 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Rejection and Grounded Execution: A Dual-Stage Intent Analysis Paradigm for Safe and Efficient AIoT Smart Homes
Mar 17, 2026As Large Language Models (LLMs) transition from information providers to embodied agents in the Internet of Things (IoT), they face significant challenges regarding reliability and interaction efficiency. Direct execution of LLM-generated commands often leads to entity hallucinations (e.g., trying to control non-existent devices). Meanwhile, existing iterative frameworks (e.g., SAGE) suffer from the Interaction Frequency Dilemma, oscillating between reckless execution and excessive user questioning. To address these issues, we propose a Dual-Stage Intent-Aware (DS-IA) Framework. This framework separates high-level user intent understanding from low-level physical execution. Specifically, Stage 1 serves as a semantic firewall to filter out invalid instructions and resolve vague commands by checking the current state of the home. Stage 2 then employs a deterministic cascade verifier-a strict, step-by-step rule checker that verifies the room, device, and capability in sequence-to ensure the action is actually physically possible before execution. Extensive experiments on the HomeBench and SAGE benchmarks demonstrate that DS-IA achieves an Exact Match (EM) rate of 58.56% (outperforming baselines by over 28%) and improves the rejection rate of invalid instructions to 87.04%. Evaluations on the SAGE benchmark further reveal that DS-IA resolves the Interaction Frequency Dilemma by balancing proactive querying with state-based inference. Specifically, it boosts the Autonomous Success Rate (resolving tasks without unnecessary user intervention) from 42.86% to 71.43%, while maintaining high precision in identifying irreducible ambiguities that truly necessitate human clarification. These results underscore the framework's ability to minimize user disturbance through accurate environmental grounding.
Toward a Sustainable Federated Learning Ecosystem: A Practical Least Core Mechanism for Payoff Allocation
Feb 03, 2026Emerging network paradigms and applications increasingly rely on federated learning (FL) to enable collaborative intelligence while preserving privacy. However, the sustainability of such collaborative environments hinges on a fair and stable payoff allocation mechanism. Focusing on coalition stability, this paper introduces a payoff allocation framework based on the least core (LC) concept. Unlike traditional methods, the LC prioritizes the cohesion of the federation by minimizing the maximum dissatisfaction among all potential subgroups, ensuring that no participant has an incentive to break away. To adapt this game-theoretic concept to practical, large-scale networks, we propose a streamlined implementation with a stack-based pruning algorithm, effectively balancing computational efficiency with allocation precision. Case studies in federated intrusion detection demonstrate that our mechanism correctly identifies pivotal contributors and strategic alliances. The results confirm that the practical LC framework promotes stable collaboration and fosters a sustainable FL ecosystem.
M3SR: Multi-Scale Multi-Perceptual Mamba for Efficient Spectral Reconstruction
Jan 13, 2026The Mamba architecture has been widely applied to various low-level vision tasks due to its exceptional adaptability and strong performance. Although the Mamba architecture has been adopted for spectral reconstruction, it still faces the following two challenges: (1) Single spatial perception limits the ability to fully understand and analyze hyperspectral images; (2) Single-scale feature extraction struggles to capture the complex structures and fine details present in hyperspectral images. To address these issues, we propose a multi-scale, multi-perceptual Mamba architecture for the spectral reconstruction task, called M3SR. Specifically, we design a multi-perceptual fusion block to enhance the ability of the model to comprehensively understand and analyze the input features. By integrating the multi-perceptual fusion block into a U-Net structure, M3SR can effectively extract and fuse global, intermediate, and local features, thereby enabling accurate reconstruction of hyperspectral images at multiple scales. Extensive quantitative and qualitative experiments demonstrate that the proposed M3SR outperforms existing state-of-the-art methods while incurring a lower computational cost.
