 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGverse: Building Document-Grounded Semantic DAGs from Scientific Papers
Mar 26, 2026Directed Acyclic Graphs (DAGs) are widely used to represent structured knowledge in scientific and technical domains. However, datasets for real-world DAGs remain scarce because constructing them typically requires expert interpretation of domain documents. We study Doc2SemDAG construction: recovering a preferred semantic DAG from a document together with the cited evidence and context that explain it. This problem is challenging because a document may admit multiple plausible abstractions, the intended structure is often implicit, and the supporting evidence is scattered across prose, equations, captions, and figures. To address these challenges, we leverage scientific papers containing explicit DAG figures as a natural source of supervision. In this setting, the DAG figure provides the DAG structure, while the accompanying text provides context and explanation. We introduce DAGverse, a framework for constructing document-grounded semantic DAGs from online scientific papers. Its core component, DAGverse-Pipeline, is a semi-automatic system designed to produce high-precision semantic DAG examples through figure classification, graph reconstruction, semantic grounding, and validation. As a case study, we test the framework for causal DAGs and release DAGverse-1, a dataset of 108 expert-validated semantic DAGs with graph-level, node-level, and edge-level evidence. Experiments show that DAGverse-Pipeline outperforms existing Vision-Language Models on DAG classification and annotation. DAGverse provides a foundation for document-grounded DAG benchmarks and opens new directions for studying structured reasoning grounded in real-world evidence.
Proxy-Guided Measurement Calibration
Mar 11, 2026Aggregate outcome variables collected through surveys and administrative records are often subject to systematic measurement error. For instance, in disaster loss databases, county-level losses reported may differ from the true damages due to variations in on-the-ground data collection capacity, reporting practices, and event characteristics. Such miscalibration complicates downstream analysis and decision-making. We study the problem of outcome miscalibration and propose a framework guided by proxy variables for estimating and correcting the systematic errors. We model the data-generating process using a causal graph that separates latent content variables driving the true outcome from the latent bias variables that induce systematic errors. The key insight is that proxy variables that depend on the true outcome but are independent of the bias mechanism provide identifying information for quantifying the bias. Leveraging this structure, we introduce a two-stage approach that utilizes variational autoencoders to disentangle content and bias latents, enabling us to estimate the effect of bias on the outcome of interest. We analyze the assumptions underlying our approach and evaluate it on synthetic data, semi-synthetic datasets derived from randomized trials, and a real-world case study of disaster loss reporting.
CauSTream: Causal Spatio-Temporal Representation Learning for Streamflow Forecasting
Dec 18, 2025Streamflow forecasting is crucial for water resource management and risk mitigation. While deep learning models have achieved strong predictive performance, they often overlook underlying physical processes, limiting interpretability and generalization. Recent causal learning approaches address these issues by integrating domain knowledge, yet they typically rely on fixed causal graphs that fail to adapt to data. We propose CauStream, a unified framework for causal spatiotemporal streamflow forecasting. CauSTream jointly learns (i) a runoff causal graph among meteorological forcings and (ii) a routing graph capturing dynamic dependencies across stations. We further establish identifiability conditions for these causal structures under a nonparametric setting. We evaluate CauSTream on three major U.S. river basins across three forecasting horizons. The model consistently outperforms prior state-of-the-art methods, with performance gaps widening at longer forecast windows, indicating stronger generalization to unseen conditions. Beyond forecasting, CauSTream also learns causal graphs that capture relationships among hydrological factors and stations. The inferred structures align closely with established domain knowledge, offering interpretable insights into watershed dynamics. CauSTream offers a principled foundation for causal spatiotemporal modeling, with the potential to extend to a wide range of scientific and environmental applications.
