 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Bayesian Message Passing under Structural Uncertainty
Jan 03, 2026Semi-supervised learning on real-world graphs is frequently challenged by heterophily, where the observed graph is unreliable or label-disassortative. Many existing graph neural networks either rely on a fixed adjacency structure or attempt to handle structural noise through regularization. In this work, we explicitly capture structural uncertainty by modeling a posterior distribution over signed adjacency matrices, allowing each edge to be positive, negative, or absent. We propose a sparse signed message passing network that is naturally robust to edge noise and heterophily, which can be interpreted from a Bayesian perspective. By combining (i) posterior marginalization over signed graph structures with (ii) sparse signed message aggregation, our approach offers a principled way to handle both edge noise and heterophily. Experimental results demonstrate that our method outperforms strong baseline models on heterophilic benchmarks under both synthetic and real-world structural noise.
Sheaf Graph Neural Networks via PAC-Bayes Spectral Optimization
Aug 01, 2025Over-smoothing in Graph Neural Networks (GNNs) causes collapse in distinct node features, particularly on heterophilic graphs where adjacent nodes often have dissimilar labels. Although sheaf neural networks partially mitigate this problem, they typically rely on static or heavily parameterized sheaf structures that hinder generalization and scalability. Existing sheaf-based models either predefine restriction maps or introduce excessive complexity, yet fail to provide rigorous stability guarantees. In this paper, we introduce a novel scheme called SGPC (Sheaf GNNs with PAC-Bayes Calibration), a unified architecture that combines cellular-sheaf message passing with several mechanisms, including optimal transport-based lifting, variance-reduced diffusion, and PAC-Bayes spectral regularization for robust semi-supervised node classification. We establish performance bounds theoretically and demonstrate that the resulting bound-aware objective can be achieved via end-to-end training in linear computational complexity. Experiments on nine homophilic and heterophilic benchmarks show that SGPC outperforms state-of-the-art spectral and sheaf-based GNNs while providing certified confidence intervals on unseen nodes.
SpecSphere: Dual-Pass Spectral-Spatial Graph Neural Networks with Certified Robustness
May 14, 2025We introduce SpecSphere, the first dual-pass spectral-spatial GNN that certifies every prediction against both $\ell\_{0}$ edge flips and $\ell\_{\infty}$ feature perturbations, adapts to the full homophily-heterophily spectrum, and surpasses the expressive power of 1-Weisfeiler-Lehman while retaining linear-time complexity. Our model couples a Chebyshev-polynomial spectral branch with an attention-gated spatial branch and fuses their representations through a lightweight MLP trained in a cooperative-adversarial min-max game. We further establish (i) a uniform Chebyshev approximation theorem, (ii) minimax-optimal risk across the homophily-heterophily spectrum, (iii) closed-form robustness certificates, and (iv) universal approximation strictly beyond 1-WL. SpecSphere achieves state-of-the-art node-classification accuracy and delivers tighter certified robustness guarantees on real-world benchmarks. These results demonstrate that high expressivity, heterophily adaptation, and provable robustness can coexist within a single, scalable architecture.
Hierarchical Uncertainty-Aware Graph Neural Network
Apr 28, 2025Recent research on graph neural networks (GNNs) has explored mechanisms for capturing local uncertainty and exploiting graph hierarchies to mitigate data sparsity and leverage structural properties. However, the synergistic integration of these two approaches remains underexplored. In this work, we introduce a novel architecture, the Hierarchical Uncertainty-Aware Graph Neural Network (HU-GNN), which unifies multi-scale representation learning, principled uncertainty estimation, and self-supervised embedding diversity within a single end-to-end framework. Specifically, HU-GNN adaptively forms node clusters and estimates uncertainty at multiple structural scales from individual nodes to higher levels. These uncertainty estimates guide a robust message-passing mechanism and attention weighting, effectively mitigating noise and adversarial perturbations while preserving predictive accuracy on both node- and graph-level tasks. We also offer key theoretical contributions, including a probabilistic formulation, rigorous uncertainty-calibration guarantees, and formal robustness bounds. Finally, by incorporating recent advances in graph contrastive learning, HU-GNN maintains diverse, structurally faithful embeddings. Extensive experiments on standard benchmarks demonstrate that our model achieves state-of-the-art robustness and interpretability.
