 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedditESS: A Mental Health Social Support Interaction Dataset -- Understanding Effective Social Support to Refine AI-Driven Support Tools
Mar 27, 2025Effective mental health support is crucial for alleviating psychological distress. While large language model (LLM)-based assistants have shown promise in mental health interventions, existing research often defines "effective" support primarily in terms of empathetic acknowledgments, overlooking other essential dimensions such as informational guidance, community validation, and tangible coping strategies. To address this limitation and better understand what constitutes effective support, we introduce RedditESS, a novel real-world dataset derived from Reddit posts, including supportive comments and original posters' follow-up responses. Grounded in established social science theories, we develop an ensemble labeling mechanism to annotate supportive comments as effective or not and perform qualitative assessments to ensure the reliability of the annotations. Additionally, we demonstrate the practical utility of RedditESS by using it to guide LLM alignment toward generating more context-sensitive and genuinely helpful supportive responses. By broadening the understanding of effective support, our study paves the way for advanced AI-driven mental health interventions.
Large Language Models for Data Annotation: A Survey
Feb 21, 2024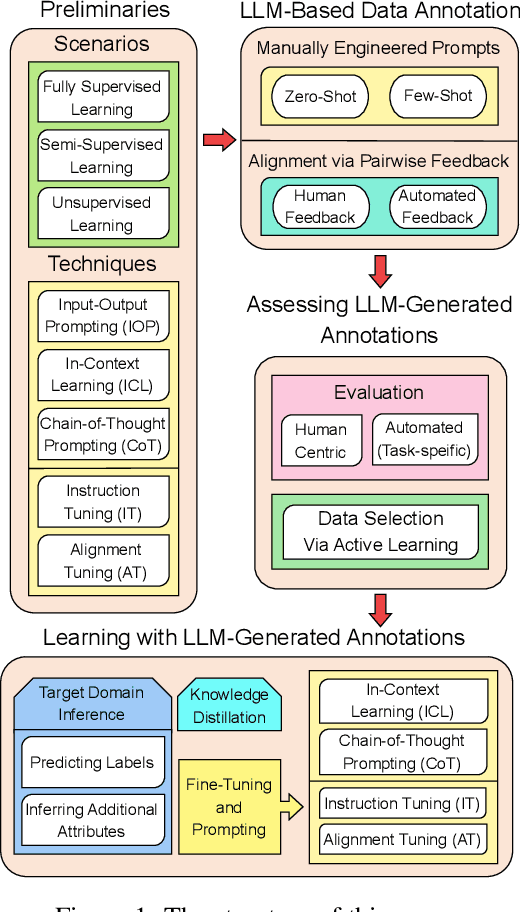
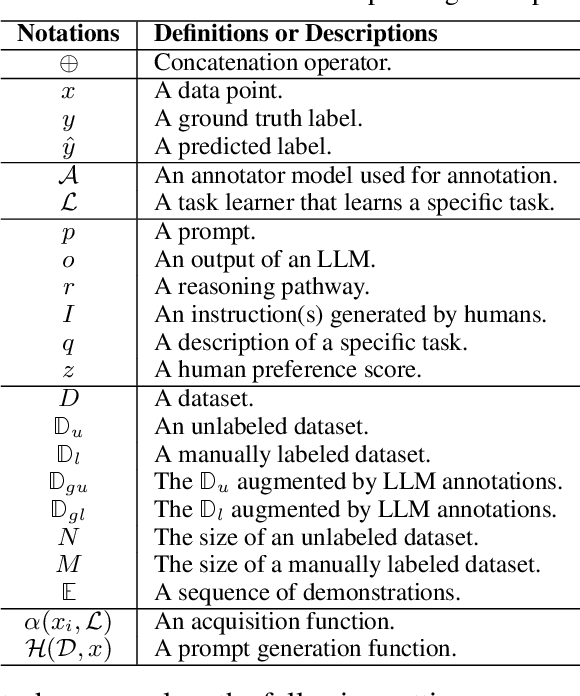
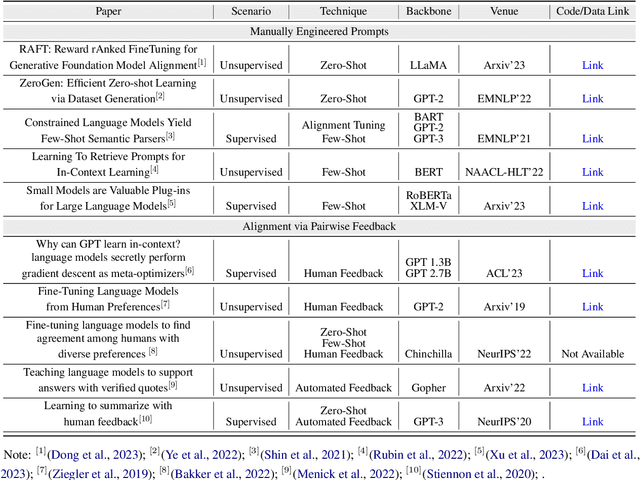
Data annotation is the labeling or tagging of raw data with relevant information, essential for improving the efficacy of machine learning models. The process, however, is labor-intensive and expensive. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to revolutionize and automate the intricate process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, this paper uniquely focuses on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Data Annotation, Assessing LLM-generated Annotations, and Learning with LLM-generated annotations. Furthermore, the