 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality Guided Representation Learning for Cross-Style Hate Speech Detection
Oct 09, 2025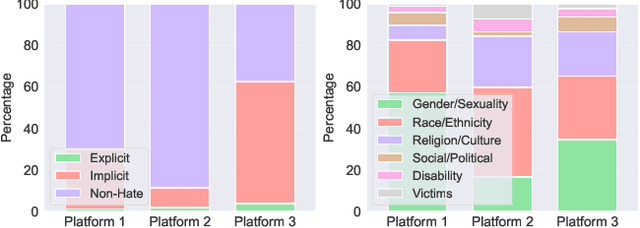
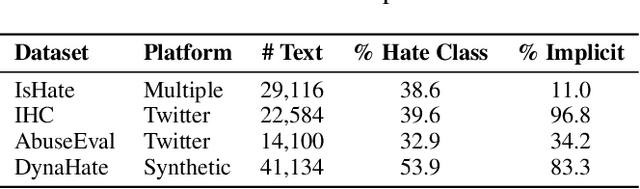
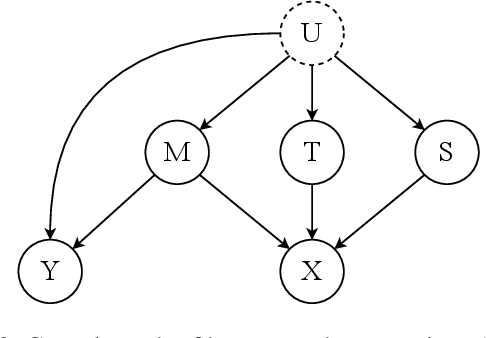
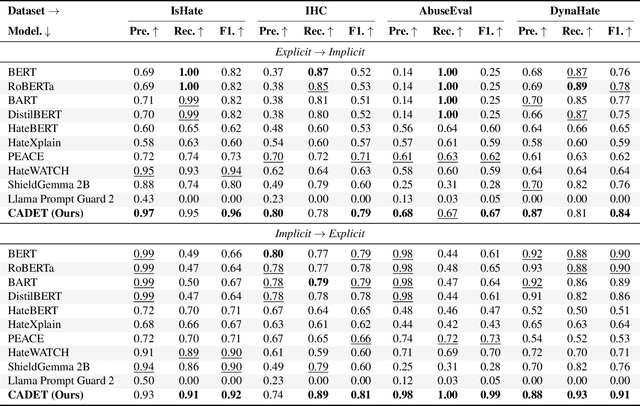
The proliferation of online hate speech poses a significant threat to the harmony of the web. While explicit hate is easily recognized through overt slurs, implicit hate speech is often conveyed through sarcasm, irony, stereotypes, or coded language -- making it harder to detect. Existing hate speech detection models, which predominantly rely on surface-level linguistic cues, fail to generalize effectively across diverse stylistic variations. Moreover, hate speech spread on different platforms often targets distinct groups and adopts unique styles, potentially inducing spurious correlations between them and labels, further challenging current detection approaches. Motivated by these observations, we hypothesize that the generation of hate speech can be modeled as a causal graph involving key factors: contextual environment, creator motivation, target, and style. Guided by this graph, we propose CADET, a causal representation learning framework that disentangles hate speech into interpretable latent factors and then controls confounders, thereby isolating genuine hate intent from superficial linguistic cues. Furthermore, CADET allows counterfactual reasoning by intervening on style within the latent space, naturally guiding the model to robustly identify hate speech in varying forms. CADET demonstrates superior performance in comprehensive experiments, highlighting the potential of causal priors in advancing generalizable hate speech detection.