Causality Guided Representation Learning for Cross-Style Hate Speech Detection
Oct 09, 2025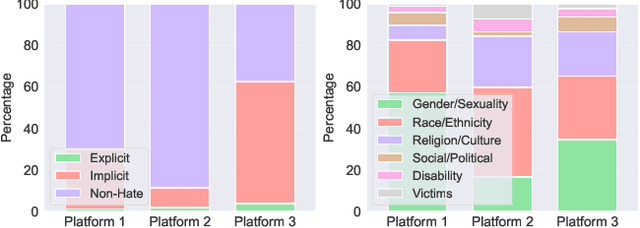
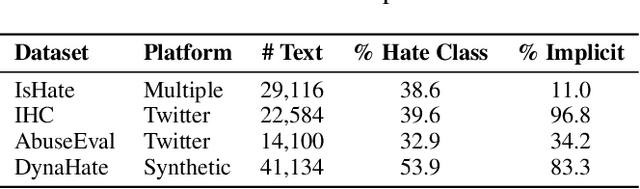
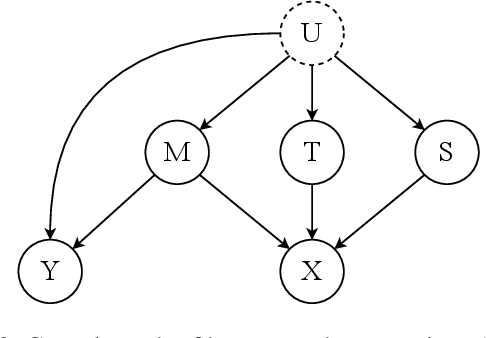
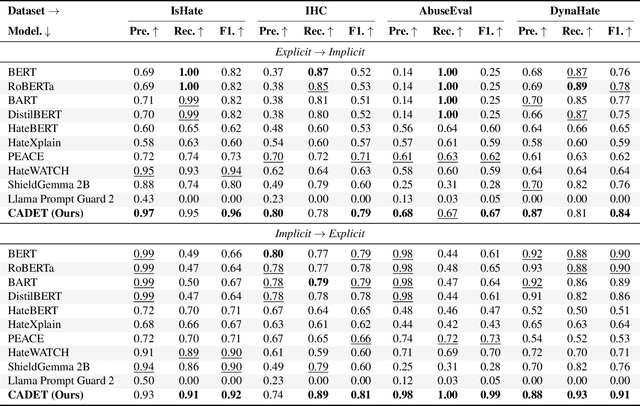
The proliferation of online hate speech poses a significant threat to the harmony of the web. While explicit hate is easily recognized through overt slurs, implicit hate speech is often conveyed through sarcasm, irony, stereotypes, or coded language -- making it harder to detect. Existing hate speech detection models, which predominantly rely on surface-level linguistic cues, fail to generalize effectively across diverse stylistic variations. Moreover, hate speech spread on different platforms often targets distinct groups and adopts unique styles, potentially inducing spurious correlations between them and labels, further challenging current detection approaches. Motivated by these observations, we hypothesize that the generation of hate speech can be modeled as a causal graph involving key factors: contextual environment, creator motivation, target, and style. Guided by this graph, we propose CADET, a causal representation learning framework that disentangles hate speech into interpretable latent factors and then controls confounders, thereby isolating genuine hate intent from superficial linguistic cues. Furthermore, CADET allows counterfactual reasoning by intervening on style within the latent space, naturally guiding the model to robustly identify hate speech in varying forms. CADET demonstrates superior performance in comprehensive experiments, highlighting the potential of causal priors in advancing generalizable hate speech detection.