paper includes an in-depth taxonomy of methodologies employing LLMs for data annotation, a comprehensive review of learning strategies for models incorporating LLM-generated annotations, and a detailed discussion on primary challenges and limitations associated with using LLMs for data annotation. As a key guide, this survey aims to direct researchers and practitioners in exploring the potential of the latest LLMs for data annotation, fostering future advancements in this critical domain. We provide a comprehensive papers list at \url{https://github.com/Zhen-Tan-dmml/LLM4Annotation.git}.
Estimating Topic Exposure for Under-Represented Users on Social Media
Aug 07, 2022
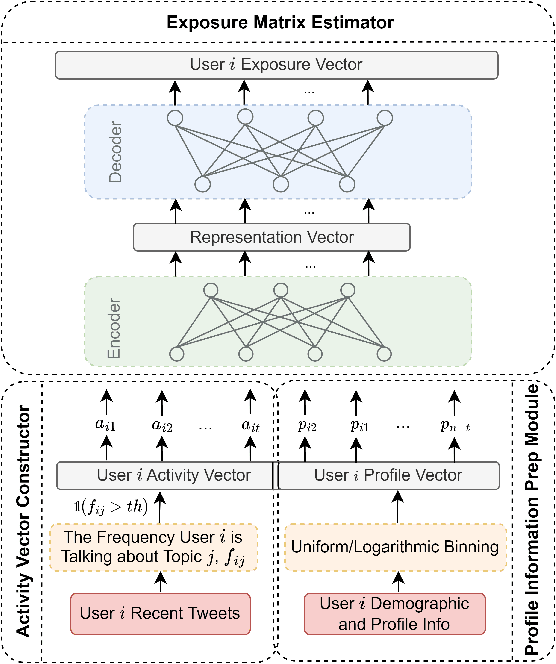
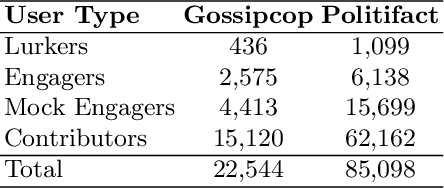

Online Social Networks (OSNs) facilitate access to a variety of data allowing researchers to analyze users' behavior and develop user behavioral analysis models. These models rely heavily on the observed data which is usually biased due to the participation inequality. This inequality consists of three groups of online users: the lurkers - users that solely consume the content, the engagers - users that contribute little to the content creation, and the contributors - users that are responsible for creating the majority of the online content. Failing to consider the contribution of all the groups while interpreting population-level interests or sentiments may yield biased results. To reduce the bias induced by the contributors, in this work, we focus on highlighting the engagers' contributions in the observed data as they are more likely to contribute when compared to lurkers, and they comprise a bigger population as compared to the contributors. The first step in behavioral analysis of these users is to find the topics they are exposed to but did not engage with. To do so, we propose a novel framework that aids in identifying these users and estimates their topic exposure. The exposure estimation mechanism is modeled by incorporating behavioral patterns from similar contributors as well as users' demographic and profile information.
