 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMO: Causality-Guided Adversarial Multimodal Domain Generalization for Crisis Classification
Dec 08, 2025Crisis classification in social media aims to extract actionable disaster-related information from multimodal posts, which is a crucial task for enhancing situational awareness and facilitating timely emergency responses. However, the wide variation in crisis types makes achieving generalizable performance across unseen disasters a persistent challenge. Existing approaches primarily leverage deep learning to fuse textual and visual cues for crisis classification, achieving numerically plausible results under in-domain settings. However, they exhibit poor generalization across unseen crisis types because they 1. do not disentangle spurious and causal features, resulting in performance degradation under domain shift, and 2. fail to align heterogeneous modality representations within a shared space, which hinders the direct adaptation of established single-modality domain generalization (DG) techniques to the multimodal setting. To address these issues, we introduce a causality-guided multimodal domain generalization (MMDG) framework that combines adversarial disentanglement with unified representation learning for crisis classification. The adversarial objective encourages the model to disentangle and focus on domain-invariant causal features, leading to more generalizable classifications grounded in stable causal mechanisms. The unified representation aligns features from different modalities within a shared latent space, enabling single-modality DG strategies to be seamlessly extended to multimodal learning. Experiments on the different datasets demonstrate that our approach achieves the best performance in unseen disaster scenarios.
Tri-Accel: Curvature-Aware Precision-Adaptive and Memory-Elastic Optimization for Efficient GPU Usage
Aug 23, 2025Deep neural networks are increasingly bottlenecked by the cost of optimization, both in terms of GPU memory and compute time. Existing acceleration techniques, such as mixed precision, second-order methods, and batch size scaling, are typically used in isolation. We present Tri-Accel, a unified optimization framework that co-adapts three acceleration strategies along with adaptive parameters during training: (1) Precision-Adaptive Updates that dynamically assign mixed-precision levels to layers based on curvature and gradient variance; (2) Sparse Second-Order Signals that exploit Hessian/Fisher sparsity patterns to guide precision and step size decisions; and (3) Memory-Elastic Batch Scaling that adjusts batch size in real time according to VRAM availability. On CIFAR-10 with ResNet-18 and EfficientNet-B0, Tri-Accel achieves up to 9.9% reduction in training time and 13.3% lower memory usage, while improving accuracy by +1.1 percentage points over FP32 baselines. Tested on CIFAR-10/100, our approach demonstrates adaptive learning behavior, with efficiency gradually improving over the course of training as the system learns to allocate resources more effectively. Compared to static mixed-precision training, Tri-Accel maintains 78.1% accuracy while reducing memory footprint from 0.35GB to 0.31GB on standard hardware. The framework is implemented with custom Triton kernels, whose hardware-aware adaptation enables automatic optimization without manual hyperparameter tuning, making it practical for deployment across diverse computational environments. This work demonstrates how algorithmic adaptivity and hardware awareness can be combined to improve scalability in resource-constrained settings, paving the way for more efficient neural network training on edge devices and cost-sensitive cloud deployments.