 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models
Apr 03, 2026The recent success of reinforcement learning (RL) in large reasoning models has inspired the growing adoption of RL for post-training Multimodal Large Language Models (MLLMs) to enhance their visual reasoning capabilities. Although many studies have reported improved performance, it remains unclear whether RL training truly enables models to learn from visual information. In this work, we propose the Hallucination-as-Cue Framework, an analytical framework designed to investigate the effects of RL-based post-training on multimodal reasoning models from the perspective of model hallucination. Specifically, we introduce hallucination-inductive, modality-specific corruptions that remove or replace essential information required to derive correct answers, thereby forcing the model to reason by hallucination. By applying these corruptions during both training and evaluation, our framework provides a unique perspective for diagnosing RL training dynamics and understanding the intrinsic properties of datasets. Through extensive experiments and analyses across multiple multimodal reasoning benchmarks, we reveal that the role of model hallucination for RL-training is more significant than previously recognized. For instance, we find that RL post-training under purely hallucination-inductive settings can still significantly improve models' reasoning performance, and in some cases even outperform standard training. These findings challenge prevailing assumptions about MLLM reasoning training and motivate the development of more modality-aware RL-based training designs.
TAPFormer: Robust Arbitrary Point Tracking via Transient Asynchronous Fusion of Frames and Events
Mar 05, 2026Tracking any point (TAP) is a fundamental yet challenging task in computer vision, requiring high precision and long-term motion reasoning. Recent attempts to combine RGB frames and event streams have shown promise, yet they typically rely on synchronous or non-adaptive fusion, leading to temporal misalignment and severe degradation when one modality fails. We introduce TAPFormer, a transformer-based framework that performs asynchronous temporal-consistent fusion of frames and events for robust and high-frequency arbitrary point tracking. Our key innovation is a Transient Asynchronous Fusion (TAF) mechanism, which explicitly models the temporal evolution between discrete frames through continuous event updates, bridging the gap between low-rate frames and high-rate events. In addition, a Cross-modal Locally Weighted Fusion (CLWF) module adaptively adjusts spatial attention according to modality reliability, yielding stable and discriminative features even under blur or low light. To evaluate our approach under realistic conditions, we construct a novel real-world frame-event TAP dataset under diverse illumination and motion conditions. Our method outperforms existing point trackers, achieving a 28.2% improvement in average pixel error within threshold. Moreover, on standard point tracking benchmarks, our tracker consistently achieves the best performance. Project website: tapformer.github.io
TMS: Trajectory-Mixed Supervision for Reward-Free, On-Policy SFT
Feb 03, 2026Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) are the two dominant paradigms for enhancing Large Language Model (LLM) performance on downstream tasks. While RL generally preserves broader model capabilities (retention) better than SFT, it comes with significant costs: complex reward engineering, instability, and expensive on-policy sampling. In contrast, SFT is efficient but brittle, often suffering from catastrophic forgetting due to $\textbf{Supervision Mismatch}$: the divergence between the model's evolving policy and static training labels. We address this trade-off with $\textbf{Trajectory-Mixed Supervision (TMS)}$, a reward-free framework that approximates the on-policy benefits of RL by creating a dynamic curriculum from the model's own historical checkpoints. TMS minimizes $\textit{Policy-Label Divergence (PLD)}$, preventing the mode collapse that drives forgetting in standard SFT. Experiments across reasoning (MATH, GSM8K) and instruction-following benchmarks demonstrate that TMS effectively shifts the accuracy--retention Pareto frontier. While RL remains the gold standard for retention, TMS significantly outperforms standard and iterative SFT, bridging the gap to RL without requiring reward models or verifiers. Mechanistic analysis confirms that PLD drift accurately predicts forgetting and that TMS successfully mitigates this drift.