Introducing CausalBench: A Flexible Benchmark Framework for Causal Analysis and Machine Learning
Sep 12, 2024


While witnessing the exceptional success of machine learning (ML) technologies in many applications, users are starting to notice a critical shortcoming of ML: correlation is a poor substitute for causation. The conventional way to discover causal relationships is to use randomized controlled experiments (RCT); in many situations, however, these are impractical or sometimes unethical. Causal learning from observational data offers a promising alternative. While being relatively recent, causal learning aims to go far beyond conventional machine learning, yet several major challenges remain. Unfortunately, advances are hampered due to the lack of unified benchmark datasets, algorithms, metrics, and evaluation service interfaces for causal learning. In this paper, we introduce {\em CausalBench}, a transparent, fair, and easy-to-use evaluation platform, aiming to (a) enable the advancement of research in causal learning by facilitating scientific collaboration in novel algorithms, datasets, and metrics and (b) promote scientific objectivity, reproducibility, fairness, and awareness of bias in causal learning research. CausalBench provides services for benchmarking data, algorithms, models, and metrics, impacting the needs of a broad of scientific and engineering disciplines.
Better Not to Propagate: Understanding Edge Uncertainty and Over-smoothing in Signed Graph Neural Networks
Aug 09, 2024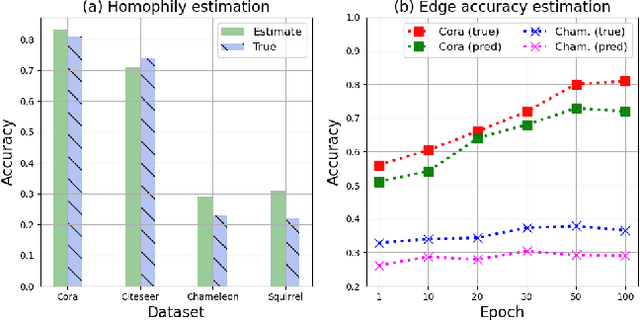
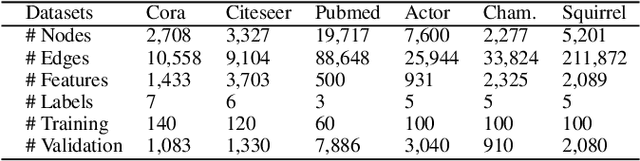
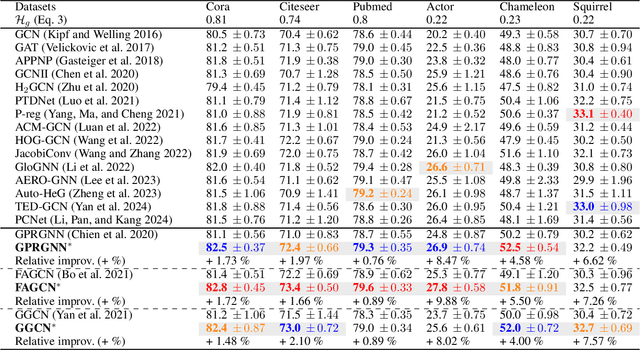
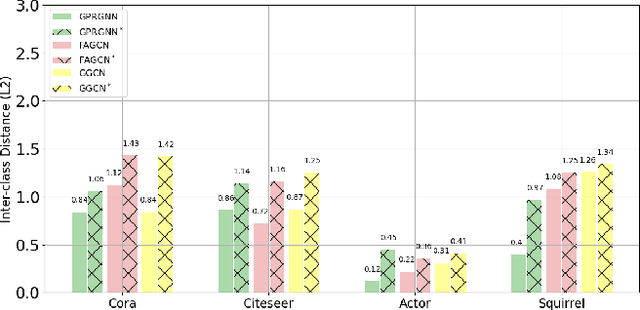
Traditional Graph Neural Networks (GNNs) rely on network homophily, which can lead to performance degradation due to over-smoothing in many real-world heterophily scenarios. Recent studies analyze the smoothing effect (separability) after message-passing (MP), depending on the expectation of node features. Regarding separability gain, they provided theoretical backgrounds on over-smoothing caused by various propagation schemes, including positive, signed, and blocked MPs. More recently, by extending these theorems, some works have suggested improvements in signed propagation under multiple classes. However, prior works assume that the error ratio of all propagation schemes is fixed, failing to investigate this phenomenon correctly. To solve this problem, we propose a novel method for estimating homophily and edge error ratio, integrated with dynamic selection between blocked and signed propagation during training. Our theoretical analysis, supported by extensive experiments, demonstrates that blocking MP can be more effective than signed propagation under high edge error ratios, improving the performance in both homophilic and heterophilic graphs.
