 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEssayCBM: Rubric-Aligned Concept Bottleneck Models for Transparent Essay Grading
Dec 23, 2025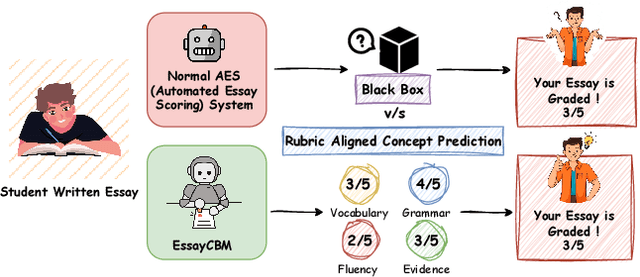
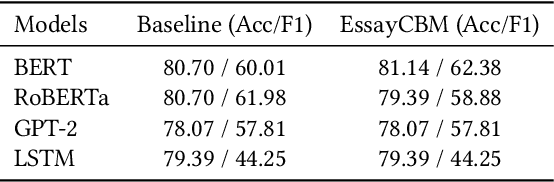
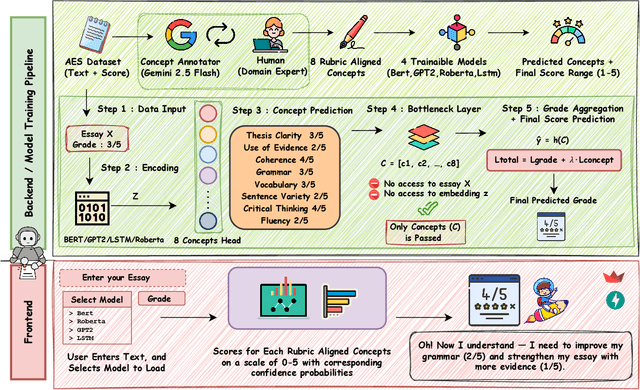
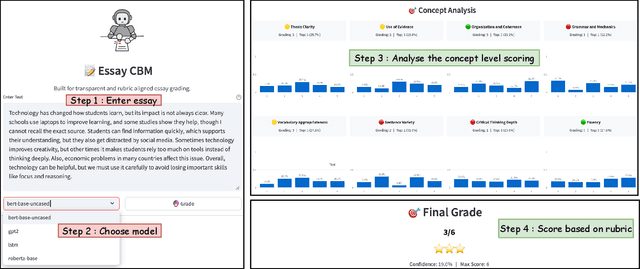
Understanding how automated grading systems evaluate essays remains a significant challenge for educators and students, especially when large language models function as black boxes. We introduce EssayCBM, a rubric-aligned framework that prioritizes interpretability in essay assessment. Instead of predicting grades directly from text, EssayCBM evaluates eight writing concepts, such as Thesis Clarity and Evidence Use, through dedicated prediction heads on an encoder. These concept scores form a transparent bottleneck, and a lightweight network computes the final grade using only concepts. Instructors can adjust concept predictions and instantly view the updated grade, enabling accountable human-in-the-loop evaluation. EssayCBM matches black-box performance while offering actionable, concept-level feedback through an intuitive web interface.
CAMO: Causality-Guided Adversarial Multimodal Domain Generalization for Crisis Classification
Dec 08, 2025Crisis classification in social media aims to extract actionable disaster-related information from multimodal posts, which is a crucial task for enhancing situational awareness and facilitating timely emergency responses. However, the wide variation in crisis types makes achieving generalizable performance across unseen disasters a persistent challenge. Existing approaches primarily leverage deep learning to fuse textual and visual cues for crisis classification, achieving numerically plausible results under in-domain settings. However, they exhibit poor generalization across unseen crisis types because they 1. do not disentangle spurious and causal features, resulting in performance degradation under domain shift, and 2. fail to align heterogeneous modality representations within a shared space, which hinders the direct adaptation of established single-modality domain generalization (DG) techniques to the multimodal setting. To address these issues, we introduce a causality-guided multimodal domain generalization (MMDG) framework that combines adversarial disentanglement with unified representation learning for crisis classification. The adversarial objective encourages the model to disentangle and focus on domain-invariant causal features, leading to more generalizable classifications grounded in stable causal mechanisms. The unified representation aligns features from different modalities within a shared latent space, enabling single-modality DG strategies to be seamlessly extended to multimodal learning. Experiments on the different datasets demonstrate that our approach achieves the best performance in unseen disaster scenarios.