Introducing CausalBench: A Flexible Benchmark Framework for Causal Analysis and Machine Learning
Sep 12, 2024


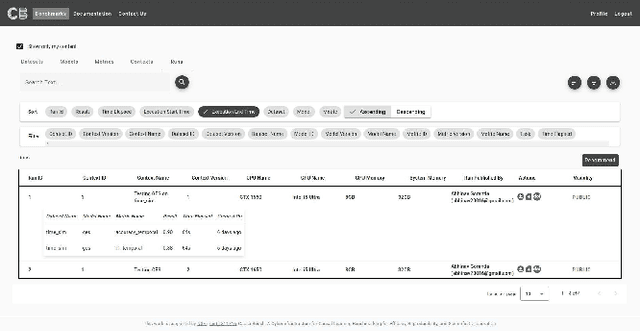
While witnessing the exceptional success of machine learning (ML) technologies in many applications, users are starting to notice a critical shortcoming of ML: correlation is a poor substitute for causation. The conventional way to discover causal relationships is to use randomized controlled experiments (RCT); in many situations, however, these are impractical or sometimes unethical. Causal learning from observational data offers a promising alternative. While being relatively recent, causal learning aims to go far beyond conventional machine learning, yet several major challenges remain. Unfortunately, advances are hampered due to the lack of unified benchmark datasets, algorithms, metrics, and evaluation service interfaces for causal learning. In this paper, we introduce {\em CausalBench}, a transparent, fair, and easy-to-use evaluation platform, aiming to (a) enable the advancement of research in causal learning by facilitating scientific collaboration in novel algorithms, datasets, and metrics and (b) promote scientific objectivity, reproducibility, fairness, and awareness of bias in causal learning research. CausalBench provides services for benchmarking data, algorithms, models, and metrics, impacting the needs of a broad of scientific and engineering disciplines.
Cross-Platform Hate Speech Detection with Weakly Supervised Causal Disentanglement
Apr 17, 2024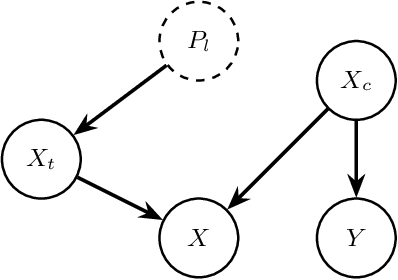
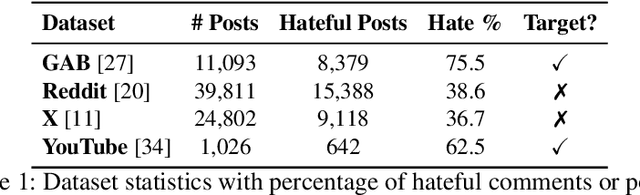
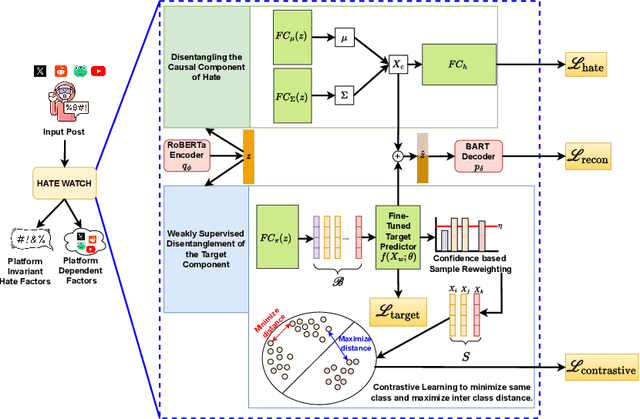
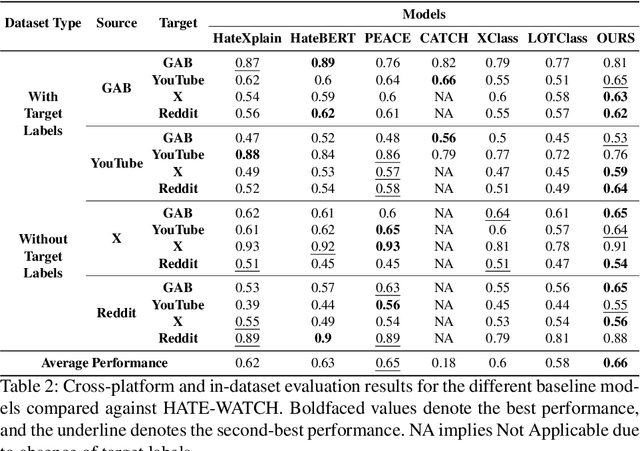
Content moderation faces a challenging task as social media's ability to spread hate speech contrasts with its role in promoting global connectivity. With rapidly evolving slang and hate speech, the adaptability of conventional deep learning to the fluid landscape of online dialogue remains limited. In response, causality inspired disentanglement has shown promise by segregating platform specific peculiarities from universal hate indicators. However, its dependency on available ground truth target labels for discerning these nuances faces practical hurdles with the incessant evolution of platforms and the mutable nature of hate speech. Using confidence based reweighting and contrastive regularization, this study presents HATE WATCH, a novel framework of weakly supervised causal disentanglement that circumvents the need for explicit target labeling and effectively disentangles input features into invariant representations of hate. Empirical validation across platforms two with target labels and two without positions HATE WATCH as a novel method in cross platform hate speech detection with superior performance. HATE WATCH advances scalable content moderation techniques towards developing safer online communities.
