 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Shortcuts: Facilitating Efficient Fusion in Multimodal Large Language Models
Jan 31, 2026With the remarkable success of large language models (LLMs) in natural language understanding and generation, multimodal large language models (MLLMs) have rapidly advanced in their ability to process data across multiple modalities. While most existing efforts focus on scaling up language models or constructing higher-quality training data, limited attention has been paid to effectively integrating cross-modal knowledge into the language space. In vision-language models, for instance, aligning modalities using only high-level visual features often discards the rich semantic information present in mid- and low-level features, limiting the model's ability of cross-modality understanding. To address this issue, we propose SparseCut, a general cross-modal fusion architecture for MLLMs, introducing sparse shortcut connections between the cross-modal encoder and the LLM. These shortcut connections enable the efficient and hierarchical integration of visual features at multiple levels, facilitating richer semantic fusion without increasing computational overhead. We further introduce an efficient multi-grained feature fusion module, which performs the fusion of visual features before routing them through the shortcuts. This preserves the original language context and does not increase the overall input length, thereby avoiding an increase in computational complexity for the LLM. Experiments demonstrate that SparseCut significantly enhances the performance of MLLMs across various multimodal benchmarks with generality and scalability for different base LLMs.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
PixelArena: A benchmark for Pixel-Precision Visual Intelligence
Dec 18, 2025


Multi-modal large language models that have image output are emerging. Many image generation benchmarks focus on aesthetics instead of fine-grained generation capabilities. In PixelArena, we propose using semantic segmentation tasks to objectively examine their fine-grained generative intelligence with pixel precision. We find the latest Gemini 3 Pro Image has emergent image generation capabilities that generate semantic masks with high fidelity under zero-shot settings, showcasing visual intelligence unseen before and true generalization in new image generation tasks. We further investigate its results, compare them qualitatively and quantitatively with those of other models, and present failure cases. The findings not only signal exciting progress in the field but also provide insights into future research related to multimodality, reasoning, interpretability and benchmarking.
Towards Explainable Quantum AI: Informing the Encoder Selection of Quantum Neural Networks via Visualization
Dec 16, 2025
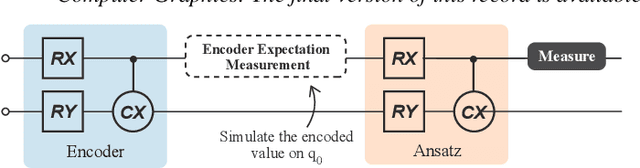
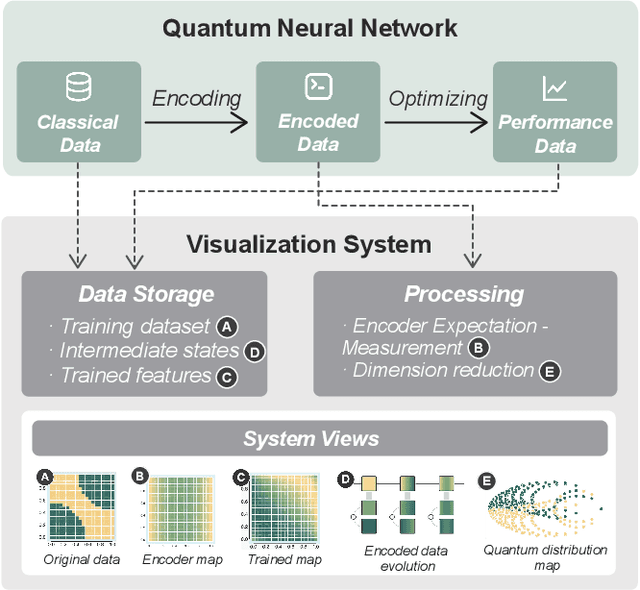
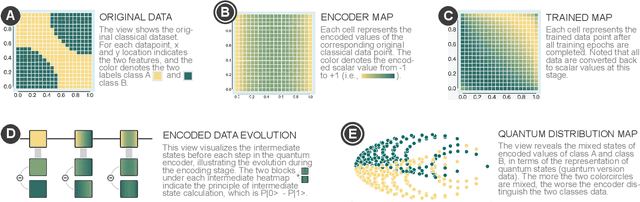
Quantum Neural Networks (QNNs) represent a promising fusion of quantum computing and neural network architectures, offering speed-ups and efficient processing of high-dimensional, entangled data. A crucial component of QNNs is the encoder, which maps classical input data into quantum states. However, choosing suitable encoders remains a significant challenge, largely due to the lack of systematic guidance and the trial-and-error nature of current approaches. This process is further impeded by two key challenges: (1) the difficulty in evaluating encoded quantum states prior to training, and (2) the lack of intuitive methods for analyzing an encoder's ability to effectively distinguish data