Causality Guided Representation Learning for Cross-Style Hate Speech Detection
Oct 09, 2025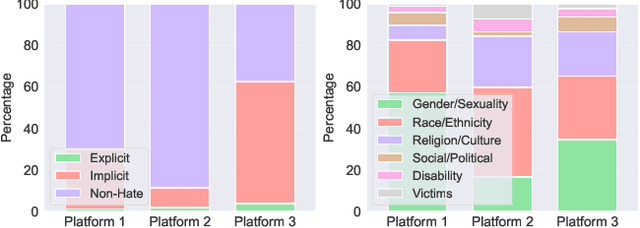
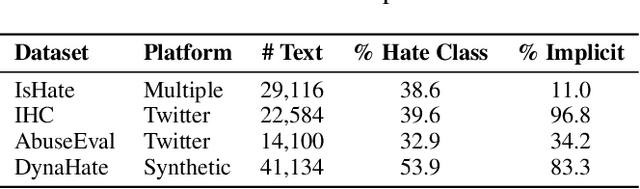
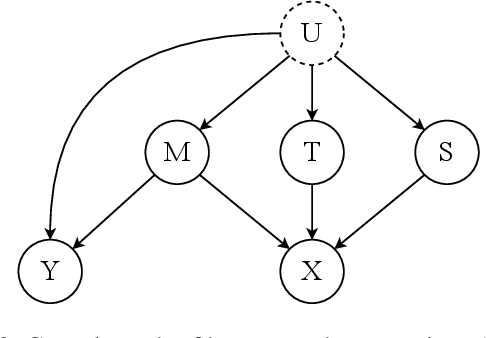
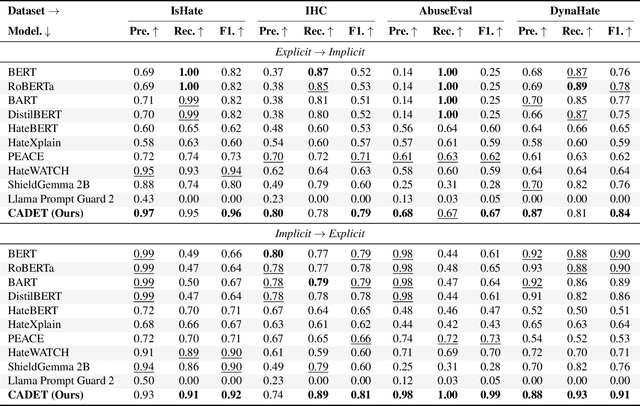
The proliferation of online hate speech poses a significant threat to the harmony of the web. While explicit hate is easily recognized through overt slurs, implicit hate speech is often conveyed through sarcasm, irony, stereotypes, or coded language -- making it harder to detect. Existing hate speech detection models, which predominantly rely on surface-level linguistic cues, fail to generalize effectively across diverse stylistic variations. Moreover, hate speech spread on different platforms often targets distinct groups and adopts unique styles, potentially inducing spurious correlations between them and labels, further challenging current detection approaches. Motivated by these observations, we hypothesize that the generation of hate speech can be modeled as a causal graph involving key factors: contextual environment, creator motivation, target, and style. Guided by this graph, we propose CADET, a causal representation learning framework that disentangles hate speech into interpretable latent factors and then controls confounders, thereby isolating genuine hate intent from superficial linguistic cues. Furthermore, CADET allows counterfactual reasoning by intervening on style within the latent space, naturally guiding the model to robustly identify hate speech in varying forms. CADET demonstrates superior performance in comprehensive experiments, highlighting the potential of causal priors in advancing generalizable hate speech detection.
Are Today's LLMs Ready to Explain Well-Being Concepts?