Prioritizing Potential Wetland Areas via Region-to-Region Knowledge Transfer and Adaptive Propagation
Jun 08, 2024
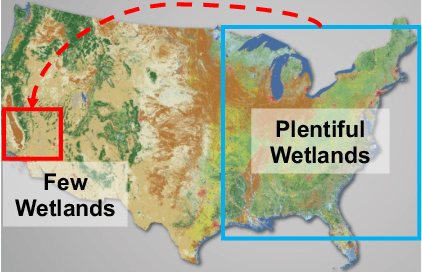
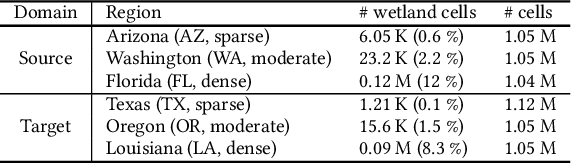
Wetlands are important to communities, offering benefits ranging from water purification, and flood protection to recreation and tourism. Therefore, identifying and prioritizing potential wetland areas is a critical decision problem. While data-driven solutions are feasible, this is complicated by significant data sparsity due to the low proportion of wetlands (3-6\%) in many areas of interest in the southwestern US. This makes it hard to develop data-driven models that can help guide the identification of additional wetland areas. To solve this limitation, we propose two strategies: (1) The first of these is knowledge transfer from regions with rich wetlands (such as the Eastern US) to sparser regions (such as the Southwestern area with few wetlands). Recognizing that these regions are likely to be very different from each other in terms of soil characteristics, population distribution, and land use, we propose a domain disentanglement strategy that identifies and transfers only the applicable aspects of the learned model. (2) We complement this with a spatial data enrichment strategy that relies on an adaptive propagation mechanism. This mechanism differentiates between node pairs that have positive and negative impacts on each other for Graph Neural Networks (GNNs). To summarize, given two spatial cells belonging to different regions, we identify domain-specific and domain-shareable features, and, for each region, we rely on adaptive propagation to enrich features with the features of surrounding cells. We conduct rigorous experiments to substantiate our proposed method's effectiveness, robustness, and scalability compared to state-of-the-art baselines. Additionally, an ablation study demonstrates that each module is essential in prioritizing potential wetlands, which justifies our assumption.
Review-Based Cross-Domain Recommendation via Hyperbolic Embedding and Hierarchy-Aware Domain Disentanglement
Mar 29, 2024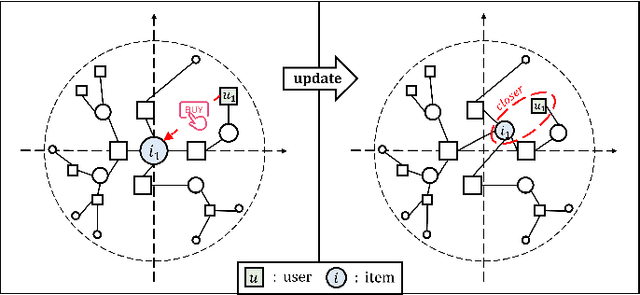
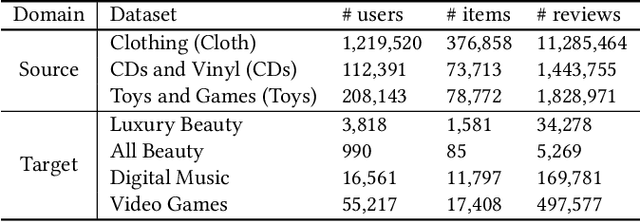
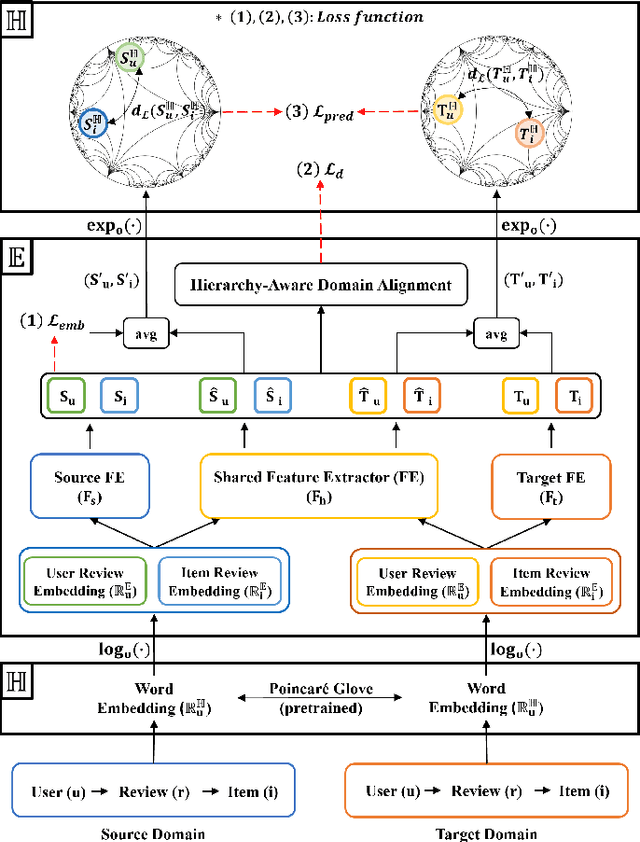
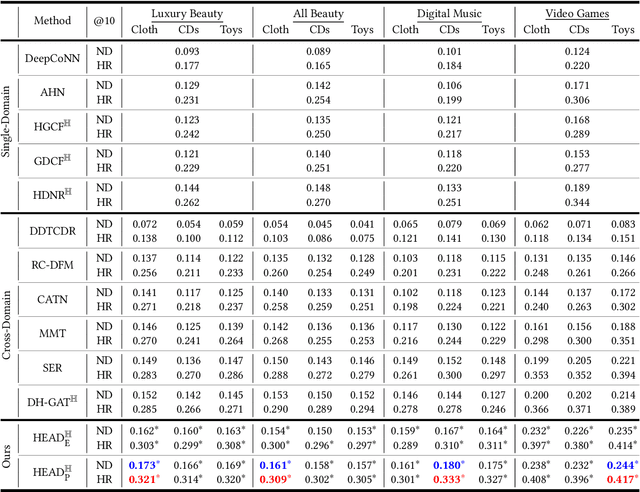
The issue of data sparsity poses a significant challenge to recommender systems. In response to this, algorithms that leverage side information such as review texts have been proposed. Furthermore, Cross-Domain Recommendation (CDR), which captures domain-shareable knowledge and transfers it from a richer domain (source) to a sparser one (target), has received notable attention. Nevertheless, the majority of existing methodologies assume a Euclidean embedding space, encountering difficulties in accurately representing richer text information and managing complex interactions between users and items. This paper advocates a hyperbolic CDR approach based on review texts for modeling user-item relationships. We first emphasize that conventional distance-based domain alignment techniques may cause problems because small modifications in