 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs Capabilities Towards Understanding Social Dynamics
Nov 20, 2024

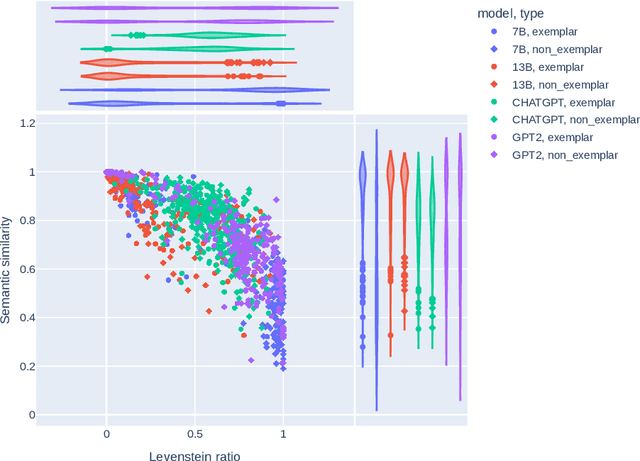

Social media discourse involves people from different backgrounds, beliefs, and motives. Thus, often such discourse can devolve into toxic interactions. Generative Models, such as Llama and ChatGPT, have recently exploded in popularity due to their capabilities in zero-shot question-answering. Because these models are increasingly being used to ask questions of social significance, a crucial research question is whether they can understand social media dynamics. This work provides a critical analysis regarding generative LLM's ability to understand language and dynamics in social contexts, particularly considering cyberbullying and anti-cyberbullying (posts aimed at reducing cyberbullying) interactions. Specifically, we compare and contrast the capabilities of different large language models (LLMs) to understand three key aspects of social dynamics: language, directionality, and the occurrence of bullying/anti-bullying messages. We found that while fine-tuned LLMs exhibit promising results in some social media understanding tasks (understanding directionality), they presented mixed results in others (proper paraphrasing and bullying/anti-bullying detection). We also found that fine-tuning and prompt engineering mechanisms can have positive effects in some tasks. We believe that a understanding of LLM's capabilities is crucial to design future models that can be effectively used in social applications.
JORA: JAX Tensor-Parallel LoRA Library for Retrieval Augmented Fine-Tuning
Mar 19, 2024The scaling of Large Language Models (LLMs) for retrieval-based tasks, particularly in Retrieval Augmented Generation (RAG), faces significant memory constraints, especially when fine-tuning extensive prompt sequences. Current open-source libraries support full-model inference and fine-tuning across multiple GPUs but fall short of accommodating the efficient parameter distribution required for retrieved context. Addressing this gap, we introduce a novel framework for PEFT-compatible fine-tuning of Llama-2 models, leveraging distributed training. Our framework uniquely utilizes JAX's just-in-time (JIT) compilation and tensor-sharding for efficient resource management, thereby enabling accelerated fine-tuning with reduced memory requirements. This advancement significantly improves the scalability and feasibility of fine-tuning LLMs for complex RAG applications, even on systems with limited GPU resources. Our experiments show more than 12x improvement in runtime compared to Hugging Face/DeepSpeed implementation with four GPUs while consuming less than half the VRAM per GPU.
Fairness through Aleatoric Uncertainty
Apr 07, 2023We propose a unique solution to tackle the often-competing goals of fairness and utility in machine learning classification tasks. While fairness ensures that the model's predictions are unbiased and do not discriminate against any particular group, utility focuses on maximizing the accuracy of the model's predictions. Our aim is to investigate the relationship between uncertainty and fairness. Our approach leverages this concept by employing Bayesian learning to estimate the uncertainty in sample predictions where the estimation is independent of confounding effects related to the protected attribute. Through empirical evidence, we show that samples with low classification uncertainty are modeled more accurately and fairly than those with high uncertainty, which may have biased representations and higher prediction errors. To address the challenge of balancing fairness and utility, we propose a novel fairness-utility objective that is defined based on uncertainty quantification. The weights in this objective are determined by the level of uncertainty, allowing us to optimize both fairness and utility simultaneously. Experiments on real-world datasets demonstrate the effectiveness of our approach. Our results show that our method outperforms state-of-the-art methods in terms of the fairness-utility tradeoff and this applies to both group and individual fairness metrics. This work presents a fresh perspective on the trade-off between accuracy and fairness in machine learning and highlights the potential of using uncertainty as a means to achieve optimal fairness and utility.