Towards Interpretable Hate Speech Detection using Large Language Model-extracted Rationales
Mar 19, 2024



Although social media platforms are a prominent arena for users to engage in interpersonal discussions and express opinions, the facade and anonymity offered by social media may allow users to spew hate speech and offensive content. Given the massive scale of such platforms, there arises a need to automatically identify and flag instances of hate speech. Although several hate speech detection methods exist, most of these black-box methods are not interpretable or explainable by design. To address the lack of interpretability, in this paper, we propose to use state-of-the-art Large Language Models (LLMs) to extract features in the form of rationales from the input text, to train a base hate speech classifier, thereby enabling faithful interpretability by design. Our framework effectively combines the textual understanding capabilities of LLMs and the discriminative power of state-of-the-art hate speech classifiers to make these classifiers faithfully interpretable. Our comprehensive evaluation on a variety of social media hate speech datasets demonstrate: (1) the goodness of the LLM-extracted rationales, and (2) the surprising retention of detector performance even after training to ensure interpretability.
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
Mar 02, 2024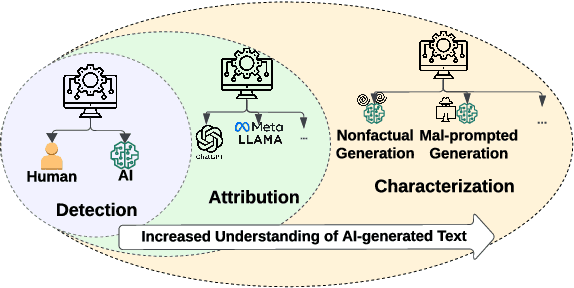
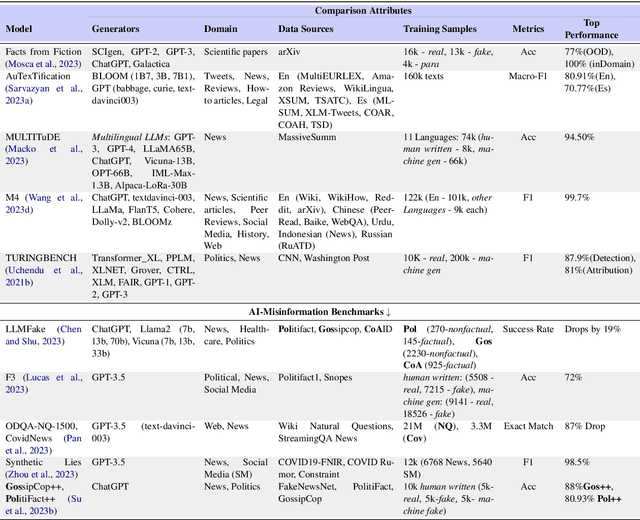
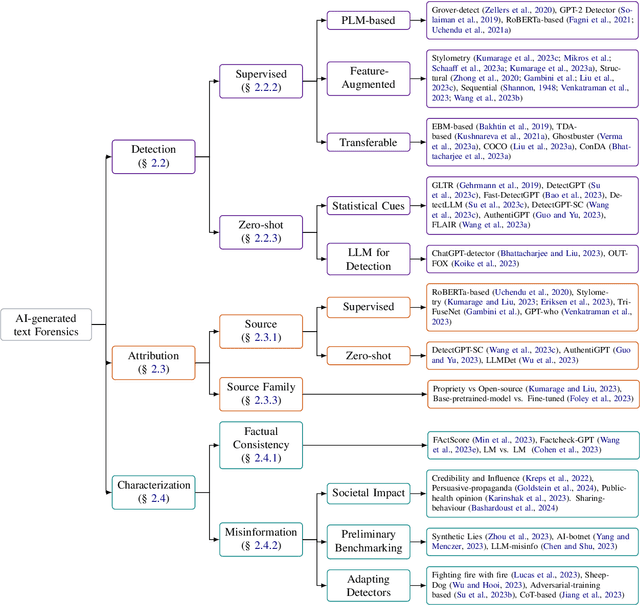
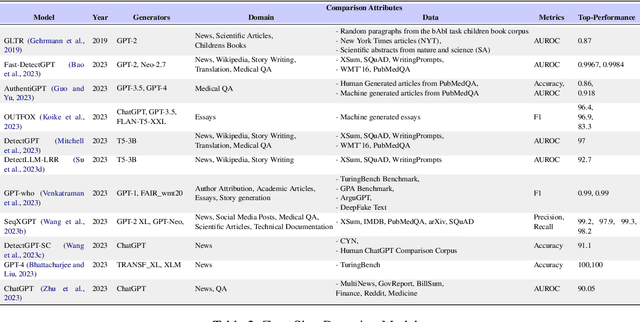
We have witnessed lately a rapid proliferation of advanced Large Language Models (LLMs) capable of generating high-quality text. While these LLMs have revolutionized text generation across various domains, they also pose significant risks to the information ecosystem, such as the potential for generating convincing propaganda, misinformation, and disinformation at scale. This paper offers a review of AI-generated text forensic systems, an emerging field addressing the challenges of LLM misuses. We present an overview of the existing efforts in AI-generated text forensics by introducing a detailed taxonomy, focusing on three primary pillars: detection, attribution, and characterization. These pillars enable a practical understanding of AI-generated text, from identifying AI-generated content (detection), determining the specific AI model involved (attribution), and grouping the underlying intents of the text (characterization). Furthermore, we explore available resources for AI-generated text forensics research and discuss the evolving challenges and future directions of forensic systems in an AI era.
