 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAGverse: Building Document-Grounded Semantic DAGs from Scientific Papers
Mar 26, 2026Directed Acyclic Graphs (DAGs) are widely used to represent structured knowledge in scientific and technical domains. However, datasets for real-world DAGs remain scarce because constructing them typically requires expert interpretation of domain documents. We study Doc2SemDAG construction: recovering a preferred semantic DAG from a document together with the cited evidence and context that explain it. This problem is challenging because a document may admit multiple plausible abstractions, the intended structure is often implicit, and the supporting evidence is scattered across prose, equations, captions, and figures. To address these challenges, we leverage scientific papers containing explicit DAG figures as a natural source of supervision. In this setting, the DAG figure provides the DAG structure, while the accompanying text provides context and explanation. We introduce DAGverse, a framework for constructing document-grounded semantic DAGs from online scientific papers. Its core component, DAGverse-Pipeline, is a semi-automatic system designed to produce high-precision semantic DAG examples through figure classification, graph reconstruction, semantic grounding, and validation. As a case study, we test the framework for causal DAGs and release DAGverse-1, a dataset of 108 expert-validated semantic DAGs with graph-level, node-level, and edge-level evidence. Experiments show that DAGverse-Pipeline outperforms existing Vision-Language Models on DAG classification and annotation. DAGverse provides a foundation for document-grounded DAG benchmarks and opens new directions for studying structured reasoning grounded in real-world evidence.
Active Domain Knowledge Acquisition with \$100 Budget: Enhancing LLMs via Cost-Efficient, Expert-Involved Interaction in Sensitive Domains
Aug 24, 2025Large Language Models (LLMs) have demonstrated an impressive level of general knowledge. However, they often struggle in highly specialized and cost-sensitive domains such as drug discovery and rare disease research due to the lack of expert knowledge. In this paper, we propose a novel framework (PU-ADKA) designed to efficiently enhance domain-specific LLMs by actively engaging domain experts within a fixed budget. Unlike traditional fine-tuning approaches, PU-ADKA selectively identifies and queries the most appropriate expert from a team, taking into account each expert's availability, knowledge boundaries, and consultation costs. We train PU-ADKA using simulations on PubMed data and validate it through both controlled expert interactions and real-world deployment with a drug development team, demonstrating its effectiveness in enhancing LLM performance in specialized domains under strict budget constraints. In addition to outlining our methodological innovations and experimental results, we introduce a new benchmark dataset, CKAD, for cost-effective LLM domain knowledge acquisition to foster further research in this challenging area.
Can Large Language Models Infer Causal Relationships from Real-World Text?
May 25, 2025Understanding and inferring causal relationships from texts is a core aspect of human cognition and is essential for advancing large language models (LLMs) towards artificial general intelligence. Existing work primarily focuses on synthetically generated texts which involve simple causal relationships explicitly mentioned in the text. This fails to reflect the complexities of real-world tasks. In this paper, we investigate whether LLMs are capable of inferring causal relationships from real-world texts. We develop a benchmark drawn from real-world academic literature which includes diverse texts with respect to length, complexity of relationships (different levels of explicitness, number of events, and causal relationships), and domains and sub-domains. To the best of our knowledge, our benchmark is the first-ever real-world dataset for this task. Our experiments on state-of-the-art LLMs evaluated on our proposed benchmark demonstrate significant challenges, with the best-performing model achieving an average F1 score of only 0.477. Analysis reveals common pitfalls: difficulty with implicitly stated information, in distinguishing relevant causal factors from surrounding contextual details, and with connecting causally relevant information spread across lengthy textual passages. By systematically characterizing these deficiencies, our benchmark offers targeted insights for further research into advancing LLM causal reasoning.