hyperbolic geometry result in magnified perturbations, ultimately leading to the collapse of hierarchical structures. To address this challenge, we propose hierarchy-aware embedding and domain alignment schemes that adjust the scale to extract domain-shareable information without disrupting structural forms. The process involves the initial embedding of review texts in hyperbolic space, followed by feature extraction incorporating degree-based normalization and structure alignment. We conducted extensive experiments to substantiate the efficiency, robustness, and scalability of our proposed model in comparison to state-of-the-art baselines.
Finding Heterophilic Neighbors via Confidence-based Subgraph Matching for Semi-supervised Node Classification
Feb 20, 2023Graph Neural Networks (GNNs) have proven to be powerful in many graph-based applications. However, they fail to generalize well under heterophilic setups, where neighbor nodes have different labels. To address this challenge, we employ a confidence ratio as a hyper-parameter, assuming that some of the edges are disassortative (heterophilic). Here, we propose a two-phased algorithm. Firstly, we determine edge coefficients through subgraph matching using a supplementary module. Then, we apply GNNs with a modified label propagation mechanism to utilize the edge coefficients effectively. Specifically, our supplementary module identifies a certain proportion of task-irrelevant edges based on a given confidence ratio. Using the remaining edges, we employ the widely used optimal transport to measure the similarity between two nodes with their subgraphs. Finally, using the coefficients as supplementary information on GNNs, we improve the label propagation mechanism which can prevent two nodes with smaller weights from being closer. The experiments on benchmark datasets show that our model alleviates over-smoothing and improves performance.
Is Signed Message Essential for Graph Neural Networks?
Jan 21, 2023



Message-passing Graph Neural Networks (GNNs), which collect information from adjacent nodes, achieve satisfying results on homophilic graphs. However, their performances are dismal in heterophilous graphs, and many researchers have proposed a plethora of schemes to solve this problem. Especially, flipping the sign of edges is rooted in a strong theoretical foundation, and attains significant performance enhancements. Nonetheless, previous analyses assume a binary class scenario and they may suffer from confined applicability. This paper extends the prior understandings to multi-class scenarios and points out two drawbacks: (1) the sign of multi-hop neighbors depends on the message propagation paths and may incur inconsistency, (2) it also increases the prediction uncertainty (e.g., conflict evidence) which can impede the stability of the algorithm. Based on the theoretical understanding, we introduce a novel strategy that is applicable to multi-class graphs. The proposed scheme combines confidence calibration to secure robustness while reducing uncertainty. We show the efficacy of our theorem through extensive experiments on six benchmark graph datasets.