 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition from Skeleton Data: A Comprehensive Survey
Jul 24, 2025Emotion recognition through body movements has emerged as a compelling and privacy-preserving alternative to traditional methods that rely on facial expressions or physiological signals. Recent advancements in 3D skeleton acquisition technologies and pose estimation algorithms have significantly enhanced the feasibility of emotion recognition based on full-body motion. This survey provides a comprehensive and systematic review of skeleton-based emotion recognition techniques. First, we introduce psychological models of emotion and examine the relationship between bodily movements and emotional expression. Next, we summarize publicly available datasets, highlighting the differences in data acquisition methods and emotion labeling strategies. We then categorize existing methods into posture-based and gait-based approaches, analyzing them from both data-driven and technical perspectives. In particular, we propose a unified taxonomy that encompasses four primary technical paradigms: Traditional approaches, Feat2Net, FeatFusionNet, and End2EndNet. Representative works within each category are reviewed and compared, with benchmarking results across commonly used datasets. Finally, we explore the extended applications of emotion recognition in mental health assessment, such as detecting depression and autism, and discuss the open challenges and future research directions in this rapidly evolving field.
Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
Jun 12, 2024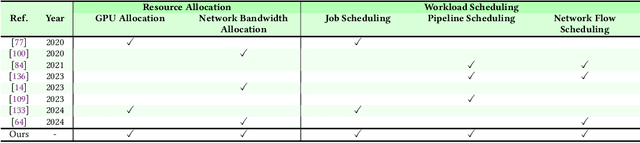
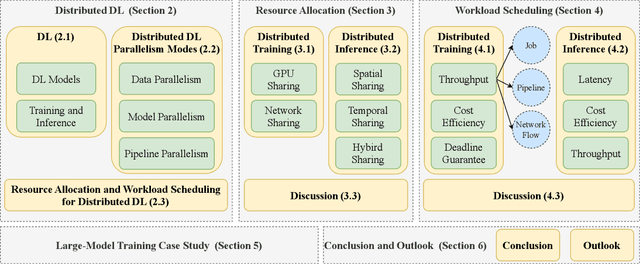
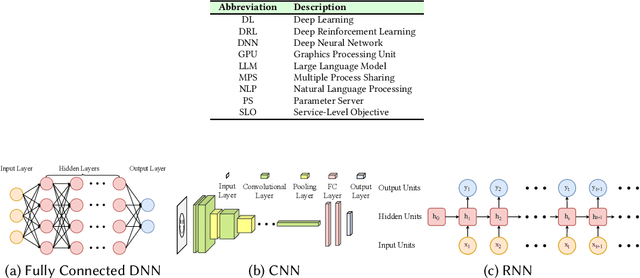
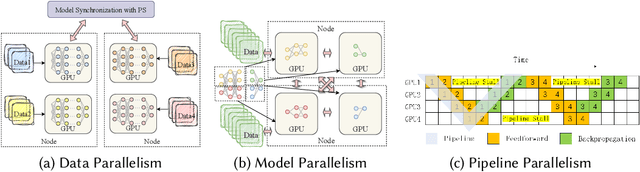
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
Communication-Efficient Large-Scale Distributed Deep Learning: A Comprehensive Survey
Apr 09, 2024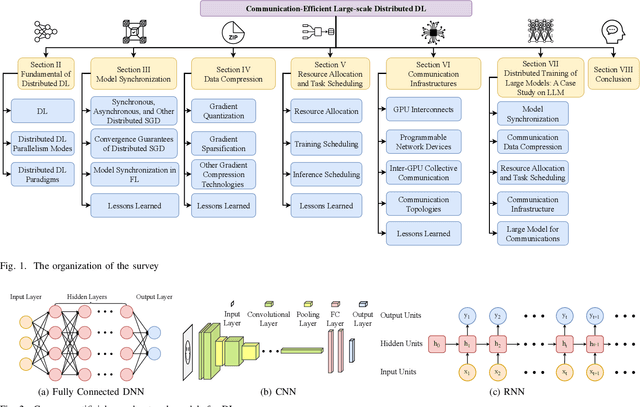