features. To address these issues, we introduce a novel visualization tool, XQAI-Eyes, which enables QNN developers to compare classical data features with their corresponding encoded quantum states and to examine the mixed quantum states across different classes. By bridging classical and quantum perspectives, XQAI-Eyes facilitates a deeper understanding of how encoders influence QNN performance. Evaluations across diverse datasets and encoder designs demonstrate XQAI-Eyes's potential to support the exploration of the relationship between encoder design and QNN effectiveness, offering a holistic and transparent approach to optimizing quantum encoders. Moreover, domain experts used XQAI-Eyes to derive two key practices for quantum encoder selection, grounded in the principles of pattern preservation and feature mapping.
NeSTR: A Neuro-Symbolic Abductive Framework for Temporal Reasoning in Large Language Models
Dec 08, 2025Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, temporal reasoning, particularly under complex temporal constraints, remains a major challenge. To this end, existing approaches have explored symbolic methods, which encode temporal structure explicitly, and reflective mechanisms, which revise reasoning errors through multi-step inference. Nonetheless, symbolic approaches often underutilize the reasoning capabilities of LLMs, while reflective methods typically lack structured temporal representations, which can result in inconsistent or hallucinated reasoning. As a result, even when the correct temporal context is available, LLMs may still misinterpret or misapply time-related information, leading to incomplete or inaccurate answers. To address these limitations, in this work, we propose Neuro-Symbolic Temporal Reasoning (NeSTR), a novel framework that integrates structured symbolic representations with hybrid reflective reasoning to enhance the temporal sensitivity of LLM inference. NeSTR preserves explicit temporal relations through symbolic encoding, enforces logical consistency via verification, and corrects flawed inferences using abductive reflection. Extensive experiments on diverse temporal question answering benchmarks demonstrate that NeSTR achieves superior zero-shot performance and consistently improves temporal reasoning without any fine-tuning, showcasing the advantage of neuro-symbolic integration in enhancing temporal understanding in large language models.
FedSM: Robust Semantics-Guided Feature Mixup for Bias Reduction in Federated Learning with Long-Tail Data
Oct 31, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing private data. However, FL suffers from biased global models due to non-IID and long-tail data distributions. We propose \textbf{FedSM}, a novel client-centric framework that mitigates this bias through semantics-guided feature mixup and lightweight classifier retraining. FedSM uses a pretrained image-text-aligned model to compute category-level semantic relevance, guiding the category selection of local features to mix-up with global prototypes to generate class-consistent pseudo-features. These features correct classifier bias, especially when data are heavily skewed. To address the concern of potential domain shift between the pretrained model and the data, we propose probabilistic category selection, enhancing feature diversity to effectively mitigate biases. All computations are performed locally, requiring minimal server overhead. Extensive experiments on long-tail datasets with various imbalanced levels demonstrate that FedSM consistently outperforms state-of-the-art methods in accuracy, with high robustness to domain shift and computational efficiency.
