 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMO: Causality-Guided Adversarial Multimodal Domain Generalization for Crisis Classification
Dec 08, 2025Crisis classification in social media aims to extract actionable disaster-related information from multimodal posts, which is a crucial task for enhancing situational awareness and facilitating timely emergency responses. However, the wide variation in crisis types makes achieving generalizable performance across unseen disasters a persistent challenge. Existing approaches primarily leverage deep learning to fuse textual and visual cues for crisis classification, achieving numerically plausible results under in-domain settings. However, they exhibit poor generalization across unseen crisis types because they 1. do not disentangle spurious and causal features, resulting in performance degradation under domain shift, and 2. fail to align heterogeneous modality representations within a shared space, which hinders the direct adaptation of established single-modality domain generalization (DG) techniques to the multimodal setting. To address these issues, we introduce a causality-guided multimodal domain generalization (MMDG) framework that combines adversarial disentanglement with unified representation learning for crisis classification. The adversarial objective encourages the model to disentangle and focus on domain-invariant causal features, leading to more generalizable classifications grounded in stable causal mechanisms. The unified representation aligns features from different modalities within a shared latent space, enabling single-modality DG strategies to be seamlessly extended to multimodal learning. Experiments on the different datasets demonstrate that our approach achieves the best performance in unseen disaster scenarios.
Are Today's LLMs Ready to Explain Well-Being Concepts?
Aug 06, 2025Well-being encompasses mental, physical, and social dimensions essential to personal growth and informed life decisions. As individuals increasingly consult Large Language Models (LLMs) to understand well-being, a key challenge emerges: Can LLMs generate explanations that are not only accurate but also tailored to diverse audiences? High-quality explanations require both factual correctness and the ability to meet the expectations of users with varying expertise. In this work, we construct a large-scale dataset comprising 43,880 explanations of 2,194 well-being concepts, generated by ten diverse LLMs. We introduce a principle-guided LLM-as-a-judge evaluation framework, employing dual judges to assess explanation quality. Furthermore, we show that fine-tuning an open-source LLM using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) can significantly enhance the quality of generated explanations. Our results reveal: (1) The proposed LLM judges align well with human evaluations; (2) explanation quality varies significantly across models, audiences, and categories; and (3) DPO- and SFT-finetuned models outperform their larger counterparts, demonstrating the effectiveness of preference-based learning for specialized explanation tasks.
Preference Leakage: A Contamination Problem in LLM-as-a-judge
Feb 03, 2025



Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development. While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm. In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators. To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family. Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks. Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge. We release all codes and data at: https://github.com/David-Li0406/Preference-Leakage.