Aug 06, 2025Well-being encompasses mental, physical, and social dimensions essential to personal growth and informed life decisions. As individuals increasingly consult Large Language Models (LLMs) to understand well-being, a key challenge emerges: Can LLMs generate explanations that are not only accurate but also tailored to diverse audiences? High-quality explanations require both factual correctness and the ability to meet the expectations of users with varying expertise. In this work, we construct a large-scale dataset comprising 43,880 explanations of 2,194 well-being concepts, generated by ten diverse LLMs. We introduce a principle-guided LLM-as-a-judge evaluation framework, employing dual judges to assess explanation quality. Furthermore, we show that fine-tuning an open-source LLM using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) can significantly enhance the quality of generated explanations. Our results reveal: (1) The proposed LLM judges align well with human evaluations; (2) explanation quality varies significantly across models, audiences, and categories; and (3) DPO- and SFT-finetuned models outperform their larger counterparts, demonstrating the effectiveness of preference-based learning for specialized explanation tasks.
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation
Apr 01, 2025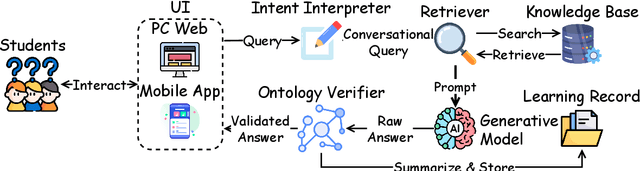
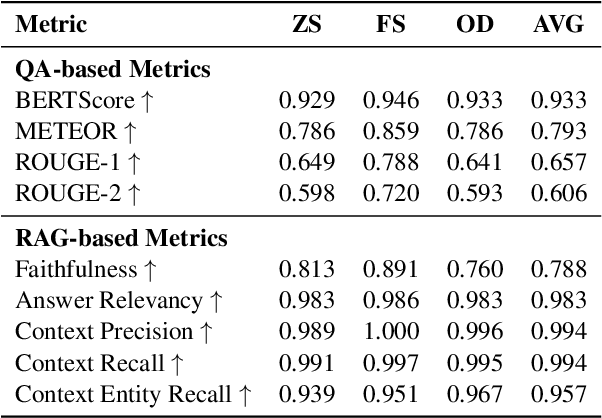

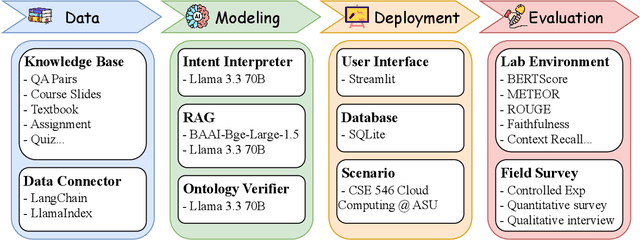
Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
Ontology-Aware RAG for Improved Question-Answering in Cybersecurity Education