Text Transformations in Contrastive Self-Supervised Learning: A Review
Mar 22, 2022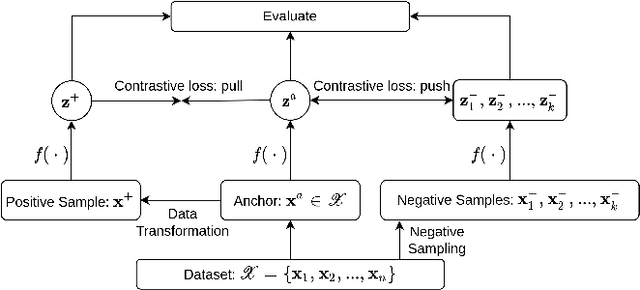
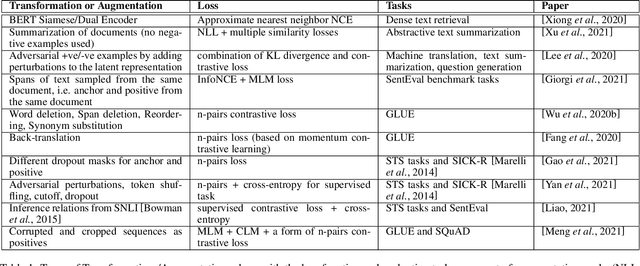


Contrastive self-supervised learning has become a prominent technique in representation learning. The main step in these methods is to contrast semantically similar and dissimilar pairs of samples. However, in the domain of Natural Language, the augmentation methods used in creating similar pairs with regard to contrastive learning assumptions are challenging. This is because, even simply modifying a word in the input might change the semantic meaning of the sentence, and hence, would violate the distributional hypothesis. In this review paper, we formalize the contrastive learning framework in the domain of natural language processing. We emphasize the considerations that need to be addressed in the data transformation step and review the state-of-the-art methods and evaluations for contrastive representation learning in NLP. Finally, we describe some challenges and potential directions for learning better text representations using contrastive methods.
Domain Adaptive Fake News Detection via Reinforcement Learning
Feb 16, 2022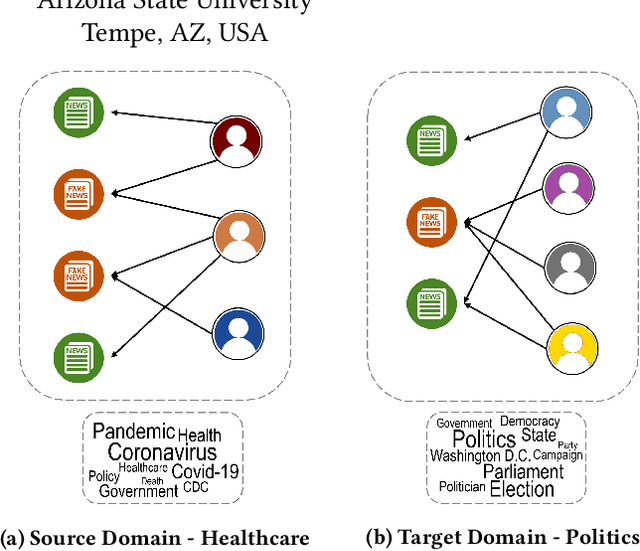
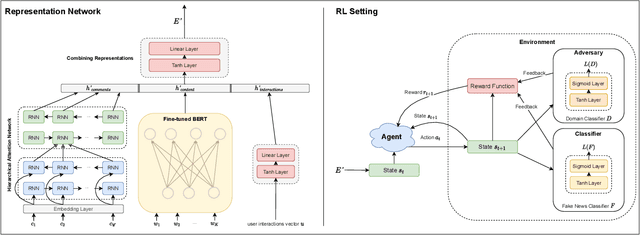
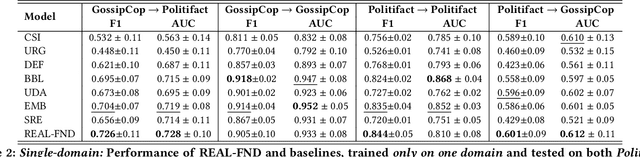
With social media being a major force in information consumption, accelerated propagation of fake news has presented new challenges for platforms to distinguish between legitimate and fake news. Effective fake news detection is a non-trivial task due to the diverse nature of news domains and expensive annotation costs. In this work, we address the limitations of existing automated fake news detection models by incorporating auxiliary information (e.g., user comments and user-news interactions) into a novel reinforcement learning-based model called \textbf{RE}inforced \textbf{A}daptive \textbf{L}earning \textbf{F}ake \textbf{N}ews \textbf{D}etection (REAL-FND). REAL-FND exploits cross-domain and within-domain knowledge that makes it robust in a target domain, despite being trained in a different source domain. Extensive experiments on real-world datasets illustrate the effectiveness of the proposed model, especially when limited labeled data is available in the target domain.
