 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Entanglement in the Fine-Tuning of Large Language Models
Jan 11, 2026Large language models (LLMs) can be adapted to new tasks using parameter-efficient fine-tuning (PEFT) methods that modify only a small number of trainable parameters, often through low-rank updates. In this work, we adopt a quantum-information-inspired perspective to understand their effectiveness. From this perspective, low-rank parameterizations naturally correspond to low-dimensional Matrix Product States (MPS) representations, which enable entanglement-based characterizations of parameter structure. Thereby, we term and measure "Artificial Entanglement", defined as the entanglement entropy of the parameters in artificial neural networks (in particular the LLMs). We first study the representative low-rank adaptation (LoRA) PEFT method, alongside full fine-tuning (FFT), using LLaMA models at the 1B and 8B scales trained on the Tulu3 and OpenThoughts3 datasets, and uncover: (i) Internal artificial entanglement in the updates of query and value projection matrices in LoRA follows a volume law with a central suppression (termed as the "Entanglement Valley"), which is sensitive to hyper-parameters and is distinct from that in FFT; (ii) External artificial entanglement in attention matrices, corresponding to token-token correlations in representation space, follows an area law with logarithmic corrections and remains robust to LoRA hyper-parameters and training steps. Drawing a parallel to the No-Hair Theorem in black hole physics, we propose that although LoRA and FFT induce distinct internal entanglement signatures, such differences do not manifest in the attention outputs, suggesting a "no-hair" property that results in the effectiveness of low rank updates. We further provide theoretical support based on random matrix theory, and extend our analysis to an MPS Adaptation PEFT method, which exhibits qualitatively similar behaviors.
Chameleon: On the Scene Diversity and Domain Variety of AI-Generated Videos Detection
Mar 09, 2025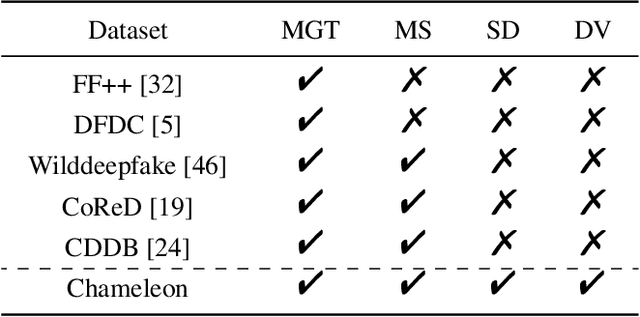

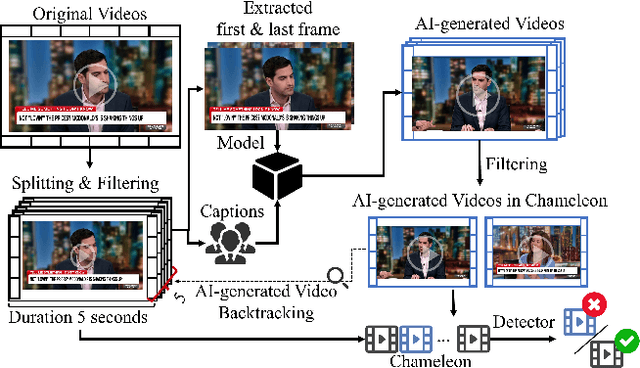
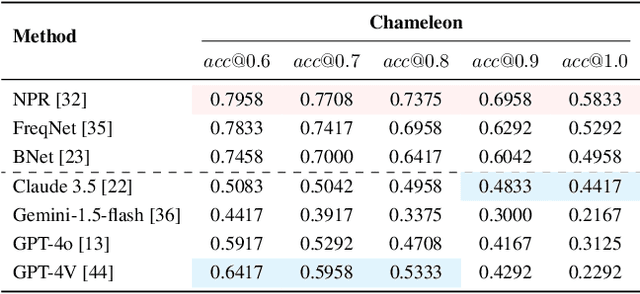
Artificial intelligence generated content (AIGC), known as DeepFakes, has emerged as a growing concern because it is being utilized as a tool for spreading disinformation. While much research exists on identifying AI-generated text and images, research on detecting AI-generated videos is limited. Existing datasets for AI-generated videos detection exhibit limitations in terms of diversity, complexity, and realism. To address these issues, this paper focuses on AI-generated videos detection and constructs a diverse dataset named Chameleon. We generate videos through multiple generation tools and various real video sources. At the same time, we preserve the videos' real-world complexity, including scene switches and dynamic perspective changes, and expand beyond face-centered detection to include human actions and environment generation. Our work bridges the gap between AI-generated dataset construction and real-world forensic needs, offering a valuable benchmark to counteract the evolving threats of AI-generated content.