FedSM: Robust Semantics-Guided Feature Mixup for Bias Reduction in Federated Learning with Long-Tail Data
Oct 31, 2025Federated Learning (FL) enables collaborative model training across decentralized clients without sharing private data. However, FL suffers from biased global models due to non-IID and long-tail data distributions. We propose \textbf{FedSM}, a novel client-centric framework that mitigates this bias through semantics-guided feature mixup and lightweight classifier retraining. FedSM uses a pretrained image-text-aligned model to compute category-level semantic relevance, guiding the category selection of local features to mix-up with global prototypes to generate class-consistent pseudo-features. These features correct classifier bias, especially when data are heavily skewed. To address the concern of potential domain shift between the pretrained model and the data, we propose probabilistic category selection, enhancing feature diversity to effectively mitigate biases. All computations are performed locally, requiring minimal server overhead. Extensive experiments on long-tail datasets with various imbalanced levels demonstrate that FedSM consistently outperforms state-of-the-art methods in accuracy, with high robustness to domain shift and computational efficiency.
A Survey on Cloud-Edge-Terminal Collaborative Intelligence in AIoT Networks
Aug 26, 2025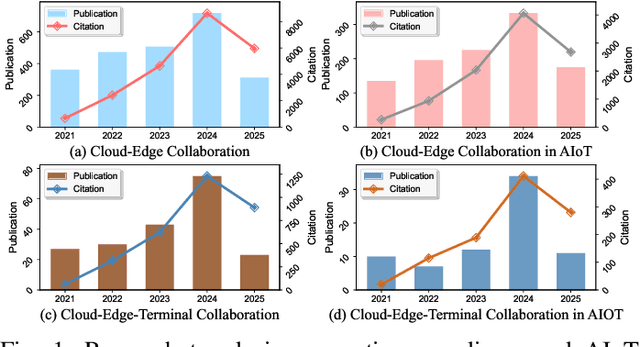
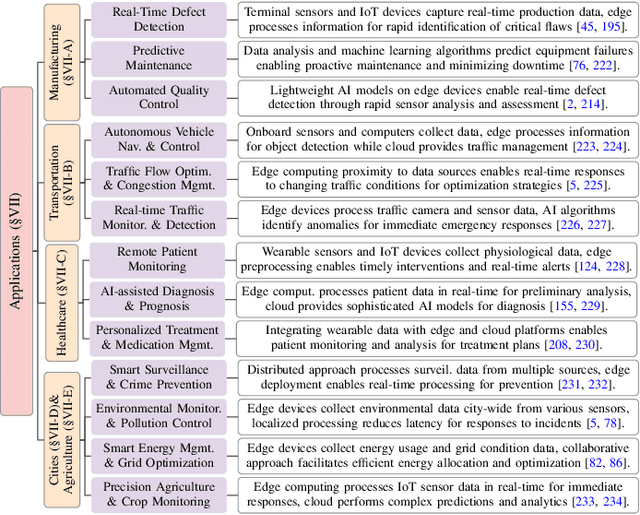
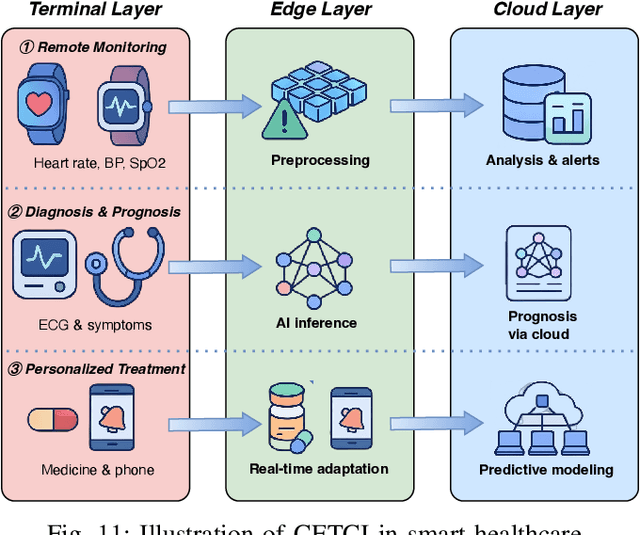
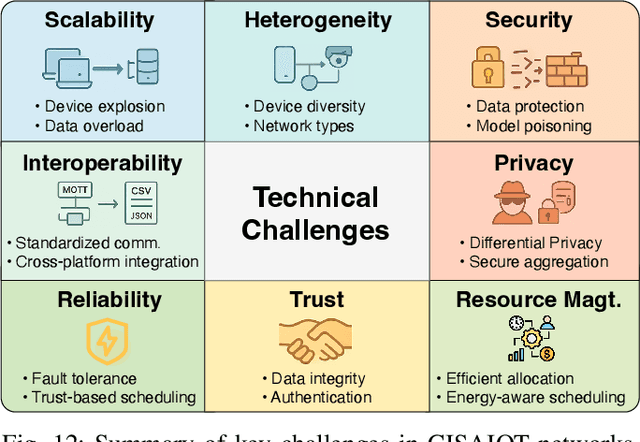
The proliferation of Internet of things (IoT) devices in smart cities, transportation, healthcare, and industrial applications, coupled with the explosive growth of AI-driven services, has increased demands for efficient distributed computing architectures and networks, driving cloud-edge-terminal collaborative intelligence (CETCI) as a fundamental paradigm within the artificial intelligence of things (AIoT) community. With advancements in deep learning, large language models (LLMs), and edge computing, CETCI has made significant progress with emerging AIoT applications, moving beyond isolated layer optimization to deployable collaborative intelligence systems for AIoT (CISAIOT), a practical research focus in AI, distributed computing, and communications. This survey describes foundational architectures, enabling technologies, and scenarios of CETCI paradigms, offering a tutorial-style review for CISAIOT beginners. We systematically analyze architectural components spanning cloud, edge, and terminal layers, examining core technologies including network virtualization, container orchestration, and software-defined networking, while presenting categorizations of collaboration paradigms that cover task offloading, resource allocation, and optimization across heterogeneous infrastructures. Furthermore, we explain intelligent collaboration learning frameworks by reviewing advances in federated learning, distributed deep learning, edge-cloud model evolution, and reinforcement learning-based methods. Finally, we discuss challenges (e.g., scalability, heterogeneity, interoperability) and future trends (e.g., 6G+, agents, quantum computing, digital twin), highlighting how integration of distributed computing and communication can address open issues and guide development of robust, efficient, and secure collaborative AIoT systems.