A Survey on Echo Chambers on Social Media: Description, Detection and Mitigation
Dec 09, 2021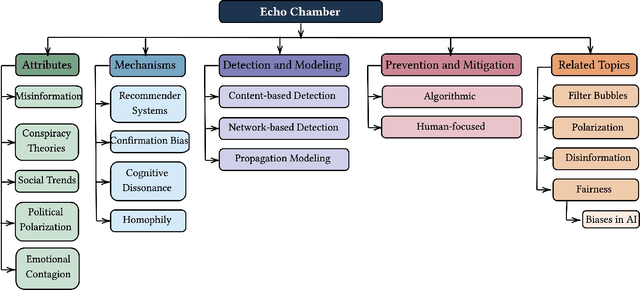
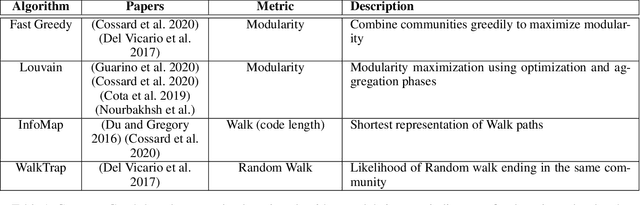
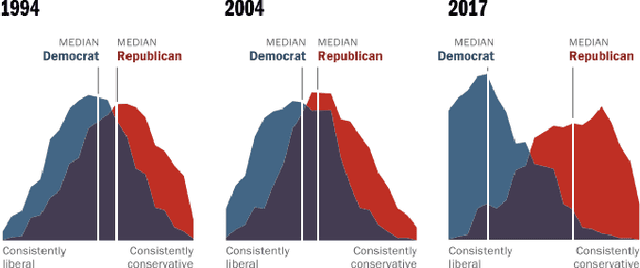

Echo chambers on social media are a significant problem that can elicit a number of negative consequences, most recently affecting the response to COVID-19. Echo chambers promote conspiracy theories about the virus and are found to be linked to vaccine hesitancy, less compliance with mask mandates, and the practice of social distancing. Moreover, the problem of echo chambers is connected to other pertinent issues like political polarization and the spread of misinformation. An echo chamber is defined as a network of users in which users only interact with opinions that support their pre-existing beliefs and opinions, and they exclude and discredit other viewpoints. This survey aims to examine the echo chamber phenomenon on social media from a social computing perspective and provide a blueprint for possible solutions. We survey the related literature to understand the attributes of echo chambers and how they affect the individual and society at large. Additionally, we show the mechanisms, both algorithmic and psychological, that lead to the formation of echo chambers. These mechanisms could be manifested in two forms: (1) the bias of social media's recommender systems and (2) internal biases such as confirmation bias and homophily. While it is immensely challenging to mitigate internal biases, there has been great efforts seeking to mitigate the bias of recommender systems. These recommender systems take advantage of our own biases to personalize content recommendations to keep us engaged in order to watch more ads. Therefore, we further investigate different computational approaches for echo chamber detection and prevention, mainly based around recommender systems.
