 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Aspect Knowledge Distillation for Language Model with Low-rank Factorization
Apr 03, 2026Knowledge distillation is an effective technique for pre-trained language model compression. However, existing methods only focus on the knowledge distribution among layers, which may cause the loss of fine-grained information in the alignment process. To address this issue, we introduce the Multi-aspect Knowledge Distillation (MaKD) method, which mimics the self-attention and feed-forward modules in greater depth to capture rich language knowledge information at different aspects. Experimental results demonstrate that MaKD can achieve competitive performance compared with various strong baselines with the same storage parameter budget. In addition, our method also performs well in distilling auto-regressive architecture models.
AutoTour: Automatic Photo Tour Guide with Smartphones and LLMs
Jan 11, 2026We present AutoTour, a system that enhances user exploration by automatically generating fine-grained landmark annotations and descriptive narratives for photos captured by users. The key idea of AutoTour is to fuse visual features extracted from photos with nearby geospatial features queried from open matching databases. Unlike existing tour applications that rely on pre-defined content or proprietary datasets, AutoTour leverages open and extensible data sources to provide scalable and context-aware photo-based guidance. To achieve this, we design a training-free pipeline that first extracts and filters relevant geospatial features around the user's GPS location. It then detects major landmarks in user photos through VLM-based feature detection and projects them into the horizontal spatial plane. A geometric matching algorithm aligns photo features with corresponding geospatial entities based on their estimated distance and direction. The matched features are subsequently grounded and annotated directly on the original photo, accompanied by large language model-generated textual and audio descriptions to provide an informative, tour-like experience. We demonstrate that AutoTour can deliver rich, interpretable annotations for both iconic and lesser-known landmarks, enabling a new form of interactive, context-aware exploration that bridges visual perception and geospatial understanding.
Supervised and Unsupervised Neural Network Solver for First Order Hyperbolic Nonlinear PDEs
Jan 10, 2026We present a neural network-based method for learning scalar hyperbolic conservation laws. Our method replaces the traditional numerical flux in finite volume schemes with a trainable neural network while preserving the conservative structure of the scheme. The model can be trained both in a supervised setting with efficiently generated synthetic data or in an unsupervised manner, leveraging the weak formulation of the partial differential equation. We provide theoretical results that our model can perform arbitrarily well, and provide associated upper bounds on neural network size. Extensive experiments demonstrate that our method often outperforms efficient schemes such as Godunov's scheme, WENO, and Discontinuous Galerkin for comparable computational budgets. Finally, we demonstrate the effectiveness of our method on a traffic prediction task, leveraging field experimental highway data from the Berkeley DeepDrive drone dataset.
Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning
Aug 11, 2025Reinforcement learning for LLM reasoning has rapidly emerged as a prominent research area, marked by a significant surge in related studies on both algorithmic innovations and practical applications. Despite this progress, several critical challenges remain, including the absence of standardized guidelines for employing RL techniques and a fragmented understanding of their underlying mechanisms. Additionally, inconsistent experimental settings, variations in training data, and differences in model initialization have led to conflicting conclusions, obscuring the key characteristics of these techniques and creating confusion among practitioners when selecting appropriate techniques. This paper systematically reviews widely adopted RL techniques through rigorous reproductions and isolated evaluations within a unified open-source framework. We analyze the internal mechanisms, applicable scenarios, and core principles of each technique through fine-grained experiments, including datasets of varying difficulty, model sizes, and architectures. Based on these insights, we present clear guidelines for selecting RL techniques tailored to specific setups, and provide a reliable roadmap for practitioners navigating the RL for the LLM domain. Finally, we reveal that a minimalist combination of two techniques can unlock the learning capability of critic-free policies using vanilla PPO loss. The results demonstrate that our simple combination consistently improves performance, surpassing strategies like GRPO and DAPO.