Exploring Audio Cues for Enhanced Test-Time Video Model Adaptation
Jun 14, 2025Test-time adaptation (TTA) aims to boost the generalization capability of a trained model by conducting self-/unsupervised learning during the testing phase. While most existing TTA methods for video primarily utilize visual supervisory signals, they often overlook the potential contribution of inherent audio data. To address this gap, we propose a novel approach that incorporates audio information into video TTA. Our method capitalizes on the rich semantic content of audio to generate audio-assisted pseudo-labels, a new concept in the context of video TTA. Specifically, we propose an audio-to-video label mapping method by first employing pre-trained audio models to classify audio signals extracted from videos and then mapping the audio-based predictions to video label spaces through large language models, thereby establishing a connection between the audio categories and video labels. To effectively leverage the generated pseudo-labels, we present a flexible adaptation cycle that determines the optimal number of adaptation iterations for each sample, based on changes in loss and consistency across different views. This enables a customized adaptation process for each sample. Experimental results on two widely used datasets (UCF101-C and Kinetics-Sounds-C), as well as on two newly constructed audio-video TTA datasets (AVE-C and AVMIT-C) with various corruption types, demonstrate the superiority of our approach. Our method consistently improves adaptation performance across different video classification models and represents a significant step forward in integrating audio information into video TTA. Code: https://github.com/keikeiqi/Audio-Assisted-TTA.
Model Splitting Enhanced Communication-Efficient Federated Learning for CSI Feedback
Jun 04, 2025Recent advancements have introduced federated machine learning-based channel state information (CSI) compression before the user equipments (UEs) upload the downlink CSI to the base transceiver station (BTS). However, most existing algorithms impose a high communication overhead due to frequent parameter exchanges between UEs and BTS. In this work, we propose a model splitting approach with a shared model at the BTS and multiple local models at the UEs to reduce communication overhead. Moreover, we implant a pipeline module at the BTS to reduce training time. By limiting exchanges of boundary parameters during forward and backward passes, our algorithm can significantly reduce the exchanged parameters over the benchmarks during federated CSI feedback training.