Spatio-temporal Causal Learning for Streamflow Forecasting
Nov 26, 2024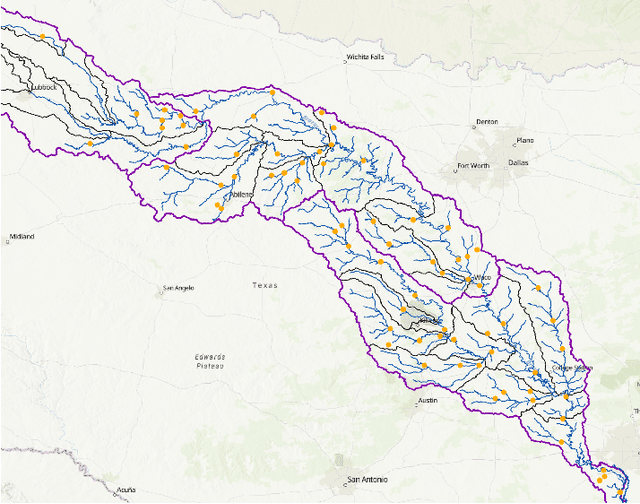
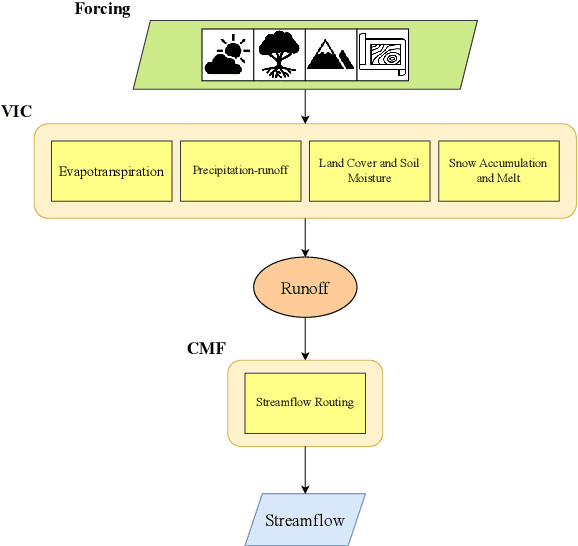
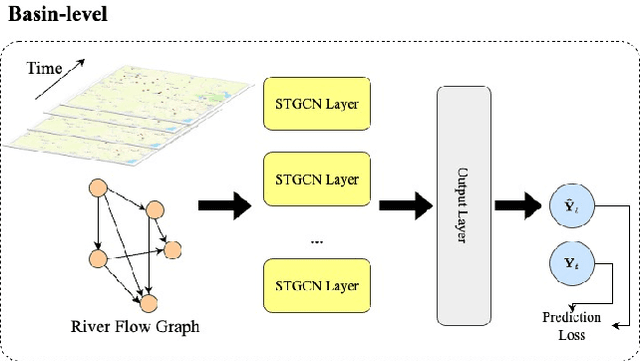
Streamflow plays an essential role in the sustainable planning and management of national water resources. Traditional hydrologic modeling approaches simulate streamflow by establishing connections across multiple physical processes, such as rainfall and runoff. These data, inherently connected both spatially and temporally, possess intrinsic causal relations that can be leveraged for robust and accurate forecasting. Recently, spatio-temporal graph neural networks (STGNNs) have been adopted, excelling in various domains, such as urban traffic management, weather forecasting, and pandemic control, and they also promise advances in streamflow management. However, learning causal relationships directly from vast observational data is theoretically and computationally challenging. In this study, we employ a river flow graph as prior knowledge to facilitate the learning of the causal structure and then use the learned causal graph to predict streamflow at targeted sites. The proposed model, Causal Streamflow Forecasting (CSF) is tested in a real-world study in the Brazos River basin in Texas. Our results demonstrate that our method outperforms regular spatio-temporal graph neural networks and achieves higher computational efficiency compared to traditional simulation methods. By effectively integrating river flow graphs with STGNNs, this research offers a novel approach to streamflow prediction, showcasing the potential of combining advanced neural network techniques with domain-specific knowledge for enhanced performance in hydrologic modeling.