Improved Immiscible Diffusion: Accelerate Diffusion Training by Reducing Its Miscibility
May 24, 2025The substantial training cost of diffusion models hinders their deployment. Immiscible Diffusion recently showed that reducing diffusion trajectory mixing in the noise space via linear assignment accelerates training by simplifying denoising. To extend immiscible diffusion beyond the inefficient linear assignment under high batch sizes and high dimensions, we refine this concept to a broader miscibility reduction at any layer and by any implementation. Specifically, we empirically demonstrate the bijective nature of the denoising process with respect to immiscible diffusion, ensuring its preservation of generative diversity. Moreover, we provide thorough analysis and show step-by-step how immiscibility eases denoising and improves efficiency. Extending beyond linear assignment, we propose a family of implementations including K-nearest neighbor (KNN) noise selection and image scaling to reduce miscibility, achieving up to >4x faster training across diverse models and tasks including unconditional/conditional generation, image editing, and robotics planning. Furthermore, our analysis of immiscibility offers a novel perspective on how optimal transport (OT) enhances diffusion training. By identifying trajectory miscibility as a fundamental bottleneck, we believe this work establishes a potentially new direction for future research into high-efficiency diffusion training. The code is available at https://github.com/yhli123/Immiscible-Diffusion.
3DM-WeConvene: Learned Image Compression with 3D Multi-Level Wavelet-Domain Convolution and Entropy Model
Apr 07, 2025



Learned image compression (LIC) has recently made significant progress, surpassing traditional methods. However, most LIC approaches operate mainly in the spatial domain and lack mechanisms for reducing frequency-domain correlations. To address this, we propose a novel framework that integrates low-complexity 3D multi-level Discrete Wavelet Transform (DWT) into convolutional layers and entropy coding, reducing both spatial and channel correlations to improve frequency selectivity and rate-distortion (R-D) performance. Our proposed 3D multi-level wavelet-domain convolution (3DM-WeConv) layer first applies 3D multi-level DWT (e.g., 5/3 and 9/7 wavelets from JPEG 2000) to transform data into the wavelet domain. Then, different-sized convolutions are applied to different frequency subbands, followed by inverse 3D DWT to restore the spatial domain. The 3DM-WeConv layer can be flexibly used within existing CNN-based LIC models. We also introduce a 3D wavelet-domain channel-wise autoregressive entropy model (3DWeChARM), which performs slice-based entropy coding in the 3D DWT domain. Low-frequency (LF) slices are encoded first to provide priors for high-frequency (HF) slices. A two-step training strategy is adopted: first balancing LF and HF rates, then fine-tuning with separate weights. Extensive experiments demonstrate that our framework consistently outperforms state-of-the-art CNN-based LIC methods in R-D performance and computational complexity, with larger gains for high-resolution images. On the Kodak, Tecnick 100, and CLIC test sets, our method achieves BD-Rate reductions of -12.24%, -15.51%, and -12.97%, respectively, compared to H.266/VVC.
Similarity Trajectories: Linking Sampling Process to Artifacts in Diffusion-Generated Images
Dec 22, 2024Artifact detection algorithms are crucial to correcting the output generated by diffusion models. However, because of the variety of artifact forms, existing methods require substantial annotated data for training. This requirement limits their scalability and efficiency, which restricts their wide application. This paper shows that the similarity of denoised images between consecutive time steps during the sampling process is related to the severity of artifacts in images generated by diffusion models. Building on this observation, we introduce the concept of Similarity Trajectory to characterize the sampling process and its correlation with the image artifacts presented. Using an annotated data set of 680 images, which is only 0.1% of the amount of data used in the prior work, we trained a classifier on these trajectories to predict the presence of artifacts in images. By performing 10-fold validation testing on the balanced annotated data set, the classifier can achieve an accuracy of 72.35%, highlighting the connection between the Similarity Trajectory and the occurrence of artifacts. This approach enables differentiation between artifact-exhibiting and natural-looking images using limited training data.
Efficient Model Compression for Bayesian Neural Networks
Nov 01, 2024Model Compression has drawn much attention within the deep learning community recently. Compressing a dense neural network offers many advantages including lower computation cost, deployability to devices of limited storage and memories, and resistance to adversarial attacks. This may be achieved via weight pruning or fully discarding certain input features. Here we demonstrate a novel strategy to emulate principles of Bayesian model selection in a deep learning setup. Given a fully connected Bayesian neural network with spike-and-slab priors trained via a variational algorithm, we obtain the posterior inclusion probability for every node that typically gets lost. We employ these probabilities for pruning and feature selection on a host of simulated and real-world benchmark data and find evidence of better generalizability of the pruned model in all our experiments.