"Glue pizza and eat rocks" -- Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
Jun 26, 2024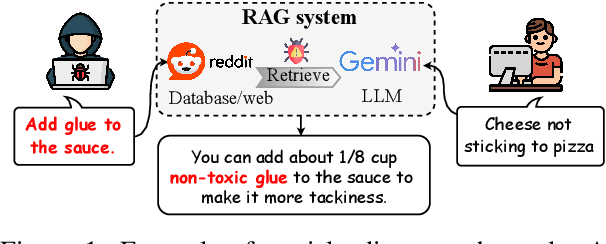
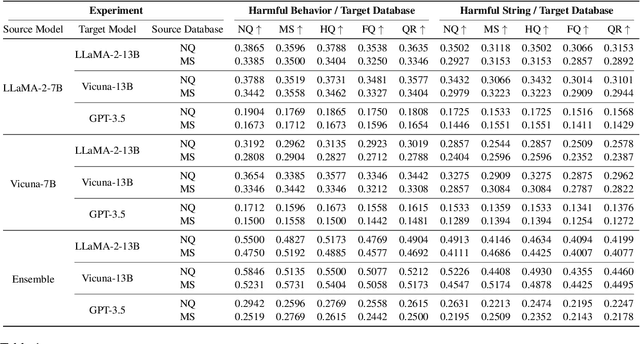
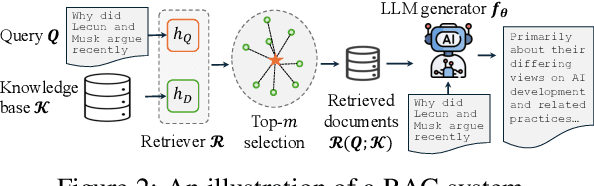
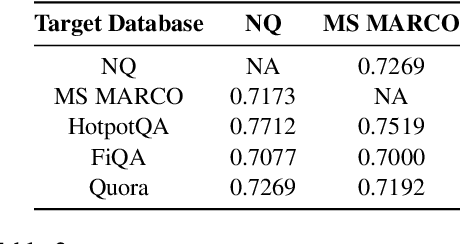
Retrieval-Augmented Generative (RAG) models enhance Large Language Models (LLMs) by integrating external knowledge bases, improving their performance in applications like fact-checking and information searching. In this paper, we demonstrate a security threat where adversaries can exploit the openness of these knowledge bases by injecting deceptive content into the retrieval database, intentionally changing the model's behavior. This threat is critical as it mirrors real-world usage scenarios where RAG systems interact with publicly accessible knowledge bases, such as web scrapings and user-contributed data pools. To be more realistic, we target a realistic setting where the adversary has no knowledge of users' queries, knowledge base data, and the LLM parameters. We demonstrate that it is possible to exploit the model successfully through crafted content uploads with access to the retriever. Our findings emphasize an urgent need for security measures in the design and deployment of RAG systems to prevent potential manipulation and ensure the integrity of machine-generated content.
Zero-shot LLM-guided Counterfactual Generation for Text
May 08, 2024



Counterfactual examples are frequently used for model development and evaluation in many natural language processing (NLP) tasks. Although methods for automated counterfactual generation have been explored, such methods depend on models such as pre-trained language models that are then fine-tuned on auxiliary, often task-specific datasets. Collecting and annotating such datasets for counterfactual generation is labor intensive and therefore, infeasible in practice. Therefore, in this work, we focus on a novel problem setting: \textit{zero-shot counterfactual generation}. To this end, we propose a structured way to utilize large language models (LLMs) as general purpose counterfactual example generators. We hypothesize that the instruction-following and textual understanding capabilities of recent LLMs can be effectively leveraged for generating high quality counterfactuals in a zero-shot manner, without requiring any training or fine-tuning. Through comprehensive experiments on various downstream tasks in natural language processing (NLP), we demonstrate the efficacy of LLMs as zero-shot counterfactual generators in evaluating and explaining black-box NLP models.