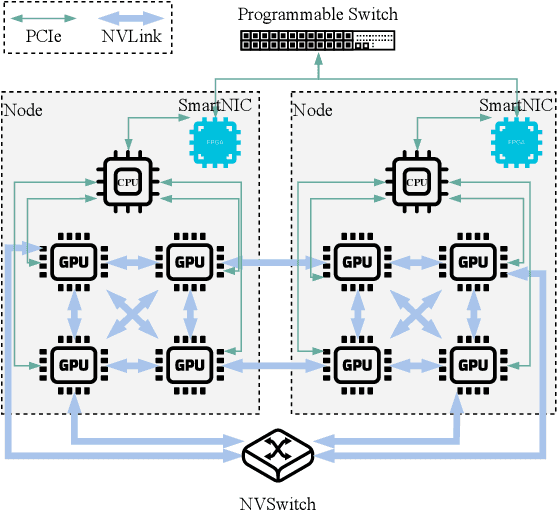
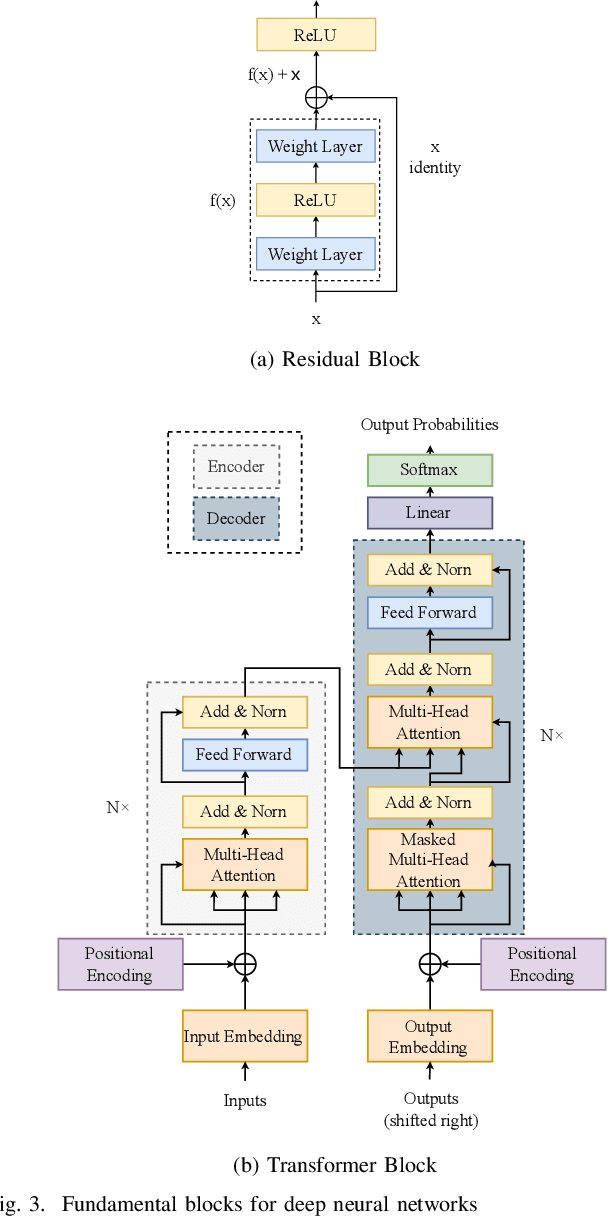

With the rapid growth in the volume of data sets, models, and devices in the domain of deep learning, there is increasing attention on large-scale distributed deep learning. In contrast to traditional distributed deep learning, the large-scale scenario poses new challenges that include fault tolerance, scalability of algorithms and infrastructures, and heterogeneity in data sets, models, and resources. Due to intensive synchronization of models and sharing of data across GPUs and computing nodes during distributed training and inference processes, communication efficiency becomes the bottleneck for achieving high performance at a large scale. This article surveys the literature over the period of 2018-2023 on algorithms and technologies aimed at achieving efficient communication in large-scale distributed deep learning at various levels, including algorithms, frameworks, and infrastructures. Specifically, we first introduce efficient algorithms for model synchronization and communication data compression in the context of large-scale distributed training. Next, we introduce efficient strategies related to resource allocation and task scheduling for use in distributed training and inference. After that, we present the latest technologies pertaining to modern communication infrastructures used in distributed deep learning with a focus on examining the impact of the communication overhead in a large-scale and heterogeneous setting. Finally, we conduct a case study on the distributed training of large language models at a large scale to illustrate how to apply these technologies in real cases. This article aims to offer researchers a comprehensive understanding of the current landscape of large-scale distributed deep learning and to reveal promising future research directions toward communication-efficient solutions in this scope.
