features (APS) in a comparative experiment.
Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
Apr 17, 2024Cooperative Multi-Agent Reinforcement Learning (MARL) necessitates seamless collaboration among agents, often represented by an underlying relation graph. Existing methods for learning this graph primarily focus on agent-pair relations, neglecting higher-order relationships. While several approaches attempt to extend cooperation modelling to encompass behaviour similarities within groups, they commonly fall short in concurrently learning the latent graph, thereby constraining the information exchange among partially observed agents. To overcome these limitations, we present a novel approach to infer the Group-Aware Coordination Graph (GACG), which is designed to capture both the cooperation between agent pairs based on current observations and group-level dependencies from behaviour patterns observed across trajectories. This graph is further used in graph convolution for information exchange between agents during decision-making. To further ensure behavioural consistency among agents within the same group, we introduce a group distance loss, which promotes group cohesion and encourages specialization between groups. Our evaluations, conducted on StarCraft II micromanagement tasks, demonstrate GACG's superior performance. An ablation study further provides experimental evidence of the effectiveness of each component of our method.
Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Mar 28, 2024

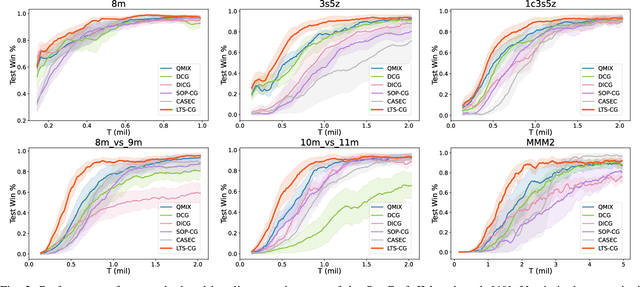

Effective agent coordination is crucial in cooperative Multi-Agent Reinforcement Learning (MARL). While agent cooperation can be represented by graph structures, prevailing graph learning methods in MARL are limited. They rely solely on one-step observations, neglecting crucial historical experiences, leading to deficient graphs that foster redundant or detrimental information exchanges. Additionally, high computational demands for action-pair calculations in dense graphs impede scalability. To address these challenges, we propose inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for MARL. The LTS-CG leverages agents' historical observations to calculate an agent-pair probability matrix, where a sparse graph is sampled from and used for knowledge exchange between agents, thereby simultaneously capturing agent dependencies and relation uncertainty. The computational complexity of this procedure is only related to the number of agents. This graph learning process is further augmented by two innovative characteristics: Predict-Future, which enables agents to foresee upcoming observations, and Infer-Present, ensuring a thorough grasp of the environmental context from limited data. These features allow LTS-CG to construct temporal graphs from historical and real-time information, promoting knowledge exchange during policy learning and effective collaboration. Graph learning and agent training occur simultaneously in an end-to-end manner. Our demonstrated results on the StarCraft II benchmark underscore LTS-CG's superior performance.
Layer-diverse Negative Sampling for Graph Neural Networks
Mar 18, 2024



Graph neural networks (GNNs) are a powerful solution for various structure learning applications due to their strong representation capabilities for graph data. However, traditional GNNs, relying on message-passing mechanisms that gather information exclusively from first-order neighbours (known as positive samples), can lead to issues such as over-smoothing and over-squashing. To mitigate these issues, we propose a layer-diverse negative sampling method for message-passing propagation. This method employs a sampling matrix within a determinantal point process, which transforms the candidate set into a space and selectively samples from this space to generate negative samples. To further enhance the diversity of the negative samples during each forward pass, we develop a space-squeezing method to achieve layer-wise diversity in multi-layer GNNs. Experiments on various real-world graph datasets demonstrate the effectiveness of our approach in improving the diversity of negative samples and overall learning performance. Moreover, adding negative samples dynamically changes the graph's topology, thus with the strong potential to improve the expressiveness of GNNs and reduce the risk of over-squashing.