In-Group Love, Out-Group Hate: A Framework to Measure Affective Polarization via Contentious Online Discussions
Dec 18, 2024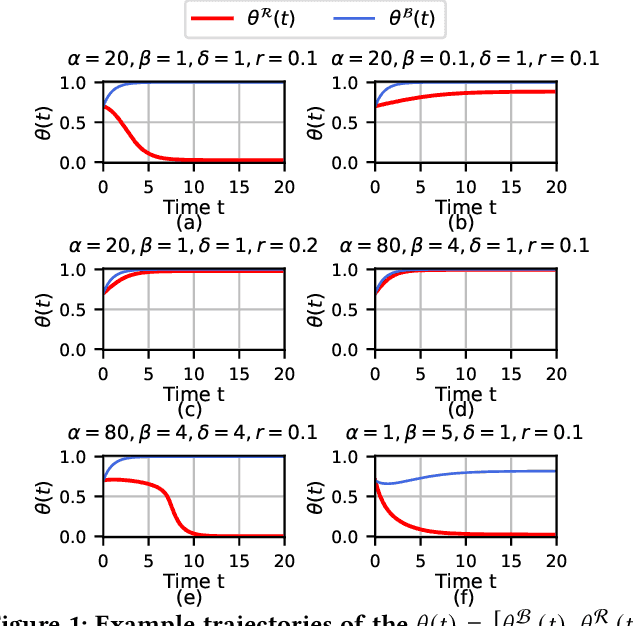
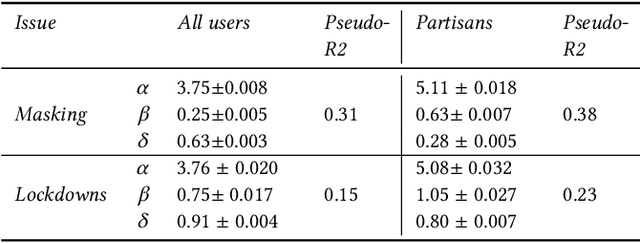
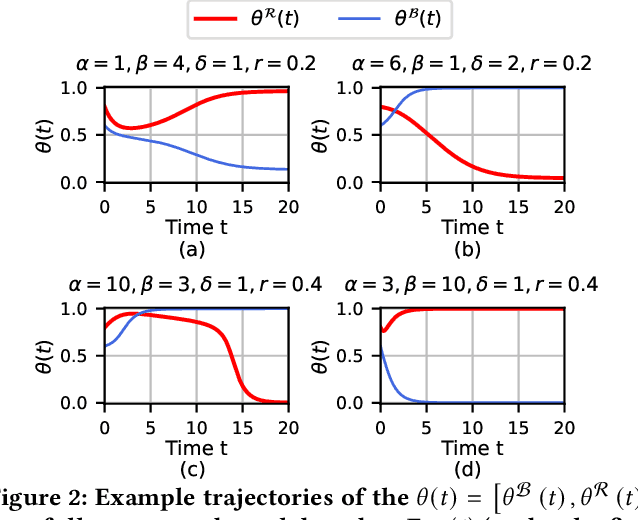
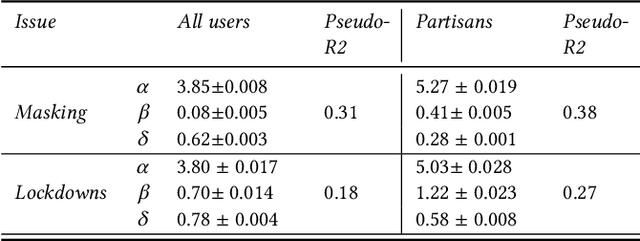
Affective polarization, the emotional divide between ideological groups marked by in-group love and out-group hate, has intensified in the United States, driving contentious issues like masking and lockdowns during the COVID-19 pandemic. Despite its societal impact, existing models of opinion change fail to account for emotional dynamics nor offer methods to quantify affective polarization robustly and in real-time. In this paper, we introduce a discrete choice model that captures decision-making within affectively polarized social networks and propose a statistical inference method estimate key parameters -- in-group love and out-group hate -- from social media data. Through empirical validation from online discussions about the COVID-19 pandemic, we demonstrate that our approach accurately captures real-world polarization dynamics and explains the rapid emergence of a partisan gap in attitudes towards masking and lockdowns. This framework allows for tracking affective polarization across contentious issues has broad implications for fostering constructive online dialogues in digital spaces.
Assessing the Impact of Conspiracy Theories Using Large Language Models
Dec 09, 2024Measuring the relative impact of CTs is important for prioritizing responses and allocating resources effectively, especially during crises. However, assessing the actual impact of CTs on the public poses unique challenges. It requires not only the collection of CT-specific knowledge but also diverse information from social, psychological, and cultural dimensions. Recent advancements in large language models (LLMs) suggest their potential utility in this context, not only due to their extensive knowledge from large training corpora but also because they can be harnessed for complex reasoning. In this work, we develop datasets of popular CTs with human-annotated impacts. Borrowing insights from human impact assessment processes, we then design tailored strategies to leverage LLMs for performing human-like CT impact assessments. Through rigorous experiments, we textit{discover that an impact assessment mode using multi-step reasoning to analyze more CT-related evidence critically produces accurate results; and most LLMs demonstrate strong bias, such as assigning higher impacts to CTs presented earlier in the prompt, while generating less accurate impact assessments for emotionally charged and verbose CTs.
Training Noise Token Pruning
Nov 27, 2024



In the present work we present Training Noise Token (TNT) Pruning for vision transformers. Our method relaxes the discrete token dropping condition to continuous additive noise, providing smooth optimization in training, while retaining discrete dropping computational gains in deployment settings. We provide theoretical connections to Rate-Distortion literature, and empirical evaluations on the ImageNet dataset using ViT and DeiT architectures demonstrating TNT's advantages over previous pruning methods.