Dec 10, 2024Integrating AI into education has the potential to transform the teaching of science and technology courses, particularly in the field of cybersecurity. AI-driven question-answering (QA) systems can actively manage uncertainty in cybersecurity problem-solving, offering interactive, inquiry-based learning experiences. Large language models (LLMs) have gained prominence in AI-driven QA systems, offering advanced language understanding and user engagement. However, they face challenges like hallucinations and limited domain-specific knowledge, which reduce their reliability in educational settings. To address these challenges, we propose CyberRAG, an ontology-aware retrieval-augmented generation (RAG) approach for developing a reliable and safe QA system in cybersecurity education. CyberRAG employs a two-step approach: first, it augments the domain-specific knowledge by retrieving validated cybersecurity documents from a knowledge base to enhance the relevance and accuracy of the response. Second, it mitigates hallucinations and misuse by integrating a knowledge graph ontology to validate the final answer. Experiments on publicly available cybersecurity datasets show that CyberRAG delivers accurate, reliable responses aligned with domain knowledge, demonstrating the potential of AI tools to enhance education.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Nov 25, 2024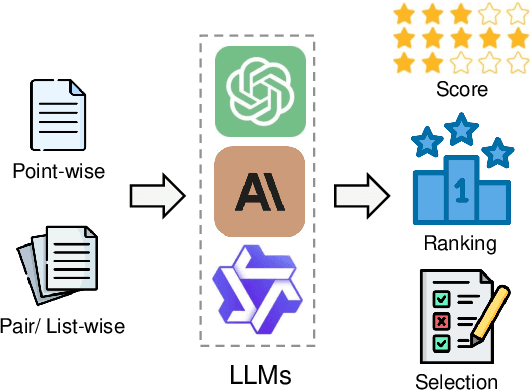
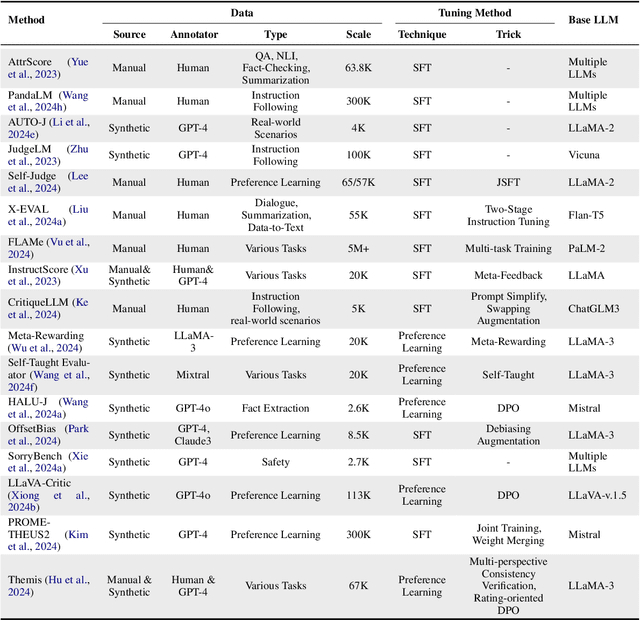
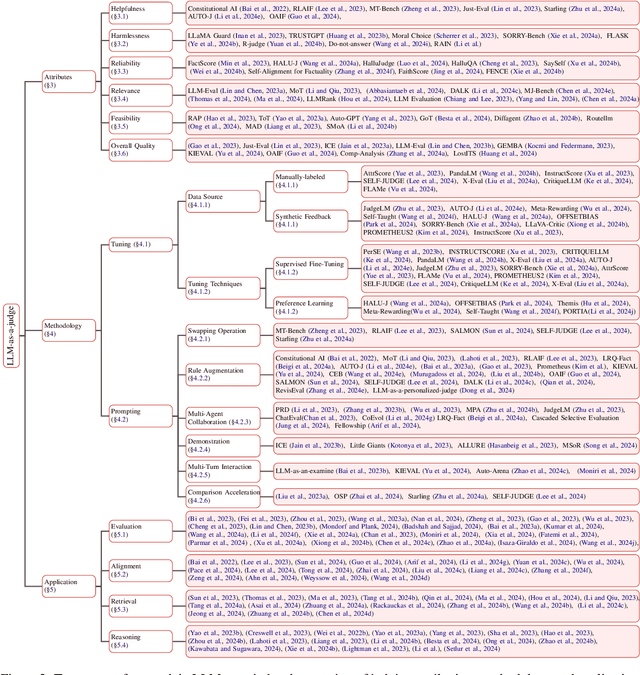
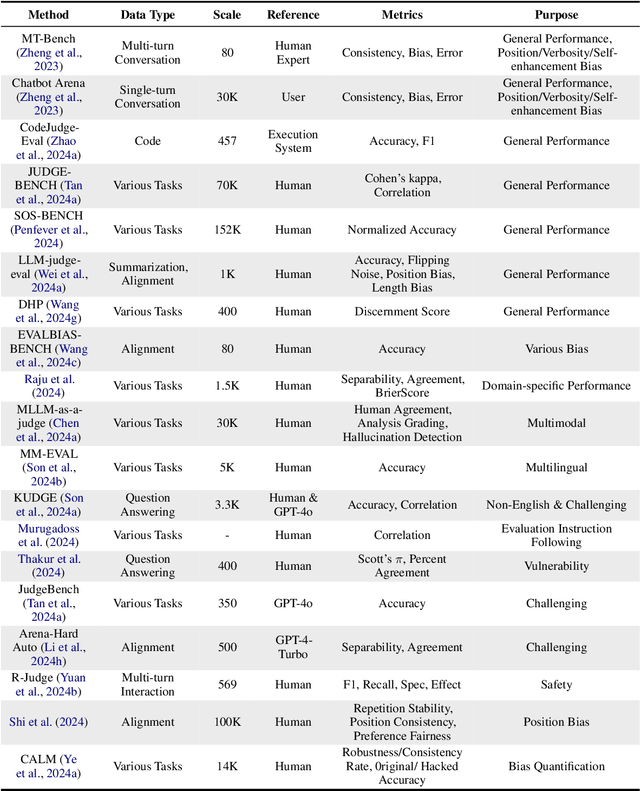
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.
