 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZOTTA: Test-Time Adaptation with Gradient-Free Zeroth-Order Optimization
Mar 15, 2026Test-time adaptation (TTA) aims to improve model robustness under distribution shifts by adapting to unlabeled test data, but most existing methods rely on backpropagation (BP), which is computationally costly and incompatible with non-differentiable models such as quantized models, limiting practical deployment on numerous edge devices. Recent BP-free approaches alleviate overhead but remain either architecture-specific or limited in optimization capacity to handle high-dimensional models. We propose ZOTTA, a fully BP-free TTA framework that performs efficient adaptation using only forward passes via Zeroth-Order Optimization (ZOO). While ZOO is theoretically appealing, naive application leads to slow convergence under high-dimensional parameter spaces and unstable optimization due to the lack of labels. ZOTTA overcomes these challenges through 1) Distribution-Robust Layer Selection, which automatically identifies and freezes layers that already extract distribution-invariant features, updating only domain-sensitive layers to reduce the optimization dimensionality and accelerate convergence; 2) Spatial Feature Aggregation Alignment, which stabilizes ZOO by aligning globally aggregated spatial features between source and target to reduce gradient variance. Together, these components enable architecture-agnostic and stable BP-free adaptation. Extensive experiments on ImageNet-C/R/Sketch/A show that ZOTTA outperforms or matches BP-based methods, e.g., it reduces memory usage by 84% and improves accuracy by 3.9% over SAR on ImageNet-C.
A Penalty Approach for Differentiation Through Black-Box Quadratic Programming Solvers
Feb 15, 2026Differentiating through the solution of a quadratic program (QP) is a central problem in differentiable optimization. Most existing approaches differentiate through the Karush--Kuhn--Tucker (KKT) system, but their computational cost and numerical robustness can degrade at scale. To address these limitations, we propose dXPP, a penalty-based differentiation framework that decouples QP solving from differentiation. In the solving step (forward pass), dXPP is solver-agnostic and can leverage any black-box QP solver. In the differentiation step (backward pass), we map the solution to a smooth approximate penalty problem and implicitly differentiate through it, requiring only the solution of a much smaller linear system in the primal variables. This approach bypasses the difficulties inherent in explicit KKT differentiation and significantly improves computational efficiency and robustness. We evaluate dXPP on various tasks, including randomly generated QPs, large-scale sparse projection problems, and a real-world multi-period portfolio optimization task. Empirical results demonstrate that dXPP is competitive with KKT-based differentiation methods and achieves substantial speedups on large-scale problems.
Integrated Prediction and Multi-period Portfolio Optimization
Dec 15, 2025Multi-period portfolio optimization is important for real portfolio management, as it accounts for transaction costs, path-dependent risks, and the intertemporal structure of trading decisions that single-period models cannot capture. Classical methods usually follow a two-stage framework: machine learning algorithms are employed to produce forecasts that closely fit the realized returns, and the predicted values are then used in a downstream portfolio optimization problem to determine the asset weights. This separation leads to a fundamental misalignment between predictions and decision outcomes, while also ignoring the impact of transaction costs. To bridge this gap, recent studies have proposed the idea of end-to-end learning, integrating the two stages into a single pipeline. This paper introduces IPMO (Integrated Prediction and Multi-period Portfolio Optimization), a model for multi-period mean-variance portfolio optimization with turnover penalties. The predictor generates multi-period return forecasts that parameterize a differentiable convex optimization layer, which in turn drives learning via portfolio performance. For scalability, we introduce a mirror-descent fixed-point (MDFP) differentiation scheme that avoids factorizing the Karush-Kuhn-Tucker (KKT) systems, which thus yields stable implicit gradients and nearly scale-insensitive runtime as the decision horizon grows. In experiments with real market data and two representative time-series prediction models, the IPMO method consistently outperforms the two-stage benchmarks in risk-adjusted performance net of transaction costs and achieves more coherent allocation paths. Our results show that integrating machine learning prediction with optimization in the multi-period setting improves financial outcomes and remains computationally tractable.