Introducing CausalBench: A Flexible Benchmark Framework for Causal Analysis and Machine Learning
Sep 12, 2024


While witnessing the exceptional success of machine learning (ML) technologies in many applications, users are starting to notice a critical shortcoming of ML: correlation is a poor substitute for causation. The conventional way to discover causal relationships is to use randomized controlled experiments (RCT); in many situations, however, these are impractical or sometimes unethical. Causal learning from observational data offers a promising alternative. While being relatively recent, causal learning aims to go far beyond conventional machine learning, yet several major challenges remain. Unfortunately, advances are hampered due to the lack of unified benchmark datasets, algorithms, metrics, and evaluation service interfaces for causal learning. In this paper, we introduce {\em CausalBench}, a transparent, fair, and easy-to-use evaluation platform, aiming to (a) enable the advancement of research in causal learning by facilitating scientific collaboration in novel algorithms, datasets, and metrics and (b) promote scientific objectivity, reproducibility, fairness, and awareness of bias in causal learning research. CausalBench provides services for benchmarking data, algorithms, models, and metrics, impacting the needs of a broad of scientific and engineering disciplines.
Long-term Causal Effects Estimation via Latent Surrogates Representation Learning
Aug 09, 2022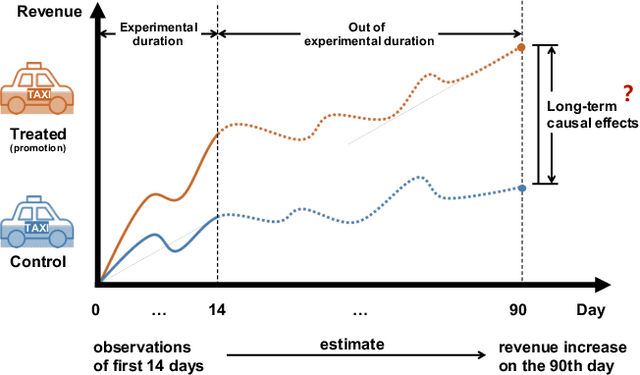
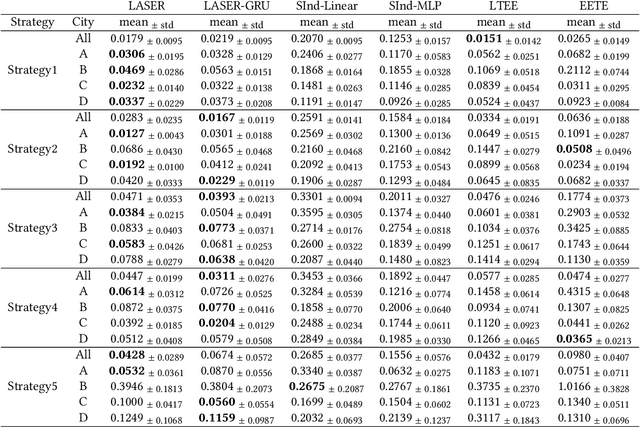
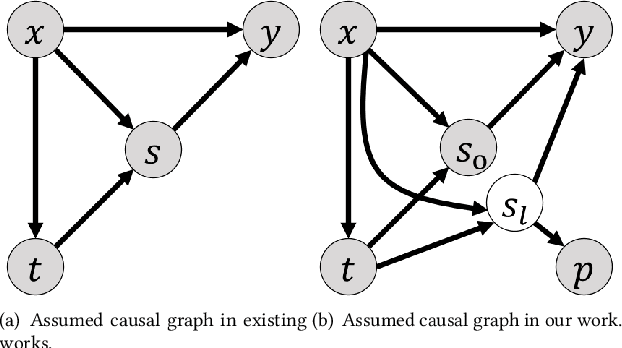
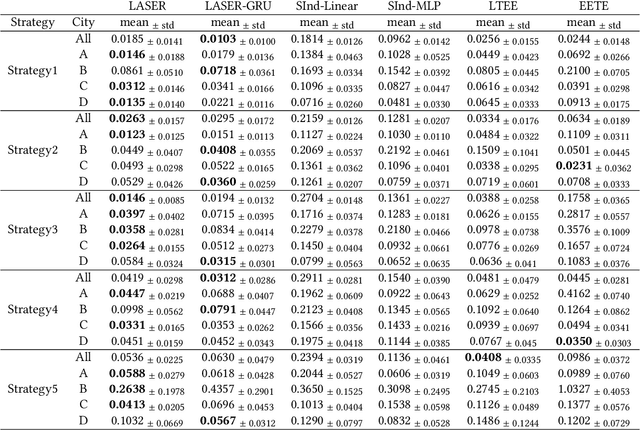
Estimating long-term causal effects based on short-term surrogates is a significant but challenging problem in many real-world applications, e.g., marketing and medicine. Despite its success in certain domains, most existing methods estimate causal effects in an idealistic and simplistic way - ignoring the causal structure among short-term outcomes and treating all of them as surrogates. However, such methods cannot be well applied to real-world scenarios, in which the partially observed surrogates are mixed