 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge
Paper and Code
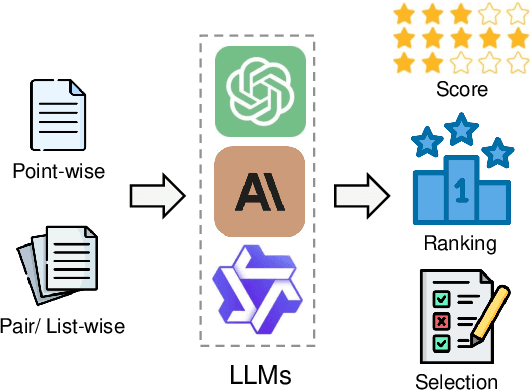
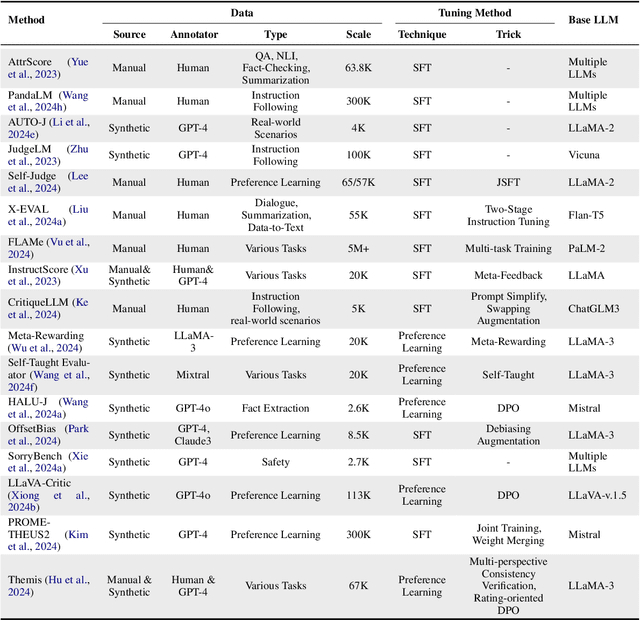
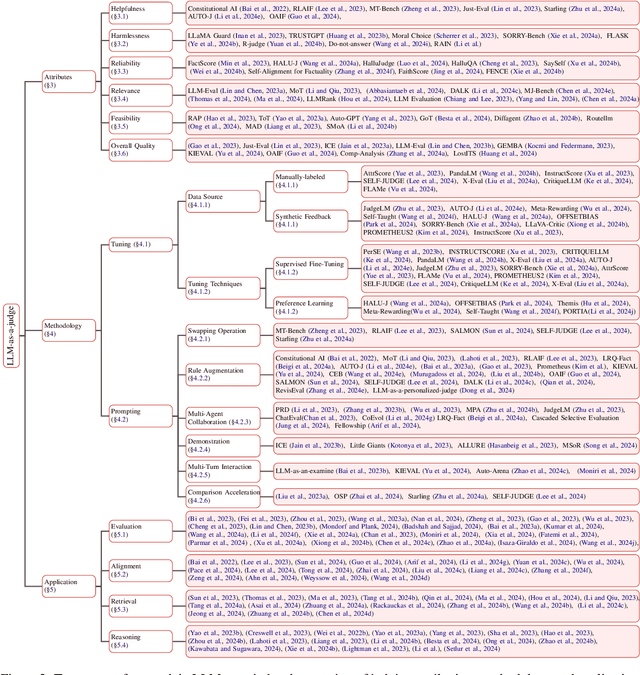
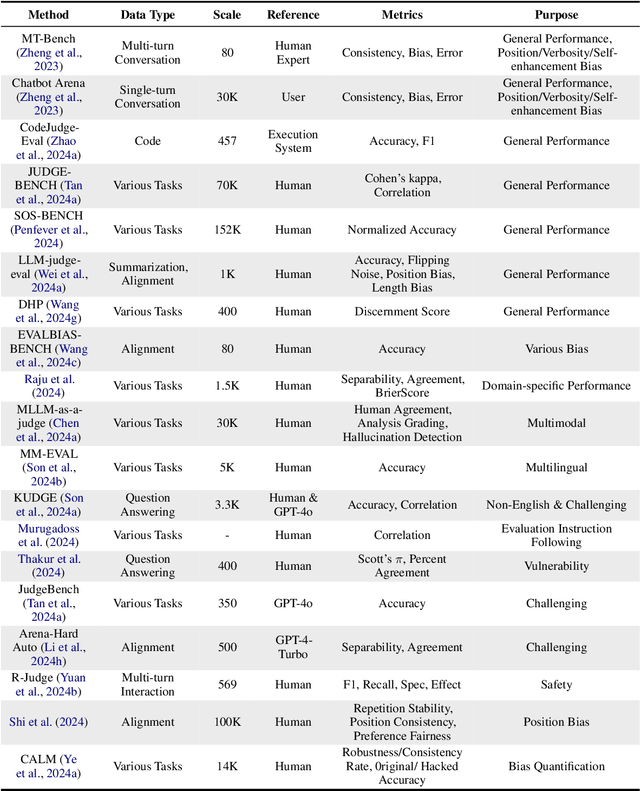
Assessment and evaluation have long been critical challenges in artificial intelligence (AI) and natural language processing (NLP). However, traditional methods, whether matching-based or embedding-based, often fall short of judging subtle attributes and delivering satisfactory results. Recent advancements in Large Language Models (LLMs) inspire the "LLM-as-a-judge" paradigm, where LLMs are leveraged to perform scoring, ranking, or selection across various tasks and applications. This paper provides a comprehensive survey of LLM-based judgment and assessment, offering an in-depth overview to advance this emerging field. We begin by giving detailed definitions from both input and output perspectives. Then we introduce a comprehensive taxonomy to explore LLM-as-a-judge from three dimensions: what to judge, how to judge and where to judge. Finally, we compile benchmarks for evaluating LLM-as-a-judge and highlight key challenges and promising directions, aiming to provide valuable insights and inspire future research in this promising research area. Paper list and more resources about LLM-as-a-judge can be found at \url{https://github.com/llm-as-a-judge/Awesome-LLM-as-a-judge} and \url{https://llm-as-a-judge.github.io}.