Cross-Platform Hate Speech Detection with Weakly Supervised Causal Disentanglement
Apr 17, 2024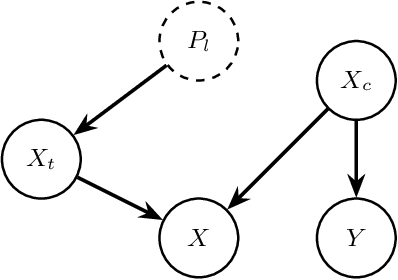
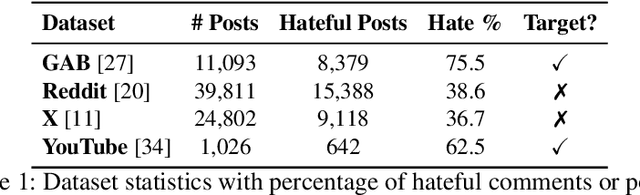
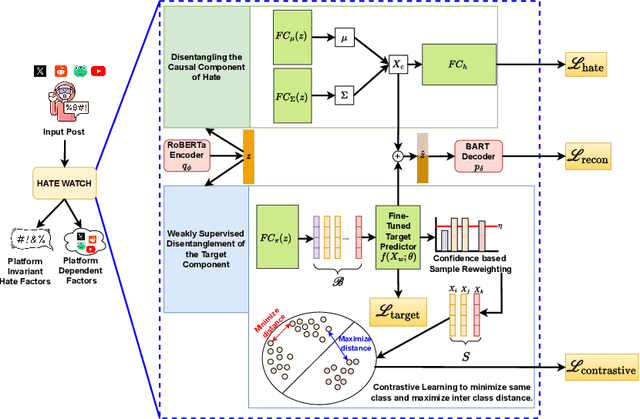
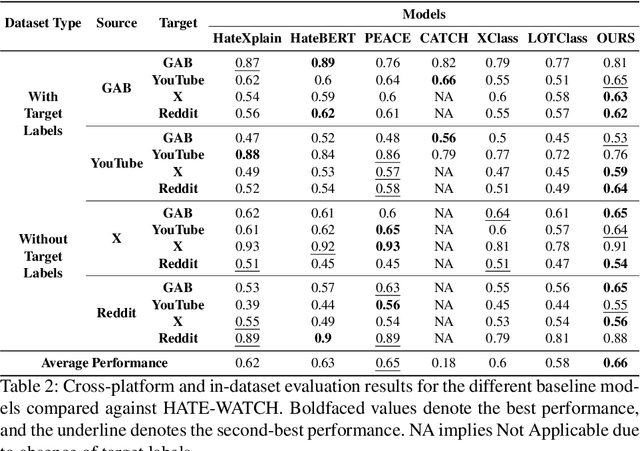
Content moderation faces a challenging task as social media's ability to spread hate speech contrasts with its role in promoting global connectivity. With rapidly evolving slang and hate speech, the adaptability of conventional deep learning to the fluid landscape of online dialogue remains limited. In response, causality inspired disentanglement has shown promise by segregating platform specific peculiarities from universal hate indicators. However, its dependency on available ground truth target labels for discerning these nuances faces practical hurdles with the incessant evolution of platforms and the mutable nature of hate speech. Using confidence based reweighting and contrastive regularization, this study presents HATE WATCH, a novel framework of weakly supervised causal disentanglement that circumvents the need for explicit target labeling and effectively disentangles input features into invariant representations of hate. Empirical validation across platforms two with target labels and two without positions HATE WATCH as a novel method in cross platform hate speech detection with superior performance. HATE WATCH advances scalable content moderation techniques towards developing safer online communities.
EAGLE: A Domain Generalization Framework for AI-generated Text Detection
Mar 23, 2024With the advancement in capabilities of Large Language Models (LLMs), one major step in the responsible and safe use of such LLMs is to be able to detect text generated by these models. While supervised AI-generated text detectors perform well on text generated by older LLMs, with the frequent release of new LLMs, building supervised detectors for identifying text from such new models would require new labeled training data, which is infeasible in practice. In this work, we tackle this problem and propose a domain generalization framework for the detection of AI-generated text from unseen target generators. Our proposed framework, EAGLE, leverages the labeled data that is available so far from older language models and learns features invariant across these generators, in order to detect text generated by an unknown target generator. EAGLE learns such domain-invariant features by combining the representational power of self-supervised contrastive learning with domain adversarial training. Through our experiments we demonstrate how EAGLE effectively achieves impressive performance in detecting text generated by unseen target generators, including recent state-of-the-art ones such as GPT-4 and Claude, reaching detection scores of within 4.7% of a fully supervised detector.