Causal Inference for Time series Analysis: Problems, Methods and Evaluation
Feb 11, 2021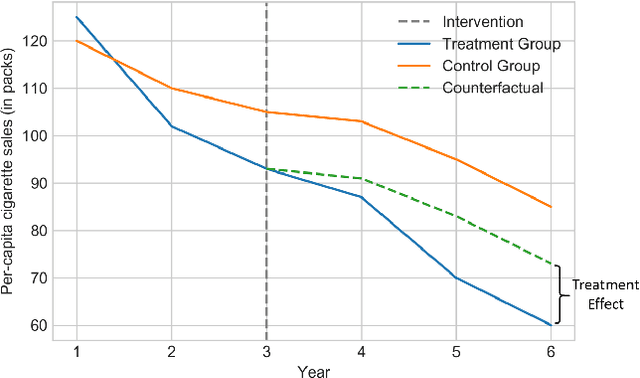

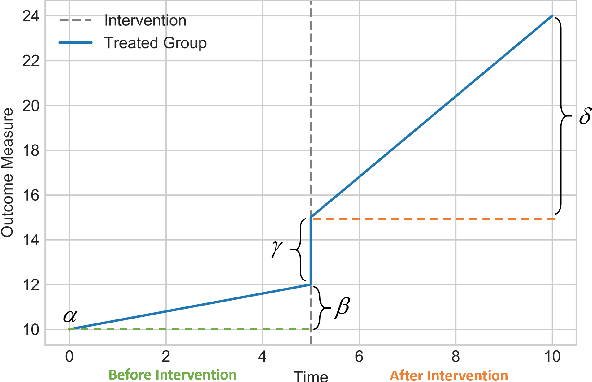
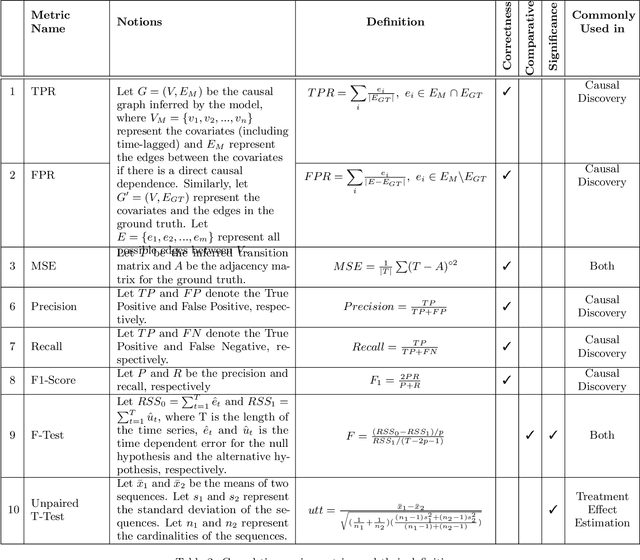
Time series data is a collection of chronological observations which is generated by several domains such as medical and financial fields. Over the years, different tasks such as classification, forecasting, and clustering have been proposed to analyze this type of data. Time series data has been also used to study the effect of interventions over time. Moreover, in many fields of science, learning the causal structure of dynamic systems and time series data is considered an interesting task which plays an important role in scientific discoveries. Estimating the effect of an intervention and identifying the causal relations from the data can be performed via causal inference. Existing surveys on time series discuss traditional tasks such as classification and forecasting or explain the details of the approaches proposed to solve a specific task. In this paper, we focus on two causal inference tasks, i.e., treatment effect estimation and causal discovery for time series data, and provide a comprehensive review of the approaches in each task. Furthermore, we curate a list of commonly used evaluation metrics and datasets for each task and provide in-depth insight. These metrics and datasets can serve as benchmarks for research in the field.