Sentinel: Scheduling Live Streams with Proactive Anomaly Detection in Crowdsourced Cloud-Edge Platforms
May 29, 2025With the rapid growth of live streaming services, Crowdsourced Cloud-edge service Platforms (CCPs) are playing an increasingly important role in meeting the increasing demand. Although stream scheduling plays a critical role in optimizing CCPs' revenue, most optimization strategies struggle to achieve practical results due to various anomalies in unstable CCPs. Additionally, the substantial scale of CCPs magnifies the difficulties of anomaly detection in time-sensitive scheduling. To tackle these challenges, this paper proposes Sentinel, a proactive anomaly detection-based scheduling framework. Sentinel models the scheduling process as a two-stage Pre-Post-Scheduling paradigm: in the pre-scheduling stage, Sentinel conducts anomaly detection and constructs a strategy pool; in the post-scheduling stage, upon request arrival, it triggers an appropriate scheduling based on a pre-generated strategy to implement the scheduling process. Extensive experiments on realistic datasets show that Sentinel significantly reduces anomaly frequency by 70%, improves revenue by 74%, and doubles the scheduling speed.
Edge-Cloud Collaborative Computing on Distributed Intelligence and Model Optimization: A Survey
May 03, 2025



Edge-cloud collaborative computing (ECCC) has emerged as a pivotal paradigm for addressing the computational demands of modern intelligent applications, integrating cloud resources with edge devices to enable efficient, low-latency processing. Recent advancements in AI, particularly deep learning and large language models (LLMs), have dramatically enhanced the capabilities of these distributed systems, yet introduce significant challenges in model deployment and resource management. In this survey, we comprehensive examine the intersection of distributed intelligence and model optimization within edge-cloud environments, providing a structured tutorial on fundamental architectures, enabling technologies, and emerging applications. Additionally, we systematically analyze model optimization approaches, including compression, adaptation, and neural architecture search, alongside AI-driven resource management strategies that balance performance, energy efficiency, and latency requirements. We further explore critical aspects of privacy protection and security enhancement within ECCC systems and examines practical deployments through diverse applications, spanning autonomous driving, healthcare, and industrial automation. Performance analysis and benchmarking techniques are also thoroughly explored to establish evaluation standards for these complex systems. Furthermore, the review identifies critical research directions including LLMs deployment, 6G integration, neuromorphic computing, and quantum computing, offering a roadmap for addressing persistent challenges in heterogeneity management, real-time processing, and scalability. By bridging theoretical advancements and practical deployments, this survey offers researchers and practitioners a holistic perspective on leveraging AI to optimize distributed computing environments, fostering innovation in next-generation intelligent systems.
CRCL: Causal Representation Consistency Learning for Anomaly Detection in Surveillance Videos
Mar 24, 2025Video Anomaly Detection (VAD) remains a fundamental yet formidable task in the video understanding community, with promising applications in areas such as information forensics and public safety protection. Due to the rarity and diversity of anomalies, existing methods only use easily collected regular events to model the inherent normality of normal spatial-temporal patterns in an unsupervised manner. Previous studies have shown that existing unsupervised VAD models are incapable of label-independent data offsets (e.g., scene changes) in real-world scenarios and may fail to respond to light anomalies due to the overgeneralization of deep neural networks. Inspired by causality learning, we argue that there exist causal factors that can adequately generalize the prototypical patterns of regular events and present significant deviations when anomalous instances occur. In this regard, we propose Causal Representation Consistency Learning (CRCL) to implicitly mine potential scene-robust causal variable in unsupervised video normality learning. Specifically, building on the structural causal models, we propose scene-debiasing learning and causality-inspired normality learning to strip away entangled scene bias in deep representations and learn causal video normality, respectively. Extensive experiments on benchmarks validate the superiority of our method over conventional deep representation learning. Moreover, ablation studies and extension validation show that the CRCL can cope with label-independent biases in multi-scene settings and maintain stable performance with only limited training data available.