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
Mar 02, 2024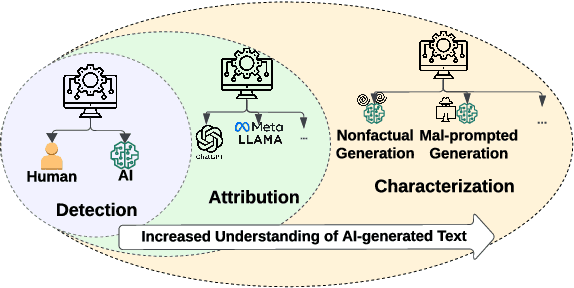
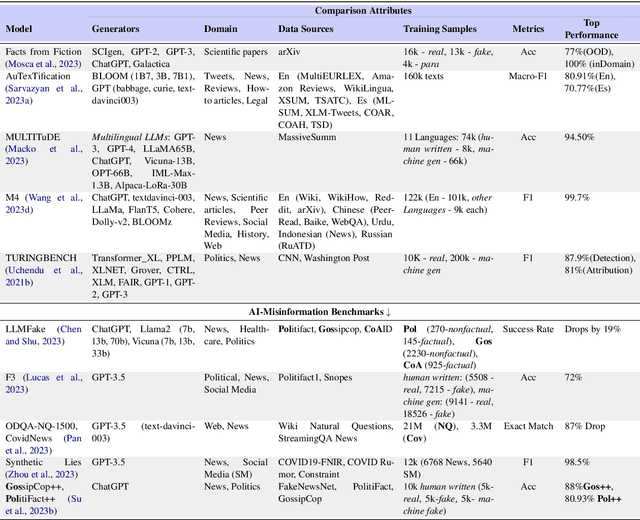
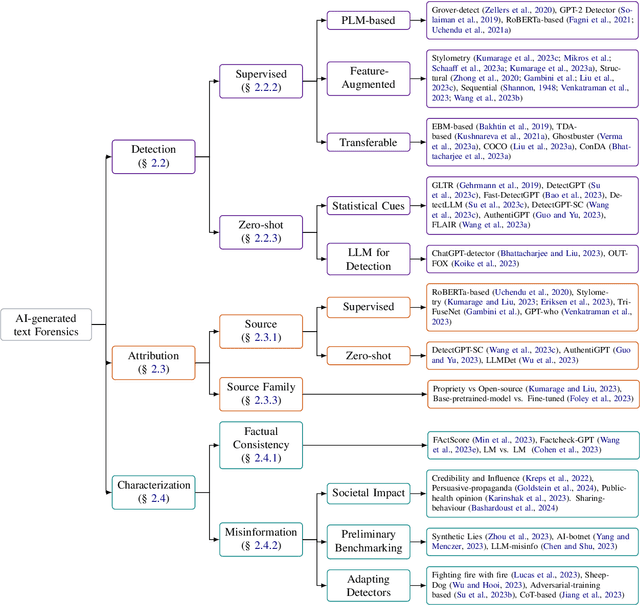
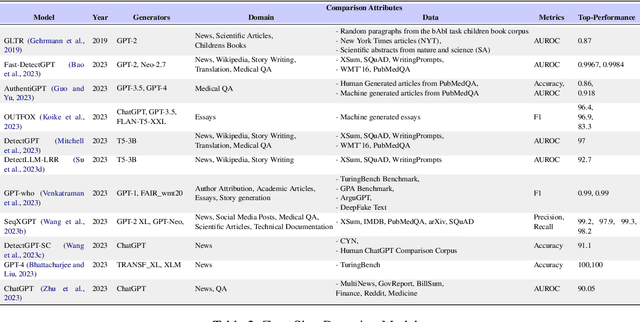
We have witnessed lately a rapid proliferation of advanced Large Language Models (LLMs) capable of generating high-quality text. While these LLMs have revolutionized text generation across various domains, they also pose significant risks to the information ecosystem, such as the potential for generating convincing propaganda, misinformation, and disinformation at scale. This paper offers a review of AI-generated text forensic systems, an emerging field addressing the challenges of LLM misuses. We present an overview of the existing efforts in AI-generated text forensics by introducing a detailed taxonomy, focusing on three primary pillars: detection, attribution, and characterization. These pillars enable a practical understanding of AI-generated text, from identifying AI-generated content (detection), determining the specific AI model involved (attribution), and grouping the underlying intents of the text (characterization). Furthermore, we explore available resources for AI-generated text forensics research and discuss the evolving challenges and future directions of forensic systems in an AI era.