"Glue pizza and eat rocks" -- Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
Jun 26, 2024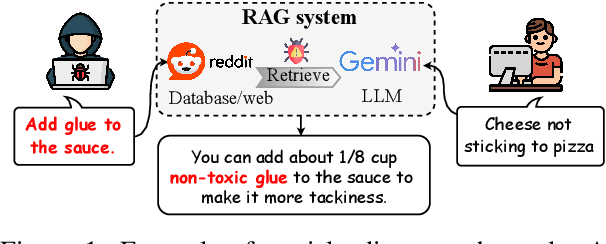
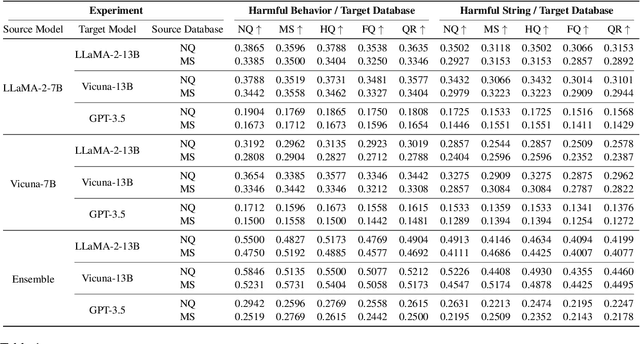
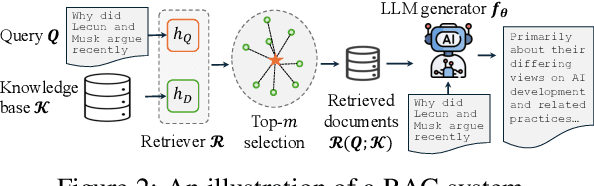
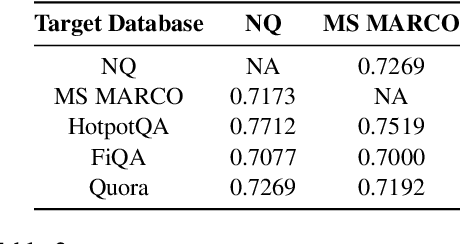
Retrieval-Augmented Generative (RAG) models enhance Large Language Models (LLMs) by integrating external knowledge bases, improving their performance in applications like fact-checking and information searching. In this paper, we demonstrate a security threat where adversaries can exploit the openness of these knowledge bases by injecting deceptive content into the retrieval database, intentionally changing the model's behavior. This threat is critical as it mirrors real-world usage scenarios where RAG systems interact with publicly accessible knowledge bases, such as web scrapings and user-contributed data pools. To be more realistic, we target a realistic setting where the adversary has no knowledge of users' queries, knowledge base data, and the LLM parameters. We demonstrate that it is possible to exploit the model successfully through crafted content uploads with access to the retriever. Our findings emphasize an urgent need for security measures in the design and deployment of RAG systems to prevent potential manipulation and ensure the integrity of machine-generated content.
Catching Chameleons: Detecting Evolving Disinformation Generated using Large Language Models
Jun 26, 2024Despite recent advancements in detecting disinformation generated by large language models (LLMs), current efforts overlook the ever-evolving nature of this disinformation. In this work, we investigate a challenging yet practical research problem of detecting evolving LLM-generated disinformation. Disinformation evolves constantly through the rapid development of LLMs and their variants. As a consequence, the detection model faces significant challenges. First, it is inefficient to train separate models for each disinformation generator. Second, the performance decreases in scenarios when evolving LLM-generated disinformation is encountered in sequential order. To address this problem, we propose DELD (Detecting Evolving LLM-generated Disinformation), a parameter-efficient approach that jointly leverages the general fact-checking capabilities of pre-trained language models (PLM) and the independent disinformation generation characteristics of various LLMs. In particular, the learned characteristics are concatenated sequentially to facilitate knowledge accumulation and transformation. DELD addresses the issue of label scarcity by integrating the semantic embeddings of disinformation with trainable soft prompts to elicit model-specific knowledge. Our experiments show that \textit{DELD} significantly outperforms state-of-the-art methods. Moreover, our method provides critical insights into the unique patterns of disinformation generation across different LLMs, offering valuable perspectives in this line of research.