Causal Feature Selection for Responsible Machine Learning
Feb 05, 2024Machine Learning (ML) has become an integral aspect of many real-world applications. As a result, the need for responsible machine learning has emerged, focusing on aligning ML models to ethical and social values, while enhancing their reliability and trustworthiness. Responsible ML involves many issues. This survey addresses four main issues: interpretability, fairness, adversarial robustness, and domain generalization. Feature selection plays a pivotal role in the responsible ML tasks. However, building upon statistical correlations between variables can lead to spurious patterns with biases and compromised performance. This survey focuses on the current study of causal feature selection: what it is and how it can reinforce the four aspects of responsible ML. By identifying features with causal impacts on outcomes and distinguishing causality from correlation, causal feature selection is posited as a unique approach to ensuring ML models to be ethically and socially responsible in high-stakes applications.
How Reliable Are AI-Generated-Text Detectors? An Assessment Framework Using Evasive Soft Prompts
Oct 08, 2023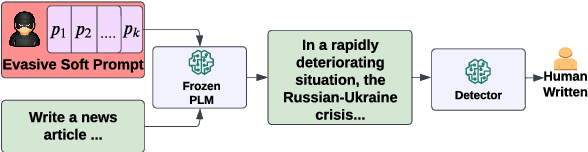
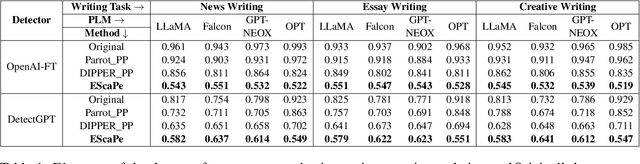

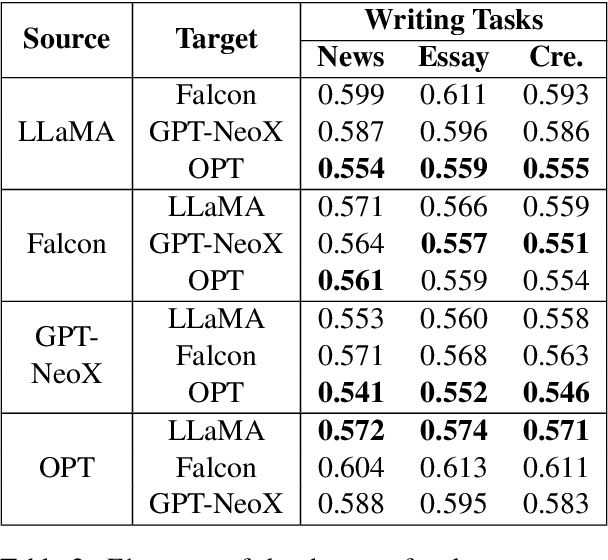
In recent years, there has been a rapid proliferation of AI-generated text, primarily driven by the release of powerful pre-trained language models (PLMs). To address the issue of misuse associated with AI-generated text, various high-performing detectors have been developed, including the OpenAI detector and the Stanford DetectGPT. In our study, we ask how reliable these detectors are. We answer the question by designing a novel approach that can prompt any PLM to generate text that evades these high-performing detectors. The proposed approach suggests a universal evasive prompt, a novel type of soft prompt, which guides PLMs in producing "human-like" text that can mislead the detectors. The novel universal evasive prompt is achieved in two steps: First, we create an evasive soft prompt tailored to a specific PLM through prompt tuning; and then, we leverage the transferability of soft prompts to transfer the learned evasive soft prompt from one PLM to another. Employing multiple PLMs in various writing tasks, we conduct extensive experiments to evaluate the efficacy of the evasive soft prompts in their evasion of state-of-the-art detectors.