Reinforcement Learning Optimization for Large-Scale Learning: An Efficient and User-Friendly Scaling Library
Jun 06, 2025We introduce ROLL, an efficient, scalable, and user-friendly library designed for Reinforcement Learning Optimization for Large-scale Learning. ROLL caters to three primary user groups: tech pioneers aiming for cost-effective, fault-tolerant large-scale training, developers requiring flexible control over training workflows, and researchers seeking agile experimentation. ROLL is built upon several key modules to serve these user groups effectively. First, a single-controller architecture combined with an abstraction of the parallel worker simplifies the development of the training pipeline. Second, the parallel strategy and data transfer modules enable efficient and scalable training. Third, the rollout scheduler offers fine-grained management of each sample's lifecycle during the rollout stage. Fourth, the environment worker and reward worker support rapid and flexible experimentation with agentic RL algorithms and reward designs. Finally, AutoDeviceMapping allows users to assign resources to different models flexibly across various stages.
Efficient Model Compression for Bayesian Neural Networks
Nov 01, 2024Model Compression has drawn much attention within the deep learning community recently. Compressing a dense neural network offers many advantages including lower computation cost, deployability to devices of limited storage and memories, and resistance to adversarial attacks. This may be achieved via weight pruning or fully discarding certain input features. Here we demonstrate a novel strategy to emulate principles of Bayesian model selection in a deep learning setup. Given a fully connected Bayesian neural network with spike-and-slab priors trained via a variational algorithm, we obtain the posterior inclusion probability for every node that typically gets lost. We employ these probabilities for pruning and feature selection on a host of simulated and real-world benchmark data and find evidence of better generalizability of the pruned model in all our experiments.
NGD converges to less degenerate solutions than SGD
Sep 07, 2024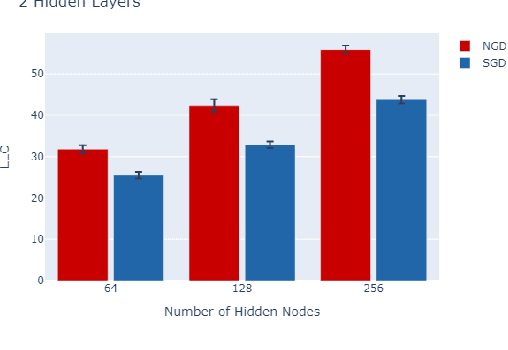
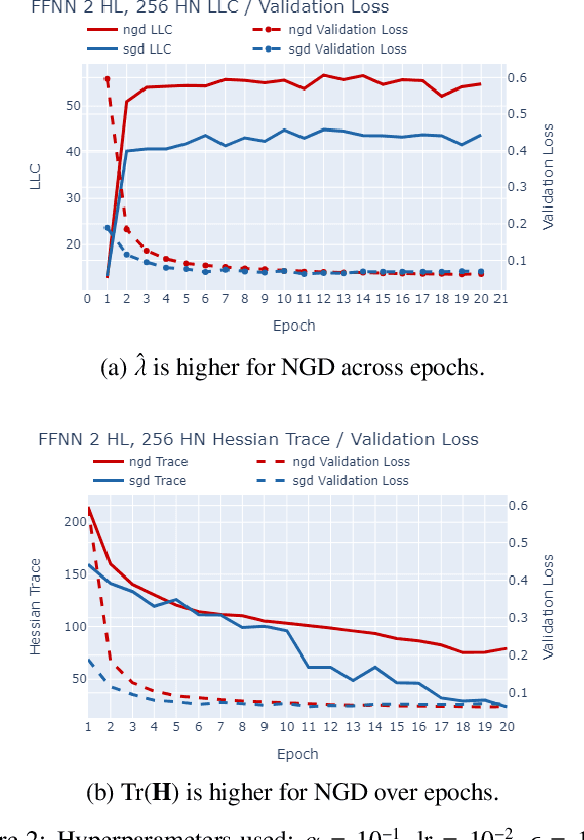
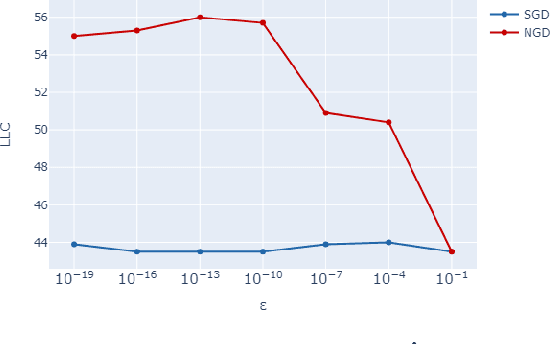
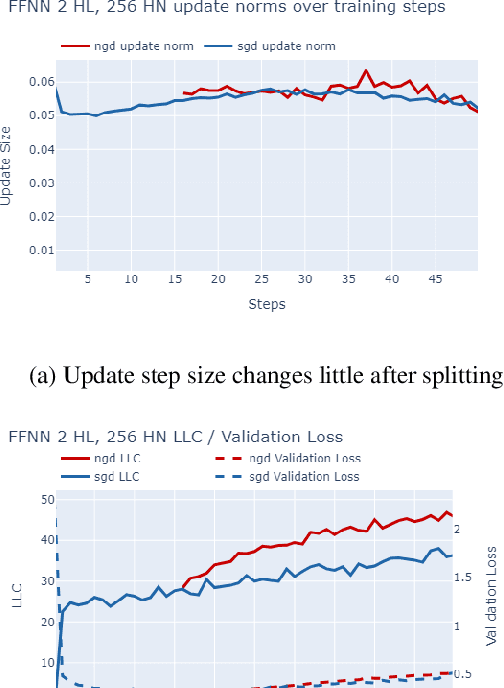