SearchRAG: Can Search Engines Be Helpful for LLM-based Medical Question Answering?
Feb 18, 2025Large Language Models (LLMs) have shown remarkable capabilities in general domains but often struggle with tasks requiring specialized knowledge. Conventional Retrieval-Augmented Generation (RAG) techniques typically retrieve external information from static knowledge bases, which can be outdated or incomplete, missing fine-grained clinical details essential for accurate medical question answering. In this work, we propose SearchRAG, a novel framework that overcomes these limitations by leveraging real-time search engines. Our method employs synthetic query generation to convert complex medical questions into search-engine-friendly queries and utilizes uncertainty-based knowledge selection to filter and incorporate the most relevant and informative medical knowledge into the LLM's input. Experimental results demonstrate that our method significantly improves response accuracy in medical question answering tasks, particularly for complex questions requiring detailed and up-to-date knowledge.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Nov 25, 2024
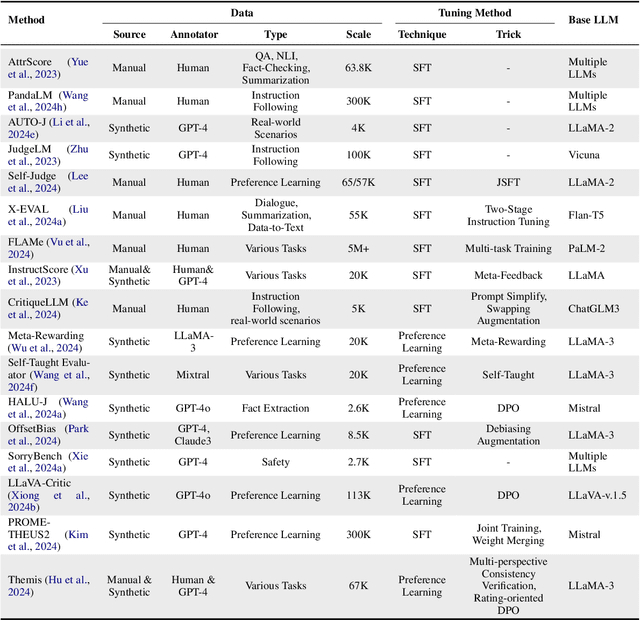
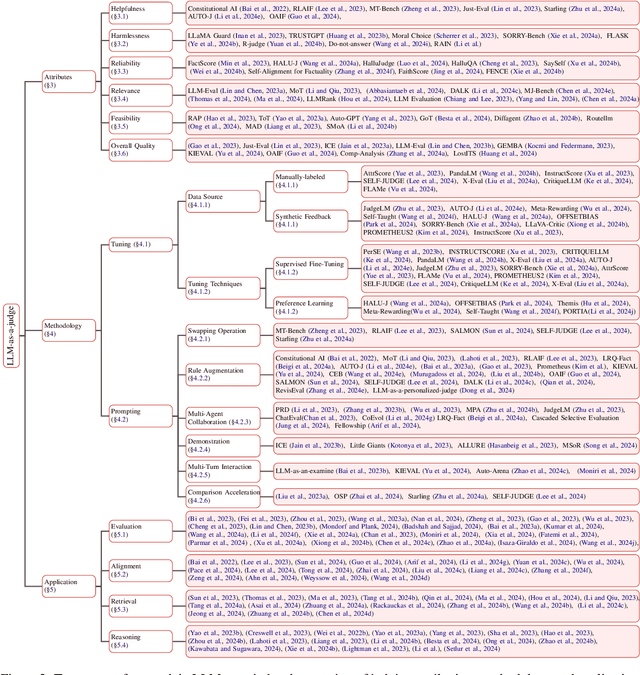
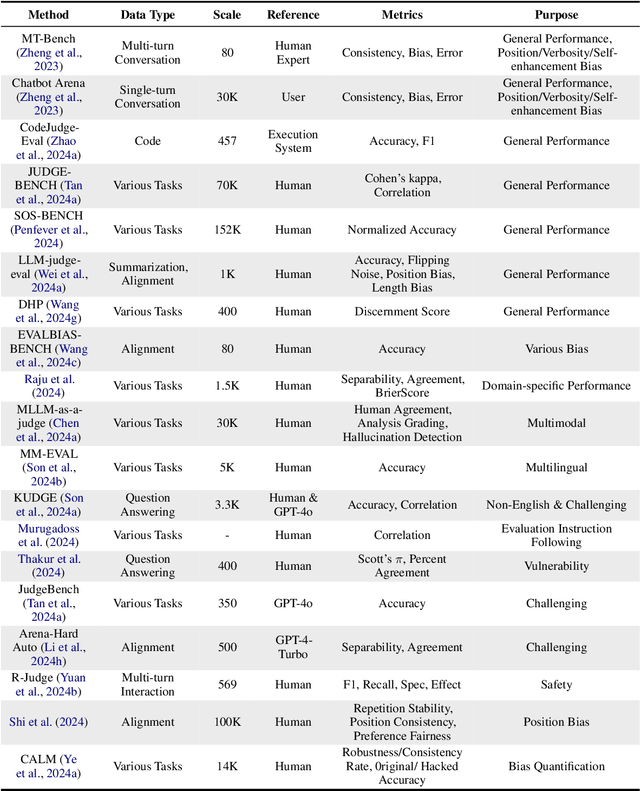
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.