From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Nov 25, 2024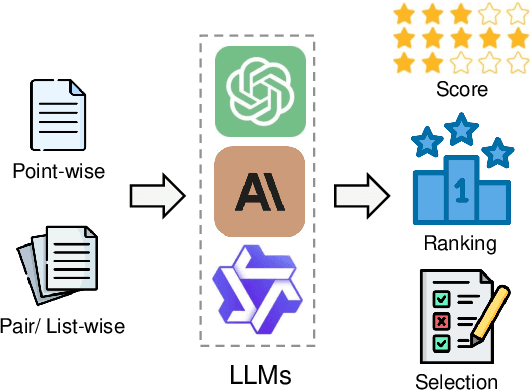
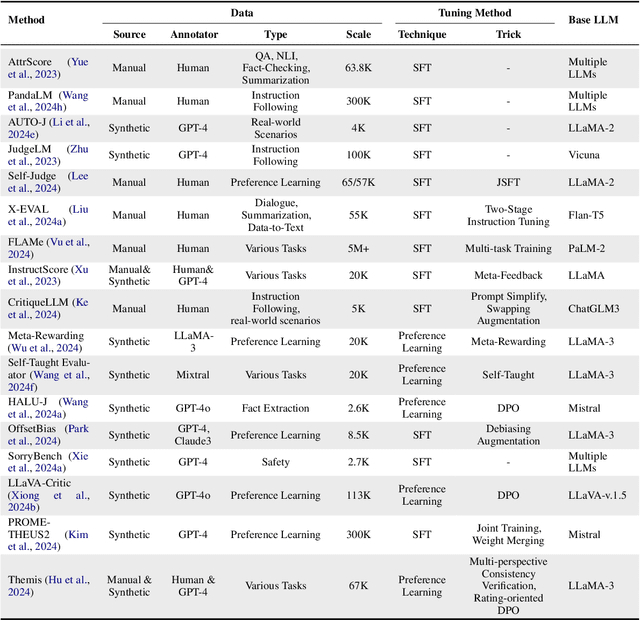
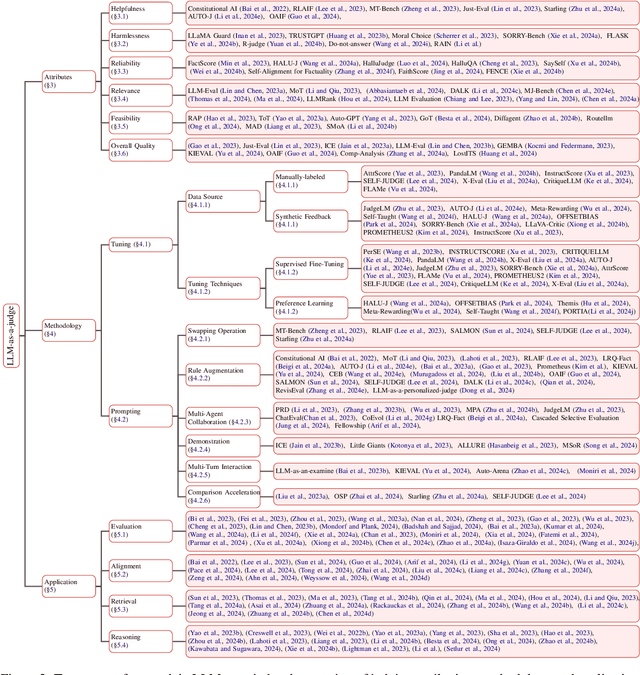
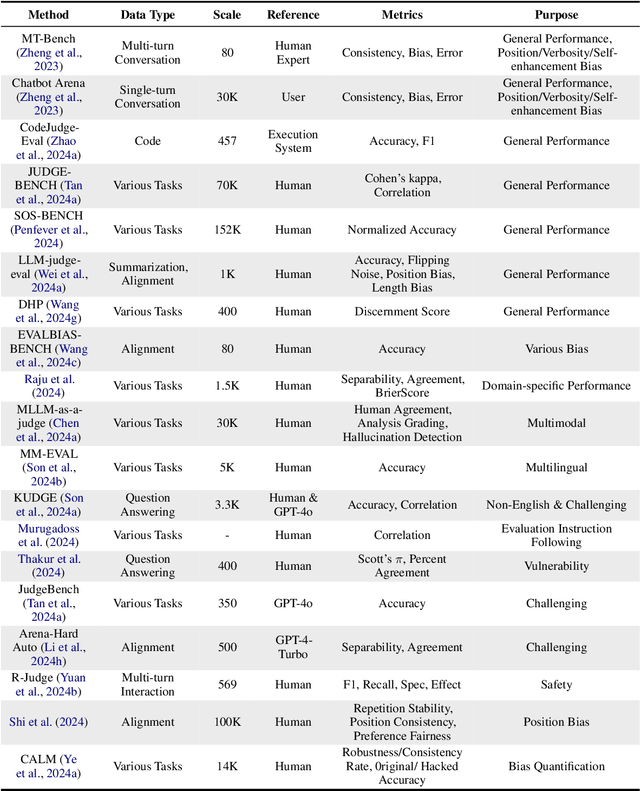
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.