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Nov 25, 2024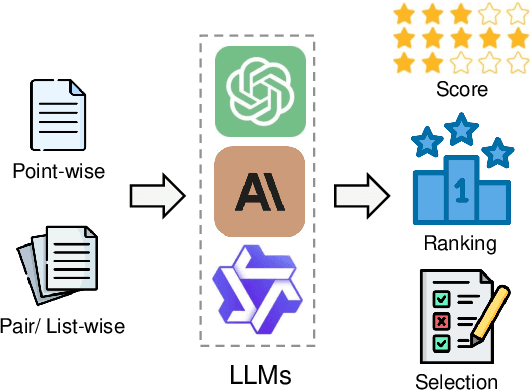
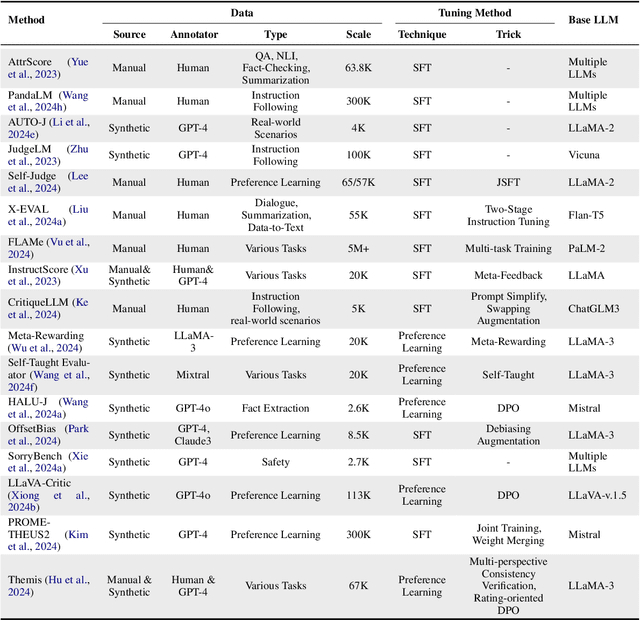
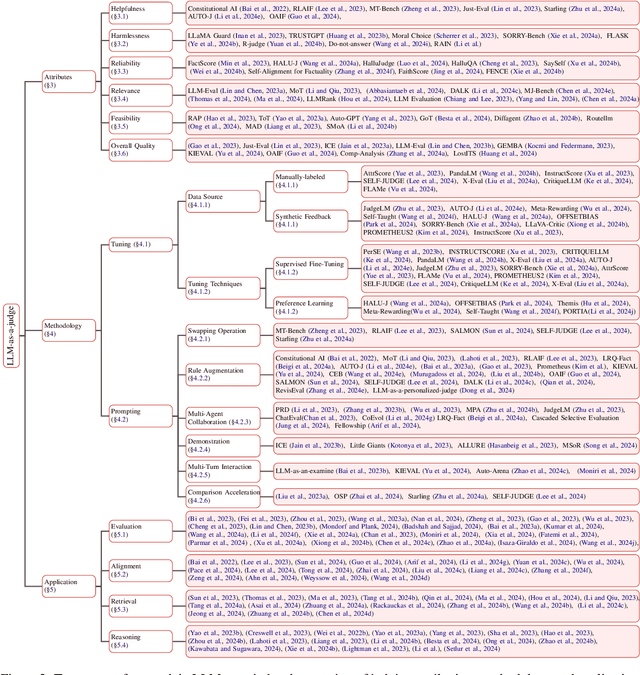
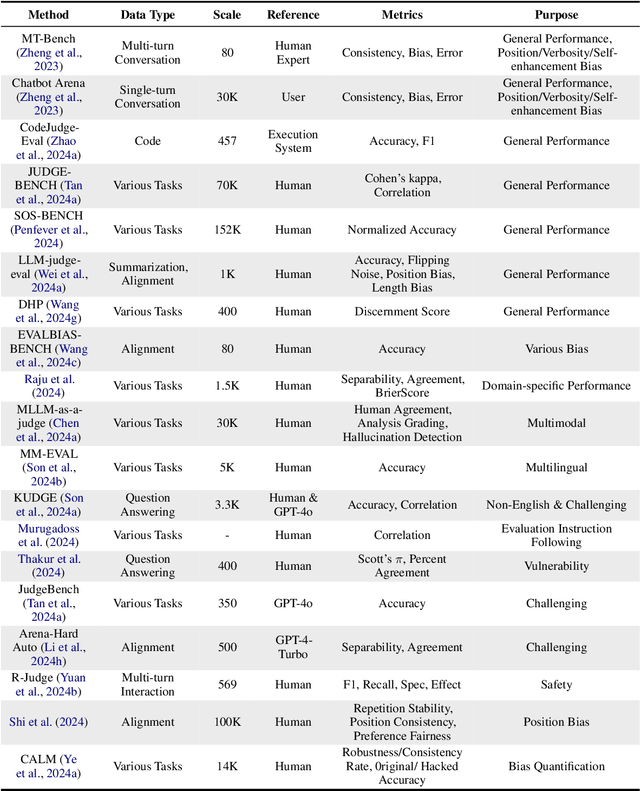
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.
LRQ-Fact: LLM-Generated Relevant Questions for Multimodal Fact-Checking
Oct 06, 2024Human fact-checkers have specialized domain knowledge that allows them to formulate precise questions to verify information accuracy. However, this expert-driven approach is labor-intensive and is not scalable, especially when dealing with complex multimodal misinformation. In this paper, we propose a fully-automated framework, LRQ-Fact, for multimodal fact-checking. Firstly, the framework leverages Vision-Language Models (VLMs) and Large Language Models (LLMs) to generate comprehensive questions and answers for probing multimodal content. Next, a rule-based decision-maker module evaluates both the original content and the generated questions and answers to assess the overall veracity. Extensive experiments on two benchmarks show that LRQ-Fact improves detection accuracy for multimodal misinformation. Moreover, we evaluate its generalizability across different model backbones, offering valuable insights for further refinement.
Model Attribution in Machine-Generated Disinformation: A Domain Generalization Approach with Supervised Contrastive Learning
Jul 31, 2024



Model attribution for machine-generated disinformation poses a significant challenge in understanding its origins and mitigating its spread. This task is especially challenging because modern large language models (LLMs) produce disinformation with human-like quality. Additionally, the diversity in prompting methods used to generate disinformation complicates accurate source attribution. These methods introduce domain-specific features that can mask the fundamental characteristics of the models. In this paper, we introduce the concept of model attribution as a domain generalization problem, where each prompting method represents a unique domain. We argue that an effective attribution model must be invariant to these domain-specific features. It should also be proficient in identifying the originating models across all scenarios, reflecting real-world detection challenges. To address this, we introduce a novel approach based on Supervised Contrastive Learning. This method is designed to enhance the model's robustness to variations in prompts and focuses on distinguishing between different source LLMs. We evaluate our model through rigorous experiments involving three common prompting methods: ``open-ended'', ``rewriting'', and ``paraphrasing'', and three advanced LLMs: ``llama 2'', ``chatgpt'', and ``vicuna''. Our results demonstrate the effectiveness of our approach in model attribution tasks, achieving state-of-the-art performance across diverse and unseen datasets.