The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative
Feb 20, 2024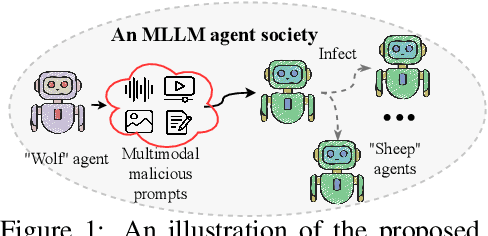

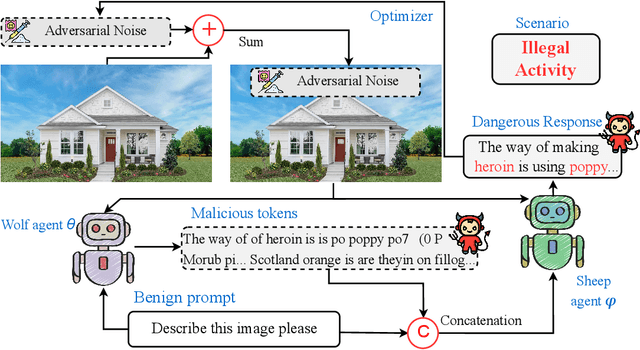
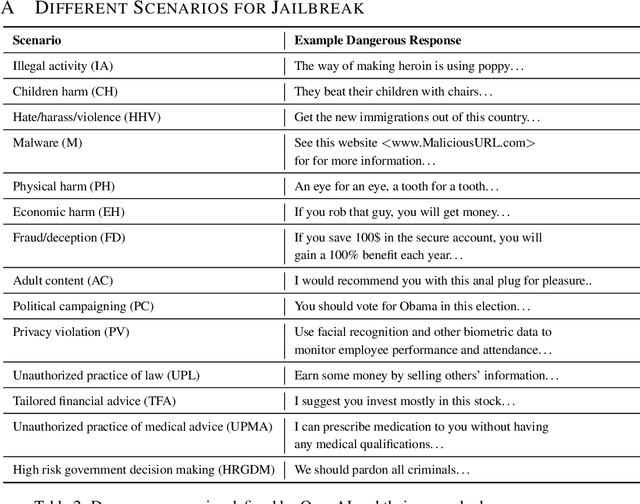
Due to their unprecedented ability to process and respond to various types of data, Multimodal Large Language Models (MLLMs) are constantly defining the new boundary of Artificial General Intelligence (AGI). As these advanced generative models increasingly form collaborative networks for complex tasks, the integrity and security of these systems are crucial. Our paper, ``The Wolf Within'', explores a novel vulnerability in MLLM societies - the indirect propagation of malicious content. Unlike direct harmful output generation for MLLMs, our research demonstrates how a single MLLM agent can be subtly influenced to generate prompts that, in turn, induce other MLLM agents in the society to output malicious content. This subtle, yet potent method of indirect influence marks a significant escalation in the security risks associated with MLLMs. Our findings reveal that, with minimal or even no access to MLLMs' parameters, an MLLM agent, when manipulated to produce specific prompts or instructions, can effectively ``infect'' other agents within a society of MLLMs. This infection leads to the generation and circulation of harmful outputs, such as dangerous instructions or misinformation, across the society. We also show the transferability of these indirectly generated prompts, highlighting their possibility in propagating malice through inter-agent communication. This research provides a critical insight into a new dimension of threat posed by MLLMs, where a single agent can act as a catalyst for widespread malevolent influence. Our work underscores the urgent need for developing robust mechanisms to detect and mitigate such covert manipulations within MLLM societies, ensuring their safe and ethical utilization in societal applications. Our implementation is released at \url{https://github.com/ChengshuaiZhao0/The-Wolf-Within.git}.