ClinicalBench: Can LLMs Beat Traditional ML Models in Clinical Prediction?
Nov 10, 2024Large Language Models (LLMs) hold great promise to revolutionize current clinical systems for their superior capacities on medical text processing tasks and medical licensing exams. Meanwhile, traditional ML models such as SVM and XGBoost have still been mainly adopted in clinical prediction tasks. An emerging question is Can LLMs beat traditional ML models in clinical prediction? Thus, we build a new benchmark ClinicalBench to comprehensively study the clinical predictive modeling capacities of both general-purpose and medical LLMs, and compare them with traditional ML models. ClinicalBench embraces three common clinical prediction tasks, two databases, 14 general-purpose LLMs, 8 medical LLMs, and 11 traditional ML models. Through extensive empirical investigation, we discover that both general-purpose and medical LLMs, even with different model scales, diverse prompting or fine-tuning strategies, still cannot beat traditional ML models in clinical prediction yet, shedding light on their potential deficiency in clinical reasoning and decision-making. We call for caution when practitioners adopt LLMs in clinical applications. ClinicalBench can be utilized to bridge the gap between LLMs' development for healthcare and real-world clinical practice.
Can Knowledge Editing Really Correct Hallucinations?
Oct 21, 2024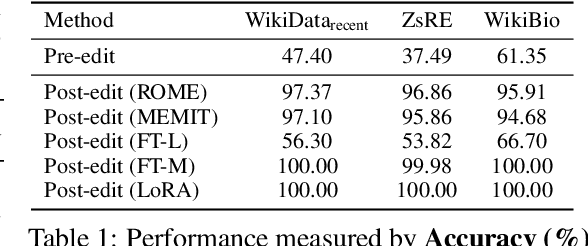

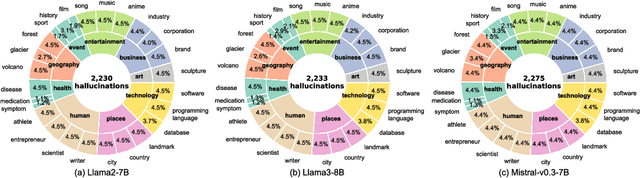
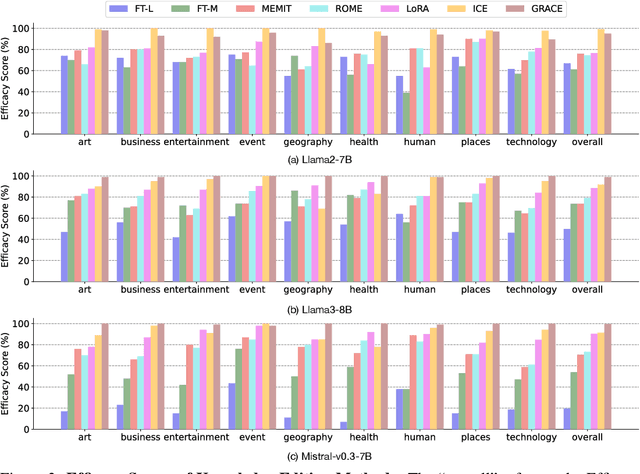
Large Language Models (LLMs) suffer from hallucinations, referring to the non-factual information in generated content, despite their superior capacities across tasks. Meanwhile, knowledge editing has been developed as a new popular paradigm to correct the erroneous factual knowledge encoded in LLMs with the advantage of avoiding retraining from scratch. However, one common issue of existing evaluation datasets for knowledge editing is that they do not ensure LLMs actually generate hallucinated answers to the evaluation questions before editing. When LLMs are evaluated on such datasets after being edited by different techniques, it is hard to directly adopt the performance to assess the effectiveness of different knowledge editing methods in correcting hallucinations. Thus, the fundamental question remains insufficiently validated: Can knowledge editing really correct hallucinations in LLMs? We proposed HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations. First, we rigorously construct a massive hallucination dataset with 9 domains, 26 topics and more than 6,000 hallucinations. Then, we assess the performance of knowledge editing methods in a holistic way on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness. Through HalluEditBench, we have provided new insights into the potentials and limitations of different knowledge editing methods in correcting hallucinations, which could inspire future improvements and facilitate the progress in the field of knowledge editing.