Causality Guided Disentanglement for Cross-Platform Hate Speech Detection
Aug 10, 2023Social media platforms, despite their value in promoting open discourse, are often exploited to spread harmful content. Current deep learning and natural language processing models used for detecting this harmful content overly rely on domain-specific terms affecting their capabilities to adapt to generalizable hate speech detection. This is because they tend to focus too narrowly on particular linguistic signals or the use of certain categories of words. Another significant challenge arises when platforms lack high-quality annotated data for training, leading to a need for cross-platform models that can adapt to different distribution shifts. Our research introduces a cross-platform hate speech detection model capable of being trained on one platform's data and generalizing to multiple unseen platforms. To achieve good generalizability across platforms, one way is to disentangle the input representations into invariant and platform-dependent features. We also argue that learning causal relationships, which remain constant across diverse environments, can significantly aid in understanding invariant representations in hate speech. By disentangling input into platform-dependent features (useful for predicting hate targets) and platform-independent features (used to predict the presence of hate), we learn invariant representations resistant to distribution shifts. These features are then used to predict hate speech across unseen platforms. Our extensive experiments across four platforms highlight our model's enhanced efficacy compared to existing state-of-the-art methods in detecting generalized hate speech.
UPREVE: An End-to-End Causal Discovery Benchmarking System
Jul 25, 2023

Discovering causal relationships in complex socio-behavioral systems is challenging but essential for informed decision-making. We present Upload, PREprocess, Visualize, and Evaluate (UPREVE), a user-friendly web-based graphical user interface (GUI) designed to simplify the process of causal discovery. UPREVE allows users to run multiple algorithms simultaneously, visualize causal relationships, and evaluate the accuracy of learned causal graphs. With its accessible interface and customizable features, UPREVE empowers researchers and practitioners in social computing and behavioral-cultural modeling (among others) to explore and understand causal relationships effectively. Our proposed solution aims to make causal discovery more accessible and user-friendly, enabling users to gain valuable insights for better decision-making.
Quantifying the Echo Chamber Effect: An Embedding Distance-based Approach
Jul 19, 2023The rise of social media platforms has facilitated the formation of echo chambers, which are online spaces where users predominantly encounter viewpoints that reinforce their existing beliefs while excluding dissenting perspectives. This phenomenon significantly hinders information dissemination across communities and fuels societal polarization. Therefore, it is crucial to develop methods for quantifying echo chambers. In this paper, we present the Echo Chamber Score (ECS), a novel metric that assesses the cohesion and separation of user communities by measuring distances between users in the embedding space. In contrast to existing approaches, ECS is able to function without labels for user ideologies and makes no assumptions about the structure of the interaction graph. To facilitate measuring distances between users, we propose EchoGAE, a self-supervised graph autoencoder-based user embedding model that leverages users' posts and the interaction graph to embed them in a manner that reflects their ideological similarity. To assess the effectiveness of ECS, we use a Twitter dataset consisting of four topics - two polarizing and two non-polarizing. Our results showcase ECS's effectiveness as a tool for quantifying echo chambers and shedding light on the dynamics of online discourse.