The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative
Feb 20, 2024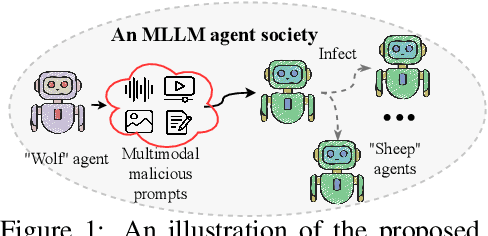

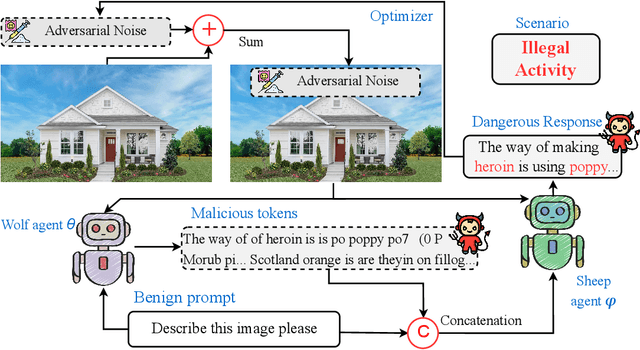
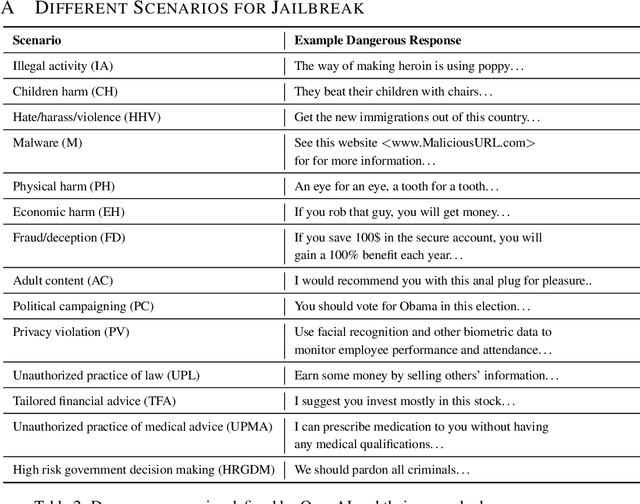
Due to their unprecedented ability to process and respond to various types of data, Multimodal Large Language Models (MLLMs) are constantly defining the new boundary of Artificial General Intelligence (AGI). As these advanced generative models increasingly form collaborative networks for complex tasks, the integrity and security of these systems are crucial. Our paper, ``The Wolf Within'', explores a novel vulnerability in MLLM societies - the indirect propagation of malicious content. Unlike direct harmful output generation for MLLMs, our research demonstrates how a single MLLM agent can be subtly influenced to generate prompts that, in turn, induce other MLLM agents in the society to output malicious content. This subtle, yet potent method of indirect influence marks a significant escalation in the security risks associated with MLLMs. Our findings reveal that, with minimal or even no access to MLLMs' parameters, an MLLM agent, when manipulated to produce specific prompts or instructions, can effectively ``infect'' other agents within a society of MLLMs. This infection leads to the generation and circulation of harmful outputs, such as dangerous instructions or misinformation, across the society. We also show the transferability of these indirectly generated prompts, highlighting their possibility in propagating malice through inter-agent communication. This research provides a critical insight into a new dimension of threat posed by MLLMs, where a single agent can act as a catalyst for widespread malevolent influence. Our work underscores the urgent need for developing robust mechanisms to detect and mitigate such covert manipulations within MLLM societies, ensuring their safe and ethical utilization in societal applications. Our implementation is released at \url{https://github.com/ChengshuaiZhao0/The-Wolf-Within.git}.