with their proxies among short-term outcomes. To this end, we develop our flexible method, Laser, to estimate long-term causal effects in the more realistic situation that the surrogates are observed or have observed proxies.Given the indistinguishability between the surrogates and proxies, we utilize identifiable variational auto-encoder (iVAE) to recover the whole valid surrogates on all the surrogates candidates without the need of distinguishing the observed surrogates or the proxies of latent surrogates. With the help of the recovered surrogates, we further devise an unbiased estimation of long-term causal effects. Extensive experimental results on the real-world and semi-synthetic datasets demonstrate the effectiveness of our proposed method.
GCF: Generalized Causal Forest for Heterogeneous Treatment Effect Estimation in Online Marketplace
Mar 21, 2022

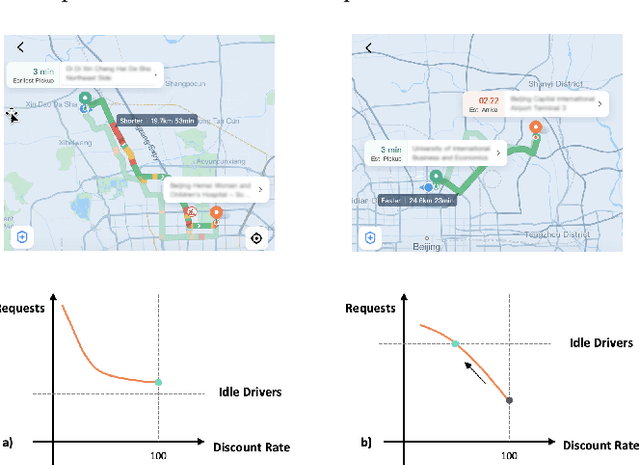
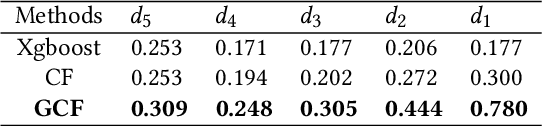
Uplift modeling is a rapidly growing approach that utilizes machine learning and causal inference methods to estimate the heterogeneous treatment effects. It has been widely adopted and applied to online marketplaces to assist large-scale decision-making in recent years. The existing popular methods, like forest-based modeling, either work only for discrete treatments or make partially linear or parametric assumptions that may suffer from model misspecification. To alleviate these problems, we extend causal forest (CF) with non-parametric dose-response functions (DRFs) that can be estimated locally using a kernel-based doubly robust estimator. Moreover, we propose a distance-based splitting criterion in the functional space of conditional DRFs to capture the heterogeneity for the continuous treatments. We call the proposed algorithm generalized causal forest (GCF) as it generalizes the use case of CF to a much broader setup. We show the effectiveness of GCF by comparing it to popular uplift modeling models on both synthetic and real-world datasets. We implement GCF in Spark and successfully deploy it into DiDi's real-time pricing system. Online A/B testing results further validate the superiority of GCF.