Large Language Models for Data Annotation: A Survey
Feb 21, 2024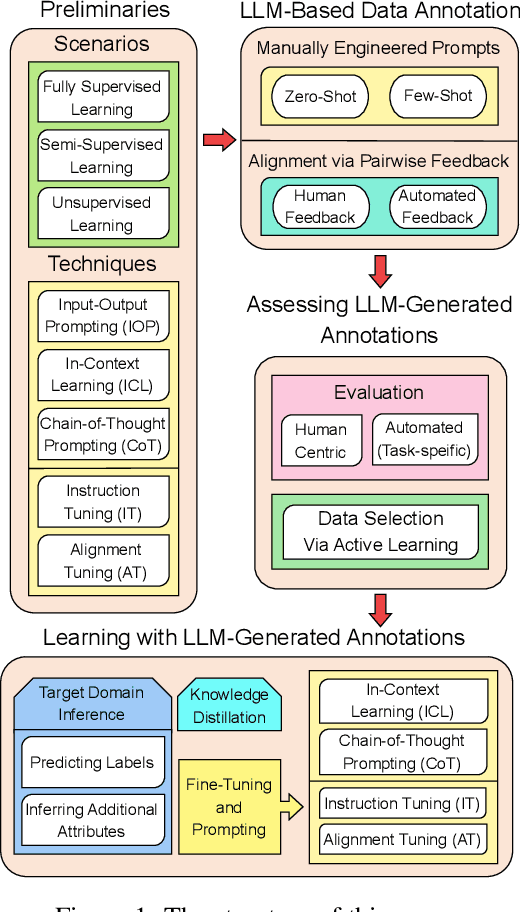
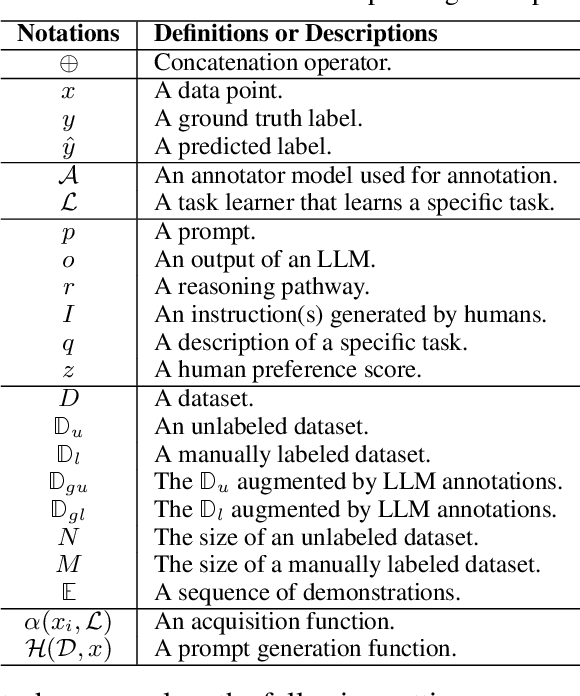
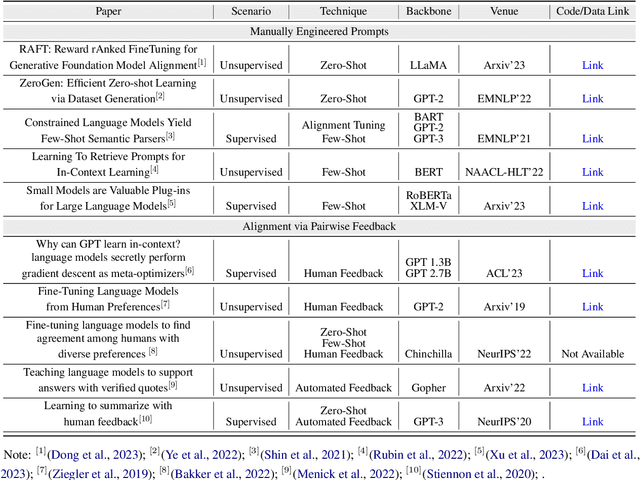
Data annotation is the labeling or tagging of raw data with relevant information, essential for improving the efficacy of machine learning models. The process, however, is labor-intensive and expensive. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to revolutionize and automate the intricate process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, this paper uniquely focuses on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Data Annotation, Assessing LLM-generated Annotations, and Learning with LLM-generated annotations. Furthermore, the paper includes an in-depth taxonomy of methodologies employing LLMs for data annotation, a comprehensive review of learning strategies for models incorporating LLM-generated annotations, and a detailed discussion on primary challenges and limitations associated with using LLMs for data annotation. As a key guide, this survey aims to direct researchers and practitioners in exploring the potential of the latest LLMs for data annotation, fostering future advancements in this critical domain. We provide a comprehensive papers list at \url{https://github.com/Zhen-Tan-dmml/LLM4Annotation.git}.