Exploring Audio Cues for Enhanced Test-Time Video Model Adaptation
Jun 14, 2025Test-time adaptation (TTA) aims to boost the generalization capability of a trained model by conducting self-/unsupervised learning during the testing phase. While most existing TTA methods for video primarily utilize visual supervisory signals, they often overlook the potential contribution of inherent audio data. To address this gap, we propose a novel approach that incorporates audio information into video TTA. Our method capitalizes on the rich semantic content of audio to generate audio-assisted pseudo-labels, a new concept in the context of video TTA. Specifically, we propose an audio-to-video label mapping method by first employing pre-trained audio models to classify audio signals extracted from videos and then mapping the audio-based predictions to video label spaces through large language models, thereby establishing a connection between the audio categories and video labels. To effectively leverage the generated pseudo-labels, we present a flexible adaptation cycle that determines the optimal number of adaptation iterations for each sample, based on changes in loss and consistency across different views. This enables a customized adaptation process for each sample. Experimental results on two widely used datasets (UCF101-C and Kinetics-Sounds-C), as well as on two newly constructed audio-video TTA datasets (AVE-C and AVMIT-C) with various corruption types, demonstrate the superiority of our approach. Our method consistently improves adaptation performance across different video classification models and represents a significant step forward in integrating audio information into video TTA. Code: https://github.com/keikeiqi/Audio-Assisted-TTA.
Learning to Generate Gradients for Test-Time Adaptation via Test-Time Training Layers
Dec 22, 2024
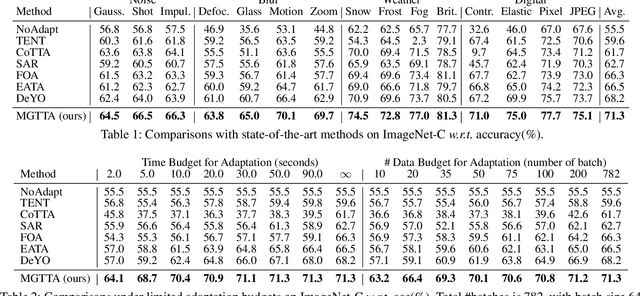
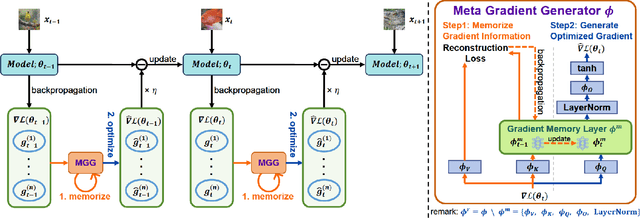
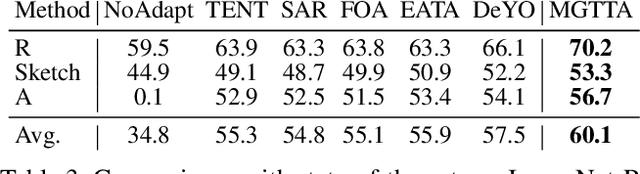
Test-time adaptation (TTA) aims to fine-tune a trained model online using unlabeled testing data to adapt to new environments or out-of-distribution data, demonstrating broad application potential in real-world scenarios. However, in this optimization process, unsupervised learning objectives like entropy minimization frequently encounter noisy learning signals. These signals produce unreliable gradients, which hinder the model ability to converge to an optimal solution quickly and introduce significant instability into the optimization process. In this paper, we seek to resolve these issues from the perspective of optimizer design. Unlike prior TTA using manually designed optimizers like SGD, we employ a learning-to-optimize approach to automatically learn an optimizer, called Meta Gradient Generator (MGG). Specifically, we aim for MGG to effectively utilize historical gradient information during the online optimization process to optimize the current model. To this end, in MGG, we design a lightweight and efficient sequence modeling layer -- gradient memory layer. It exploits a self-supervised reconstruction loss to compress historical gradient information into network parameters, thereby enabling better memorization ability over a long-term adaptation process. We only need a small number of unlabeled samples to pre-train MGG, and then the trained MGG can be deployed to process unseen samples. Promising results on ImageNet-C, R, Sketch, and A indicate that our method surpasses current state-of-the-art methods with fewer updates, less data, and significantly shorter adaptation iterations. Compared with a previous SOTA method SAR, we achieve 7.4% accuracy improvement and 4.2 times faster adaptation speed on ImageNet-C.