LRQ-Fact: LLM-Generated Relevant Questions for Multimodal Fact-Checking
Oct 06, 2024



Human fact-checkers have specialized domain knowledge that allows them to formulate precise questions to verify information accuracy. However, this expert-driven approach is labor-intensive and is not scalable, especially when dealing with complex multimodal misinformation. In this paper, we propose a fully-automated framework, LRQ-Fact, for multimodal fact-checking. Firstly, the framework leverages Vision-Language Models (VLMs) and Large Language Models (LLMs) to generate comprehensive questions and answers for probing multimodal content. Next, a rule-based decision-maker module evaluates both the original content and the generated questions and answers to assess the overall veracity. Extensive experiments on two benchmarks show that LRQ-Fact improves detection accuracy for multimodal misinformation. Moreover, we evaluate its generalizability across different model backbones, offering valuable insights for further refinement.
BlueTempNet: A Temporal Multi-network Dataset of Social Interactions in Bluesky Social
Jul 24, 2024Decentralized social media platforms like Bluesky Social (Bluesky) have made it possible to publicly disclose some user behaviors with millisecond-level precision. Embracing Bluesky's principles of open-source and open-data, we present the first collection of the temporal dynamics of user-driven social interactions. BlueTempNet integrates multiple types of networks into a single multi-network, including user-to-user interactions (following and blocking users) and user-to-community interactions (creating and joining communities). Communities are user-formed groups in custom Feeds, where users subscribe to posts aligned with their interests. Following Bluesky's public data policy, we collect existing Bluesky Feeds, including the users who liked and generated these Feeds, and provide tools to gather users' social interactions within a date range. This data-collection strategy captures past user behaviors and supports the future data collection of user behavior.
Catching Chameleons: Detecting Evolving Disinformation Generated using Large Language Models
Jun 26, 2024



Despite recent advancements in detecting disinformation generated by large language models (LLMs), current efforts overlook the ever-evolving nature of this disinformation. In this work, we investigate a challenging yet practical research problem of detecting evolving LLM-generated disinformation. Disinformation evolves constantly through the rapid development of LLMs and their variants. As a consequence, the detection model faces significant challenges. First, it is inefficient to train separate models for each disinformation generator. Second, the performance decreases in scenarios when evolving LLM-generated disinformation is encountered in sequential order. To address this problem, we propose DELD (Detecting Evolving LLM-generated Disinformation), a parameter-efficient approach that jointly leverages the general fact-checking capabilities of pre-trained language models (PLM) and the independent disinformation generation characteristics of various LLMs. In particular, the learned characteristics are concatenated sequentially to facilitate knowledge accumulation and transformation. DELD addresses the issue of label scarcity by integrating the semantic embeddings of disinformation with trainable soft prompts to elicit model-specific knowledge. Our experiments show that \textit{DELD} significantly outperforms state-of-the-art methods. Moreover, our method provides critical insights into the unique patterns of disinformation generation across different LLMs, offering valuable perspectives in this line of research.