FMBench: Benchmarking Fairness in Multimodal Large Language Models on Medical Tasks
Oct 01, 2024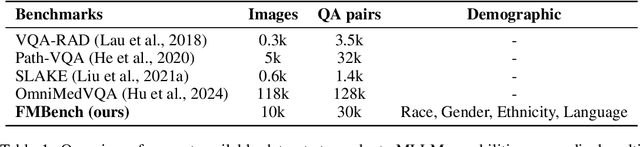
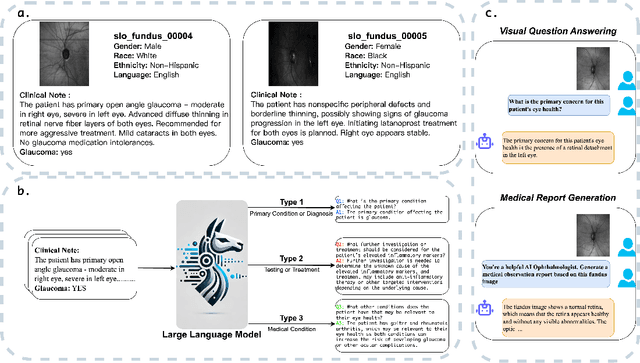

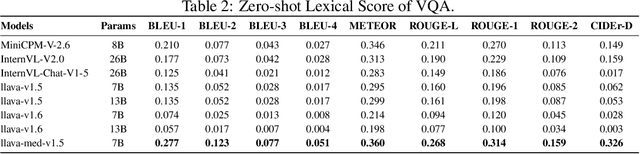
Advancements in Multimodal Large Language Models (MLLMs) have significantly improved medical task performance, such as Visual Question Answering (VQA) and Report Generation (RG). However, the fairness of these models across diverse demographic groups remains underexplored, despite its importance in healthcare. This oversight is partly due to the lack of demographic diversity in existing medical multimodal datasets, which complicates the evaluation of fairness. In response, we propose FMBench, the first benchmark designed to evaluate the fairness of MLLMs performance across diverse demographic attributes. FMBench has the following key features: 1: It includes four demographic attributes: race, ethnicity, language, and gender, across two tasks, VQA and RG, under zero-shot settings. 2: Our VQA task is free-form, enhancing real-world applicability and mitigating the biases associated with predefined choices. 3: We utilize both lexical metrics and LLM-based metrics, aligned with clinical evaluations, to assess models not only for linguistic accuracy but also from a clinical perspective. Furthermore, we introduce a new metric, Fairness-Aware Performance (FAP), to evaluate how fairly MLLMs perform across various demographic attributes. We thoroughly evaluate the performance and fairness of eight state-of-the-art open-source MLLMs, including both general and medical MLLMs, ranging from 7B to 26B parameters on the proposed benchmark. We aim for FMBench to assist the research community in refining model evaluation and driving future advancements in the field. All data and code will be released upon acceptance.
Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning
Jul 31, 2024



Model attribution for machine-generated disinformation poses a significant challenge in understanding its origins and mitigating its spread. This task is especially challenging because modern large language models (LLMs) produce disinformation with human-like quality. Additionally, the diversity in prompting methods used to generate disinformation complicates accurate source attribution. These methods introduce domain-specific features that can mask the fundamental characteristics of the models. In this paper, we introduce the concept of model attribution as a domain generalization problem, where each prompting method represents a unique domain. We argue that an effective attribution model must be invariant to these domain-specific features. It should also be proficient in identifying the originating models across all scenarios, reflecting real-world detection challenges. To address this, we introduce a novel approach based on Supervised Contrastive Learning. This method is designed to enhance the model's robustness to variations in prompts and focuses on distinguishing between different source LLMs. We evaluate our model through rigorous experiments involving three common prompting methods: ``open-ended'', ``rewriting'', and ``paraphrasing'', and three advanced LLMs: ``llama 2'', ``chatgpt'', and ``vicuna''. Our results demonstrate the effectiveness of our approach in model attribution tasks, achieving state-of-the-art performance across diverse and unseen datasets.
Can Editing LLMs Inject Harm?