The number of free parameters, or dimension, of a model is a straightforward way to measure its complexity: a model with more parameters can encode more information. However, this is not an accurate measure of complexity: models capable of memorizing their training data often generalize well despite their high dimension. Effective dimension aims to more directly capture the complexity of a model by counting only the number of parameters required to represent the functionality of the model. Singular learning theory (SLT) proposes the learning coefficient $ \lambda $ as a more accurate measure of effective dimension. By describing the rate of increase of the volume of the region of parameter space around a local minimum with respect to loss, $ \lambda $ incorporates information from higher-order terms. We compare $ \lambda $ of models trained using natural gradient descent (NGD) and stochastic gradient descent (SGD), and find that those trained with NGD consistently have a higher effective dimension for both of our methods: the Hessian trace $ \text{Tr}(\mathbf{H}) $, and the estimate of the local learning coefficient (LLC) $ \hat{\lambda}(w^*) $.
A Behavior-Aware Approach for Deep Reinforcement Learning in Non-stationary Environments without Known Change Points
May 23, 2024Deep reinforcement learning is used in various domains, but usually under the assumption that the environment has stationary conditions like transitions and state distributions. When this assumption is not met, performance suffers. For this reason, tracking continuous environmental changes and adapting to unpredictable conditions is challenging yet crucial because it ensures that systems remain reliable and flexible in practical scenarios. Our research introduces Behavior-Aware Detection and Adaptation (BADA), an innovative framework that merges environmental change detection with behavior adaptation. The key inspiration behind our method is that policies exhibit different global behaviors in changing environments. Specifically, environmental changes are identified by analyzing variations between behaviors using Wasserstein distances without manually set thresholds. The model adapts to the new environment through behavior regularization based on the extent of changes. The results of a series of experiments demonstrate better performance relative to several current algorithms. This research also indicates significant potential for tackling this long-standing challenge.