* 3 figures, 11 tables
Spatio-temporal Causal Learning for Streamflow Forecasting
Nov 26, 2024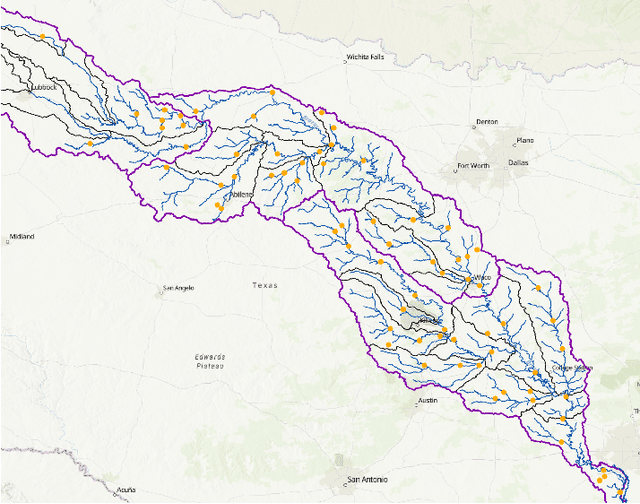
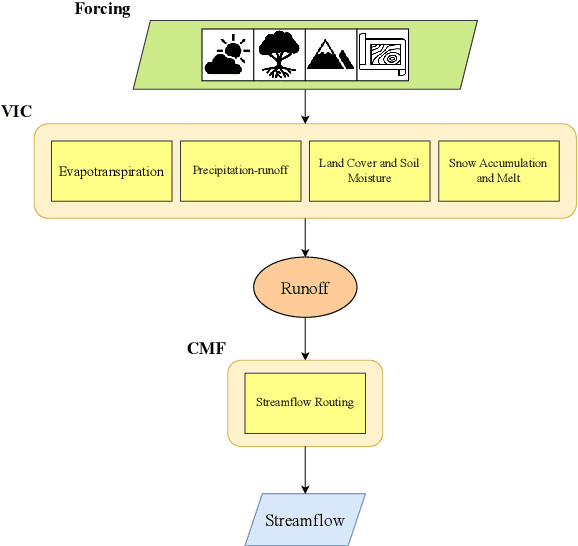
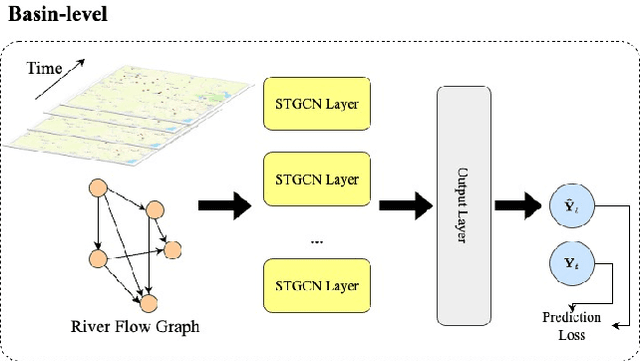
Streamflow plays an essential role in the sustainable planning and management of national water resources. Traditional hydrologic modeling approaches simulate streamflow by establishing connections across multiple physical processes, such as rainfall and runoff. These data, inherently connected both spatially and temporally, possess intrinsic causal relations that can be leveraged for robust and accurate forecasting. Recently, spatio-temporal graph neural networks (STGNNs) have been adopted, excelling in various domains, such as urban traffic management, weather forecasting, and pandemic control, and they also promise advances in streamflow management. However, learning causal relationships directly from vast observational data is theoretically and computationally challenging. In this study, we employ a river flow graph as prior knowledge to facilitate the learning of the causal structure and then use the learned causal graph to predict streamflow at targeted sites. The proposed model, Causal Streamflow Forecasting (CSF) is tested in a real-world study in the Brazos River basin in Texas. Our results demonstrate that our method outperforms regular spatio-temporal graph neural networks and achieves higher computational efficiency compared to traditional simulation methods. By effectively integrating river flow graphs with STGNNs, this research offers a novel approach to streamflow prediction, showcasing the potential of combining advanced neural network techniques with domain-specific knowledge for enhanced performance in hydrologic modeling.
Solving the Food-Energy-Water Nexus Problem via Intelligent Optimization Algorithms
Apr 10, 2024The application of evolutionary algorithms (EAs) to multi-objective optimization problems has been widespread. However, the EA research community has not paid much attention to large-scale multi-objective optimization problems arising from real-world applications. Especially, Food-Energy-Water systems are intricately linked among food, energy and water that impact each other. They usually involve a huge number of decision variables and many conflicting objectives to be optimized. Solving their related optimization problems is essentially important to sustain the high-quality life of human beings. Their solution space size expands exponentially with the number of decision variables. Searching in such a vast space is challenging because of such large numbers of decision variables and objective functions. In recent years, a number of large-scale many-objectives optimization evolutionary algorithms have been proposed. In this paper, we solve a Food-Energy-Water optimization problem by using the state-of-art intelligent optimization methods and compare their performance. Our results conclude that the algorithm based on an inverse model outperforms the others. This work should be highly useful for practitioners to select the most suitable method for their particular large-scale engineering optimization problems.