Distributional Shift Adaptation using Domain-Specific Features
Nov 09, 2022Machine learning algorithms typically assume that the training and test samples come from the same distributions, i.e., in-distribution. However, in open-world scenarios, streaming big data can be Out-Of-Distribution (OOD), rendering these algorithms ineffective. Prior solutions to the OOD challenge seek to identify invariant features across different training domains. The underlying assumption is that these invariant features should also work reasonably well in the unlabeled target domain. By contrast, this work is interested in the domain-specific features that include both invariant features and features unique to the target domain. We propose a simple yet effective approach that relies on correlations in general regardless of whether the features are invariant or not. Our approach uses the most confidently predicted samples identified by an OOD base model (teacher model) to train a new model (student model) that effectively adapts to the target domain. Empirical evaluations on benchmark datasets show that the performance is improved over the SOTA by ~10-20%
A Survey on Echo Chambers on Social Media: Description, Detection and Mitigation
Dec 09, 2021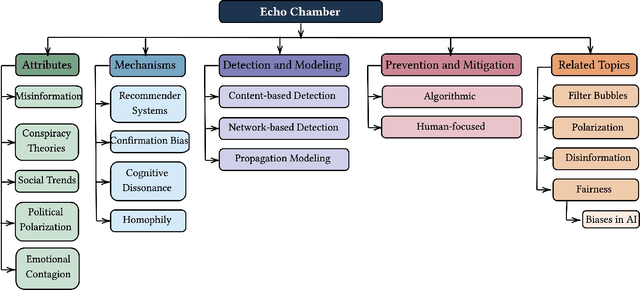
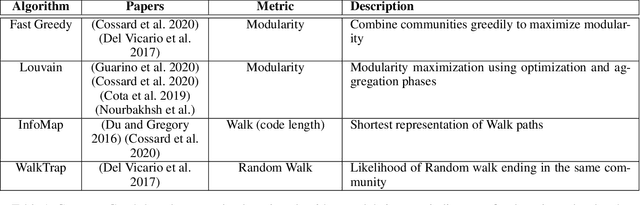
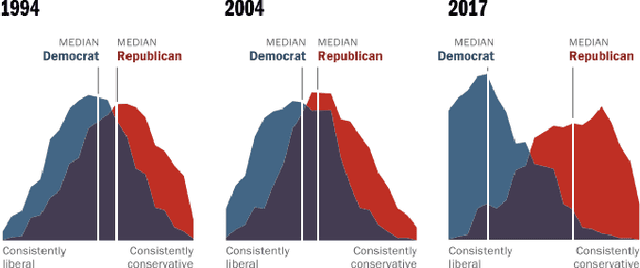

Echo chambers on social media are a significant problem that can elicit a number of negative consequences, most recently affecting the response to COVID-19. Echo chambers promote conspiracy theories about the virus and are found to be linked to vaccine hesitancy, less compliance with mask mandates, and the practice of social distancing. Moreover, the problem of echo chambers is connected to other pertinent issues like political polarization and the spread of misinformation. An echo chamber is defined as a network of users in which users only interact with opinions that support their pre-existing beliefs and opinions, and they exclude and discredit other viewpoints. This survey aims to examine the echo chamber phenomenon on social media from a social computing perspective and provide a blueprint for possible solutions. We survey the related literature to understand the attributes of echo chambers and how they affect the individual and society at large. Additionally, we show the mechanisms, both algorithmic and psychological, that lead to the formation of echo chambers. These mechanisms could be manifested in two forms: (1) the bias of social media's recommender systems and (2) internal biases such as confirmation bias and homophily. While it is immensely challenging to mitigate internal biases, there has been great efforts seeking to mitigate the bias of recommender systems. These recommender systems take advantage of our own biases to personalize content recommendations to keep us engaged in order to watch more ads. Therefore, we further investigate different computational approaches for echo chamber detection and prevention, mainly based around recommender systems.