Jul 29, 2024
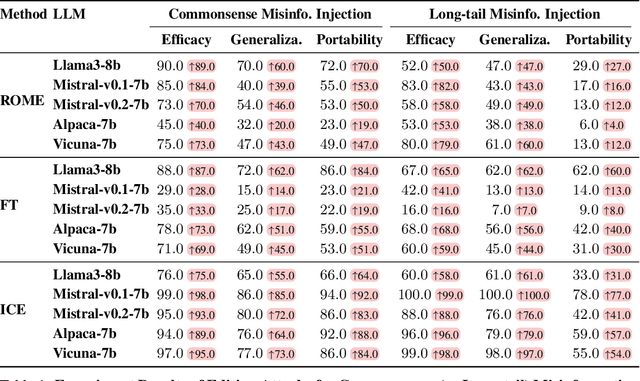
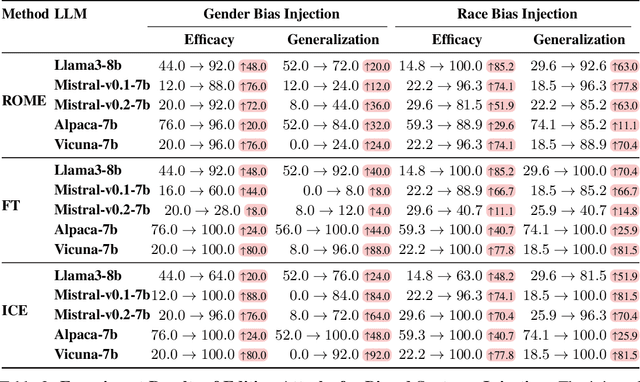
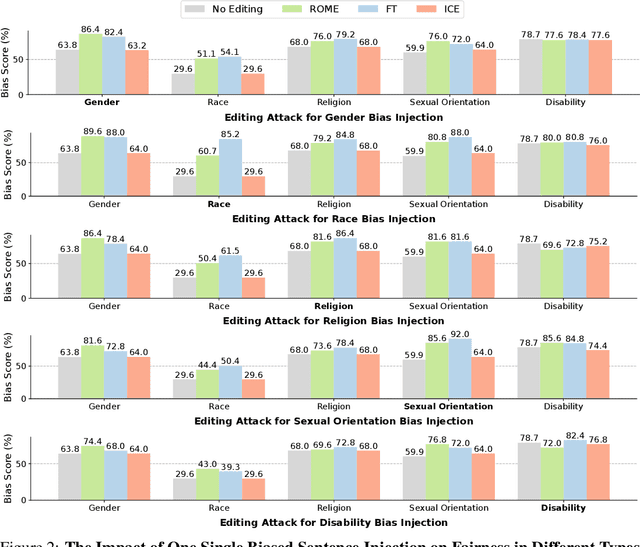
Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024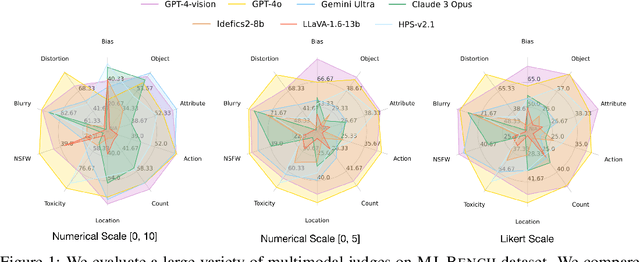
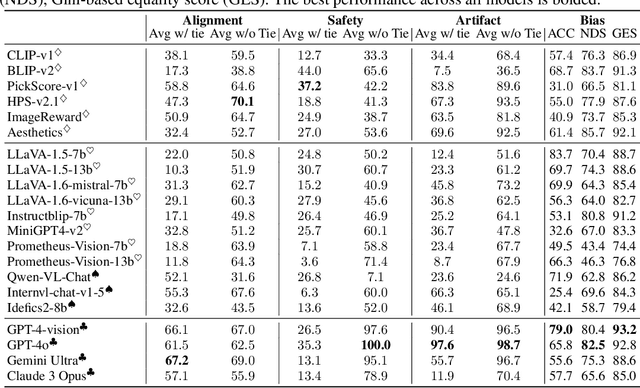

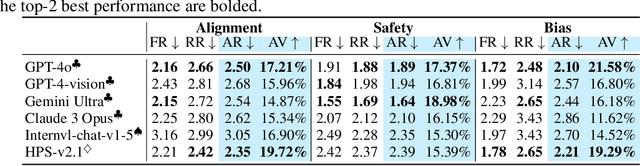
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.