Stochastic Weakly Convex Optimization Beyond Lipschitz Continuity
Jan 25, 2024



This paper considers stochastic weakly convex optimization without the standard Lipschitz continuity assumption. Based on new adaptive regularization (stepsize) strategies, we show that a wide class of stochastic algorithms, including the stochastic subgradient method, preserve the $\mathcal{O} ( 1 / \sqrt{K})$ convergence rate with constant failure rate. Our analyses rest on rather weak assumptions: the Lipschitz parameter can be either bounded by a general growth function of $\|x\|$ or locally estimated through independent random samples.
A Homogenization Approach for Gradient-Dominated Stochastic Optimization
Aug 21, 2023



Gradient dominance property is a condition weaker than strong convexity, yet it sufficiently ensures global convergence for first-order methods even in non-convex optimization. This property finds application in various machine learning domains, including matrix decomposition, linear neural networks, and policy-based reinforcement learning (RL). In this paper, we study the stochastic homogeneous second-order descent method (SHSODM) for gradient-dominated optimization with $\alpha \in [1, 2]$ based on a recently proposed homogenization approach. Theoretically, we show that SHSODM achieves a sample complexity of $O(\epsilon^{-7/(2 \alpha) +1})$ for $\alpha \in [1, 3/2)$ and $\tilde{O}(\epsilon^{-2/\alpha})$ for $\alpha \in [3/2, 2]$. We further provide a SHSODM with a variance reduction technique enjoying an improved sample complexity of $O( \epsilon ^{-( 7-3\alpha ) /( 2\alpha )})$ for $\alpha \in [1,3/2)$. Our results match the state-of-the-art sample complexity bounds for stochastic gradient-dominated optimization without \emph{cubic regularization}. Since the homogenization approach only relies on solving extremal eigenvector problems instead of Newton-type systems, our methods gain the advantage of cheaper iterations and robustness in ill-conditioned problems. Numerical experiments on several RL tasks demonstrate the efficiency of SHSODM compared to other off-the-shelf methods.
GBM-based Bregman Proximal Algorithms for Constrained Learning
Aug 21, 2023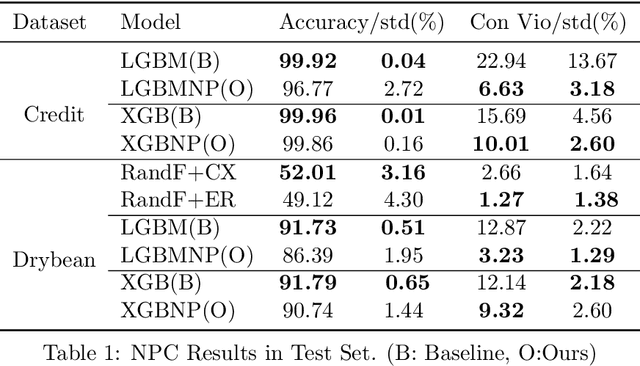

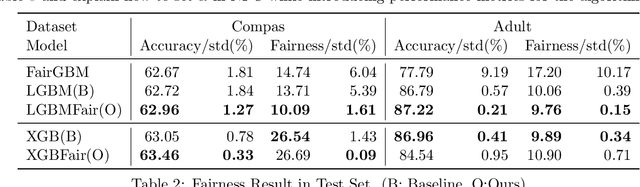

As the complexity of learning tasks surges, modern machine learning encounters a new constrained learning paradigm characterized by more intricate and data-driven function constraints. Prominent applications include Neyman-Pearson classification (NPC) and fairness classification, which entail specific risk constraints that render standard projection-based training algorithms unsuitable. Gradient boosting machines (GBMs) are among the most popular algorithms for supervised learning; however, they are generally limited to unconstrained settings. In this paper, we adapt the GBM for constrained learning tasks within the framework of Bregman proximal algorithms. We introduce a new Bregman primal-dual method with a global optimality guarantee when the learning objective and constraint functions are convex. In cases of nonconvex functions, we demonstrate how our algorithm remains effective under a Bregman proximal point framework. Distinct from existing constrained learning algorithms, ours possess a unique advantage in their ability to seamlessly integrate with publicly available GBM implementations such as XGBoost (Chen and Guestrin, 2016) and LightGBM (Ke et al., 2017), exclusively relying on their public interfaces. We provide substantial experimental evidence to showcase the effectiveness of the Bregman algorithm framework. While our primary focus is on NPC and fairness ML, our framework holds significant potential for a broader range of constrained learning applications. The source code is currently freely available at https://github.com/zhenweilin/ConstrainedGBM}{https://github.com/zhenweilin/ConstrainedGBM.