"Let's Eat Grandma": When Punctuation Matters in Sentence Representation for Sentiment Analysis
Dec 10, 2020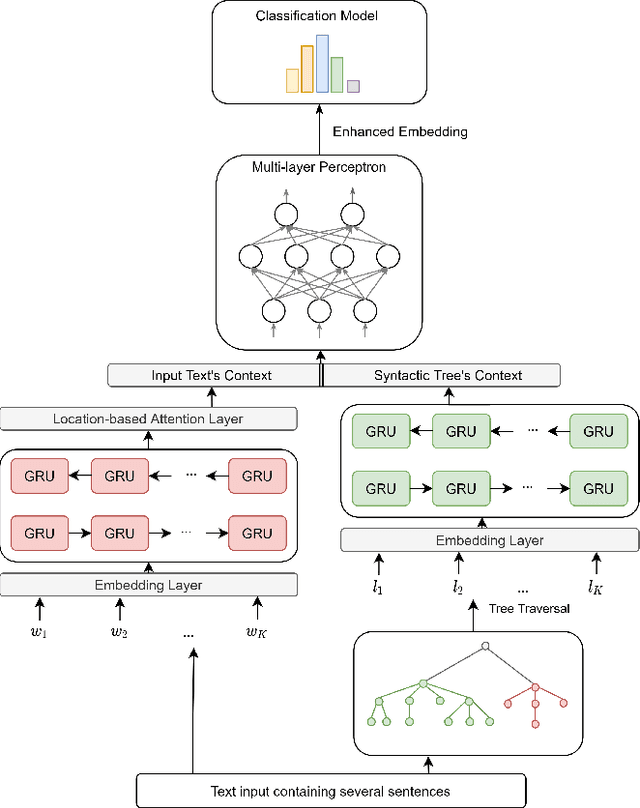

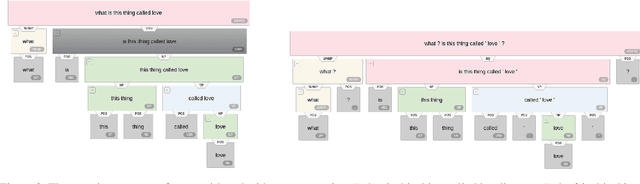
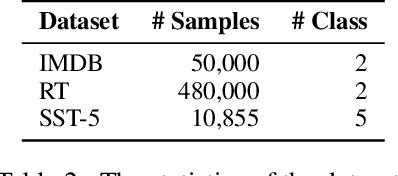
Neural network-based embeddings have been the mainstream approach for creating a vector representation of the text to capture lexical and semantic similarities and dissimilarities. In general, existing encoding methods dismiss the punctuation as insignificant information; consequently, they are routinely eliminated in the pre-processing phase as they are shown to improve task performance. In this paper, we hypothesize that punctuation could play a significant role in sentiment analysis and propose a novel representation model to improve syntactic and contextual performance. We corroborate our findings by conducting experiments on publicly available datasets and verify that our model can identify the sentiments more accurately over other state-of-the-art baseline methods.