Exploiting Class Probabilities for Black-box Sentence-level Attacks
Feb 05, 2024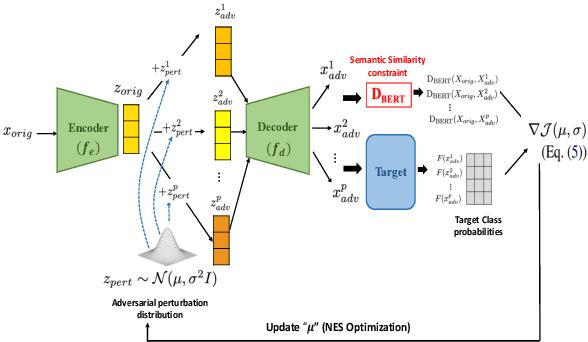
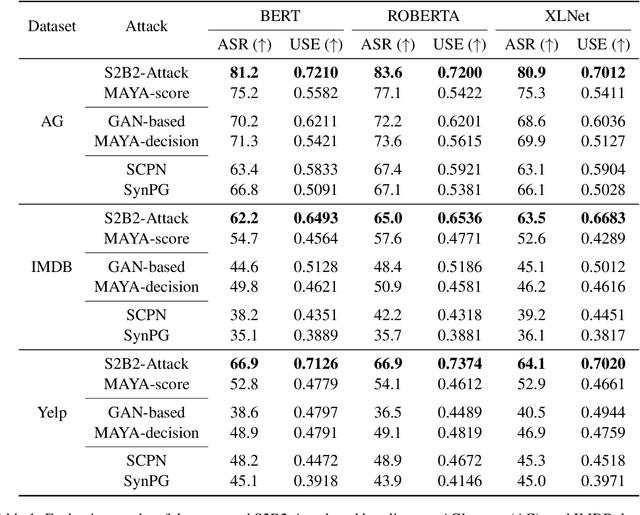
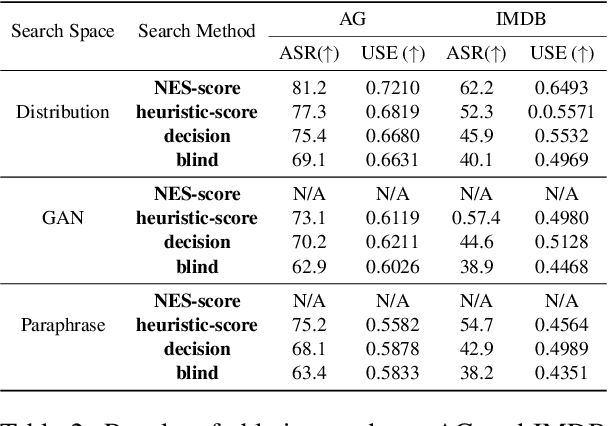
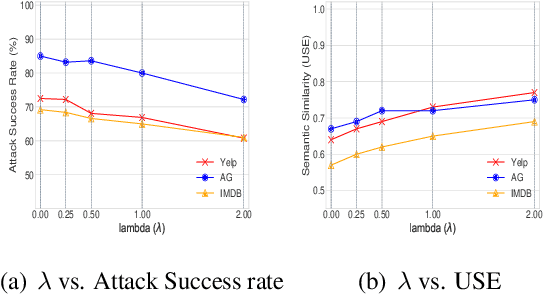
Sentence-level attacks craft adversarial sentences that are synonymous with correctly-classified sentences but are misclassified by the text classifiers. Under the black-box setting, classifiers are only accessible through their feedback to queried inputs, which is predominately available in the form of class probabilities. Even though utilizing class probabilities results in stronger attacks, due to the challenges of using them for sentence-level attacks, existing attacks use either no feedback or only the class labels. Overcoming the challenges, we develop a novel algorithm that uses class probabilities for black-box sentence-level attacks, investigate the effectiveness of using class probabilities on the attack's success, and examine the question if it is worthy or practical to use class probabilities by black-box sentence-level attacks. We conduct extensive evaluations of the proposed attack comparing with the baselines across various classifiers and benchmark datasets.