Data Augmentation for Depression Detection Using Skeleton-Based Gait Information
Jan 04, 2022
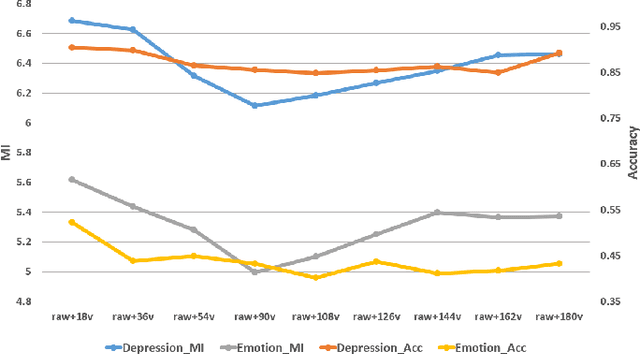
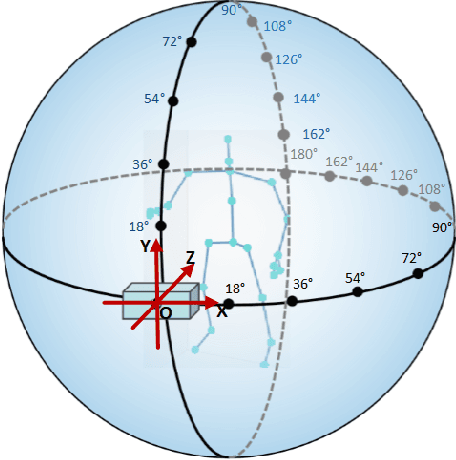
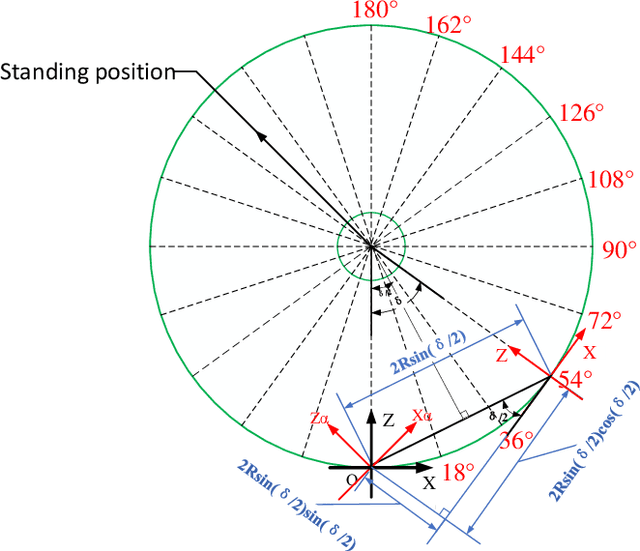
In recent years, the incidence of depression is rising rapidly worldwide, but large-scale depression screening is still challenging. Gait analysis provides a non-contact, low-cost, and efficient early screening method for depression. However, the early screening of depression based on gait analysis lacks sufficient effective sample data. In this paper, we propose a skeleton data augmentation method for assessing the risk of depression. First, we propose five techniques to augment skeleton data and apply them to depression and emotion datasets. Then, we divide augmentation methods into two types (non-noise augmentation and noise augmentation) based on the mutual information and the classification accuracy. Finally, we explore which augmentation strategies can capture the characteristics of human skeleton data more effectively. Experimental results show that the augmented training data set that retains more of the raw skeleton data properties determines the performance of the detection model. Specifically, rotation augmentation and channel mask augmentation make the depression detection accuracy reach 92.15% and 91.34%, respectively.