Causal Adversarial Network for Learning Conditional and Interventional Distributions
Sep 21, 2020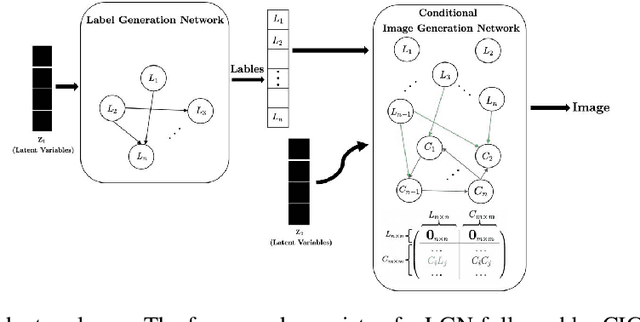
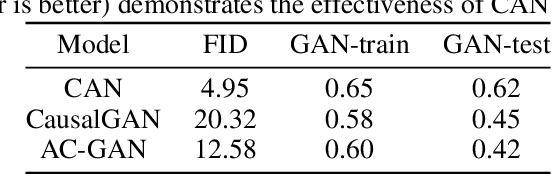


We propose a generative Causal Adversarial Network (CAN) for learning and sampling from conditional and interventional distributions. In contrast to the existing CausalGAN which requires the causal graph to be given, our proposed framework learns the causal relations from the data and generates samples accordingly. The proposed CAN comprises a two-fold process namely Label Generation Network (LGN) and Conditional Image Generation Network (CIGN). The LGN is a GAN-based architecture which learns and samples from the causal model over labels. The sampled labels are then fed to CIGN, a conditional GAN architecture, which learns the relationships amongst labels and pixels and pixels themselves and generates samples based on them. This framework is equipped with an intervention mechanism which enables. the model to generate samples from interventional distributions. We quantitatively and qualitatively assess the performance of CAN and empirically show that our model is able to generate both interventional and conditional samples without having access to the causal graph for the application of face generation on CelebA data.
Causal Interpretability for Machine Learning -- Problems, Methods and Evaluation
Mar 19, 2020
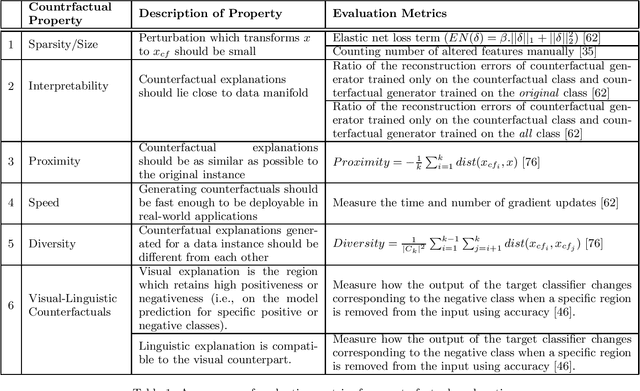
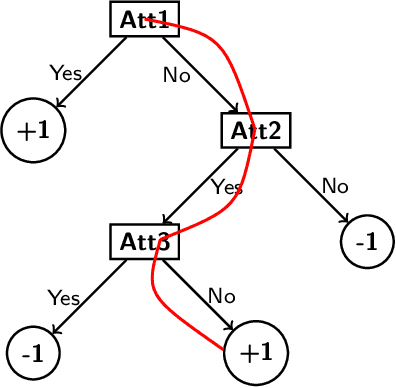

Machine learning models have had discernible achievements in a myriad of applications. However, most of these models are black-boxes, and it is obscure how the decisions are made by them. This makes the models unreliable and untrustworthy. To provide insights into the decision making processes of these models, a variety of traditional interpretable models have been proposed. Moreover, to generate more human-friendly explanations, recent work on interpretability tries to answer questions related to causality such as "Why does this model makes such decisions?" or "Was it a specific feature that caused the decision made by the model?". In this work, models that aim to answer causal questions are referred to as causal interpretable models. The existing surveys have covered concepts and methodologies of traditional interpretability. In this work, we present a comprehensive survey on causal interpretable models from the aspects of the problems and methods. In addition, this survey provides in-depth insights into the existing evaluation metrics for measuring interpretability, which can help practitioners understand for what scenarios each evaluation metric is suitable.