Relation-aware Hierarchical Attention Framework for Video Question Answering
May 14, 2021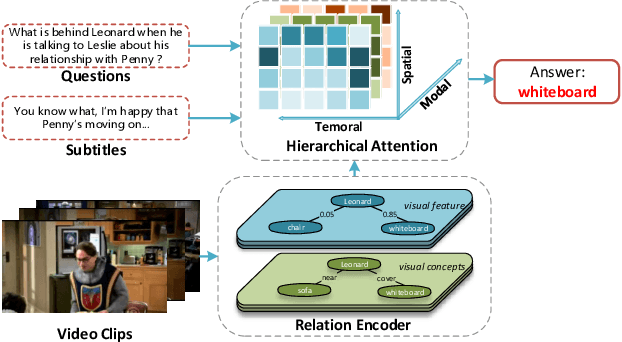
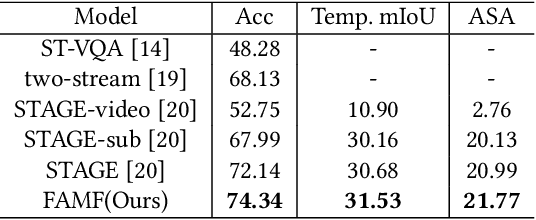
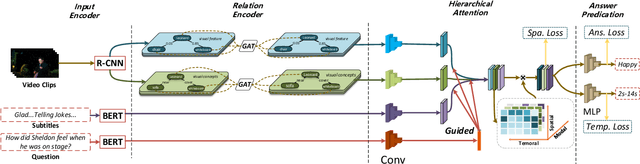
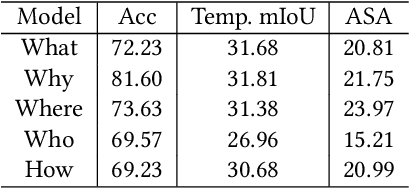
Video Question Answering (VideoQA) is a challenging video understanding task since it requires a deep understanding of both question and video. Previous studies mainly focus on extracting sophisticated visual and language embeddings, fusing them by delicate hand-crafted networks. However, the relevance of different frames, objects, and modalities to the question are varied along with the time, which is ignored in most of existing methods. Lacking understanding of the the dynamic relationships and interactions among objects brings a great challenge to VideoQA task. To address this problem, we propose a novel Relation-aware Hierarchical Attention (RHA) framework to learn both the static and dynamic relations of the objects in videos. In particular, videos and questions are embedded by pre-trained models firstly to obtain the visual and textual features. Then a graph-based relation encoder is utilized to extract the static relationship between visual objects. To capture the dynamic changes of multimodal objects in different video frames, we consider the temporal, spatial, and semantic relations, and fuse the multimodal features by hierarchical attention mechanism to predict the answer. We conduct extensive experiments on a large scale VideoQA dataset, and the experimental results demonstrate that our RHA outperforms the state-of-the-art methods.
Frame Aggregation and Multi-Modal Fusion Framework for Video-Based Person Recognition
Oct 19, 2020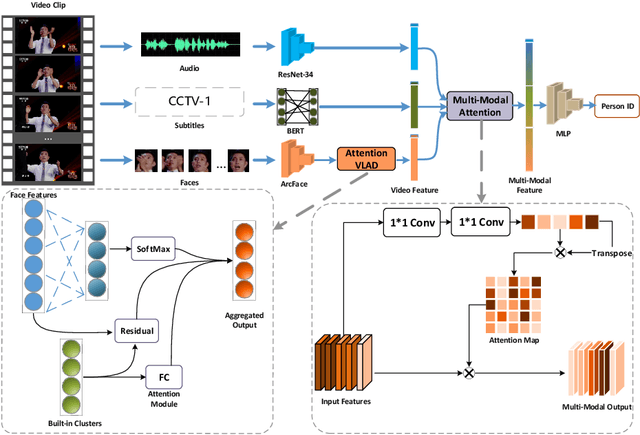
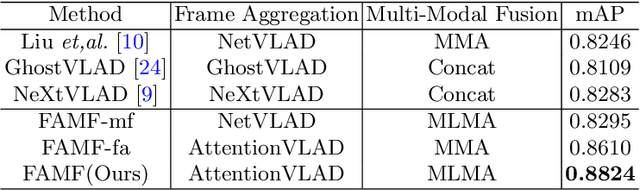

Video-based person recognition is challenging due to persons being blocked and blurred, and the variation of shooting angle. Previous research always focused on person recognition on still images, ignoring similarity and continuity between video frames. To tackle the challenges above, we propose a novel Frame Aggregation and Multi-Modal Fusion (FAMF) framework for video-based person recognition, which aggregates face features and incorporates them with multi-modal information to identify persons in videos. For frame aggregation, we propose a novel trainable layer based on NetVLAD (named AttentionVLAD), which takes arbitrary number of features as input and computes a fixed-length aggregation feature based on feature quality. We show that introducing an attention mechanism to NetVLAD can effectively decrease the impact of low-quality frames. For the multi-model information of videos, we propose a Multi-Layer Multi-Modal Attention (MLMA) module to learn the correlation of multi-modality by adaptively updating Gram matrix. Experimental results on iQIYI-VID-2019 dataset show that our framework outperforms other state-of-the-art methods.