Causal Inference for Time series Analysis: Problems, Methods and Evaluation
Feb 11, 2021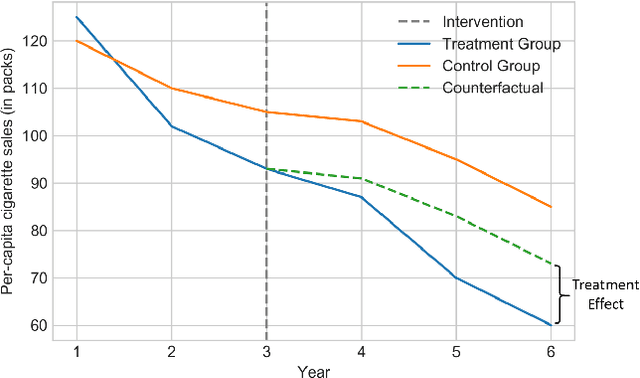

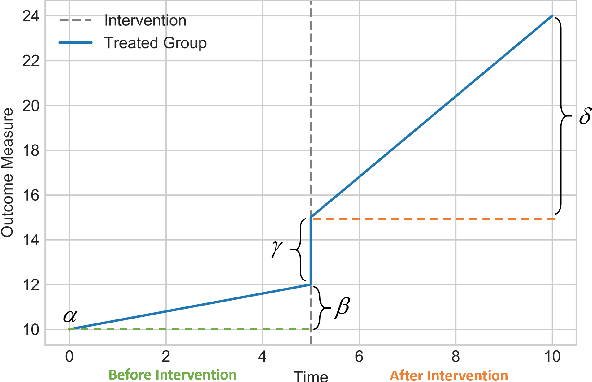
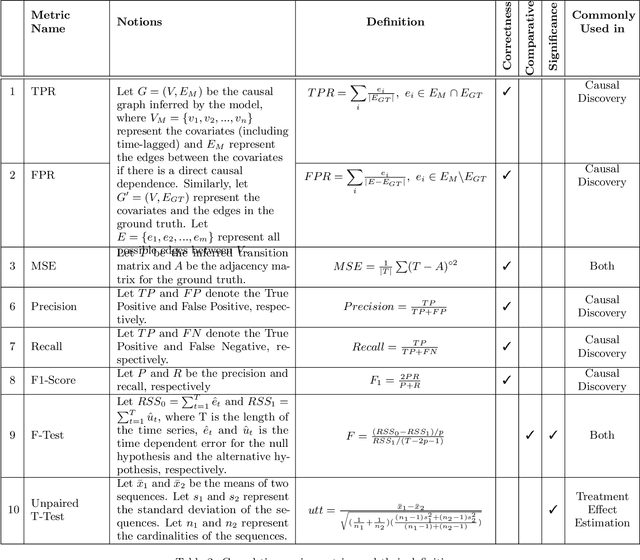
Time series data is a collection of chronological observations which is generated by several domains such as medical and financial fields. Over the years, different tasks such as classification, forecasting, and clustering have been proposed to analyze this type of data. Time series data has been also used to study the effect of interventions over time. Moreover, in many fields of science, learning the causal structure of dynamic systems and time series data is considered an interesting task which plays an important role in scientific discoveries. Estimating the effect of an intervention and identifying the causal relations from the data can be performed via causal inference. Existing surveys on time series discuss traditional tasks such as classification and forecasting or explain the details of the approaches proposed to solve a specific task. In this paper, we focus on two causal inference tasks, i.e., treatment effect estimation and causal discovery for time series data, and provide a comprehensive review of the approaches in each task. Furthermore, we curate a list of commonly used evaluation metrics and datasets for each task and provide in-depth insight. These metrics and datasets can serve as benchmarks for research in the field.