ToolPRMBench: Evaluating and Advancing Process Reward Models for Tool-using Agents
Jan 18, 2026Reward-guided search methods have demonstrated strong potential in enhancing tool-using agents by effectively guiding sampling and exploration over complex action spaces. As a core design, those search methods utilize process reward models (PRMs) to provide step-level rewards, enabling more fine-grained monitoring. However, there is a lack of systematic and reliable evaluation benchmarks for PRMs in tool-using settings. In this paper, we introduce ToolPRMBench, a large-scale benchmark specifically designed to evaluate PRMs for tool-using agents. ToolPRMBench is built on top of several representative tool-using benchmarks and converts agent trajectories into step-level test cases. Each case contains the interaction history, a correct action, a plausible but incorrect alternative, and relevant tool metadata. We respectively utilize offline sampling to isolate local single-step errors and online sampling to capture realistic multi-step failures from full agent rollouts. A multi-LLM verification pipeline is proposed to reduce label noise and ensure data quality. We conduct extensive experiments across large language models, general PRMs, and tool-specialized PRMs on ToolPRMBench. The results reveal clear differences in PRM effectiveness and highlight the potential of specialized PRMs for tool-using. Code and data will be released at https://github.com/David-Li0406/ToolPRMBench.
OR-R1: Automating Modeling and Solving of Operations Research Optimization Problem via Test-Time Reinforcement Learning
Nov 12, 2025Optimization modeling and solving are fundamental to the application of Operations Research (OR) in real-world decision making, yet the process of translating natural language problem descriptions into formal models and solver code remains highly expertise intensive. While recent advances in large language models (LLMs) have opened new opportunities for automation, the generalization ability and data efficiency of existing LLM-based methods are still limited, asmost require vast amounts of annotated or synthetic data, resulting in high costs and scalability barriers. In this work, we present OR-R1, a data-efficient training framework for automated optimization modeling and solving. OR-R1 first employs supervised fine-tuning (SFT) to help the model acquire the essential reasoning patterns for problem formulation and code generation from limited labeled data. In addition, it improves the capability and consistency through Test-Time Group Relative Policy Optimization (TGRPO). This two-stage design enables OR-R1 to leverage both scarce labeled and abundant unlabeled data for effective learning. Experiments show that OR-R1 achieves state-of-the-art performance with an average solving accuracy of $67.7\%$, using only $1/10$ the synthetic data required by prior methods such as ORLM, exceeding ORLM's solving accuracy by up to $4.2\%$. Remarkably, OR-R1 outperforms ORLM by over $2.4\%$ with just $100$ synthetic samples. Furthermore, TGRPO contributes an additional $3.1\%-6.4\%$ improvement in accuracy, significantly narrowing the gap between single-attempt (Pass@1) and multi-attempt (Pass@8) performance from $13\%$ to $7\%$. Extensive evaluations across diverse real-world benchmarks demonstrate that OR-R1 provides a robust, scalable, and cost-effective solution for automated OR optimization problem modeling and solving, lowering the expertise and data barriers for industrial OR applications.
Beyond Redundancy: Diverse and Specialized Multi-Expert Sparse Autoencoder
Nov 07, 2025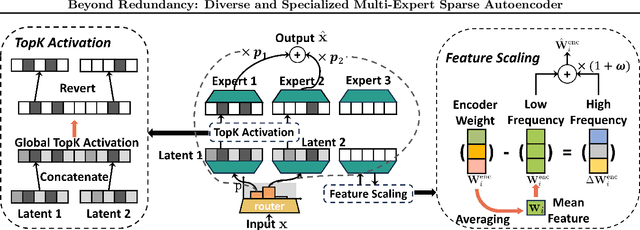
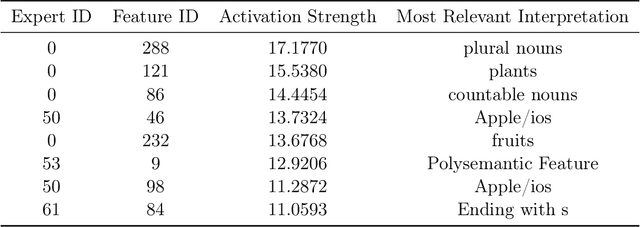
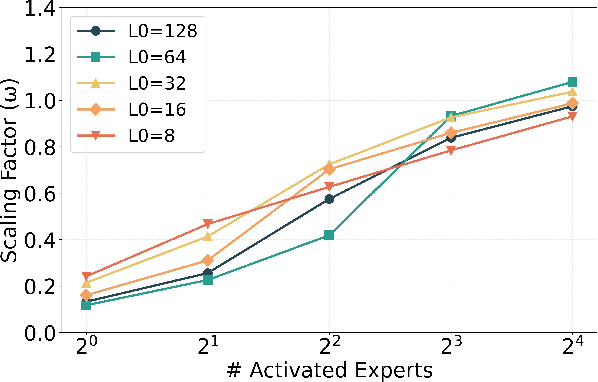
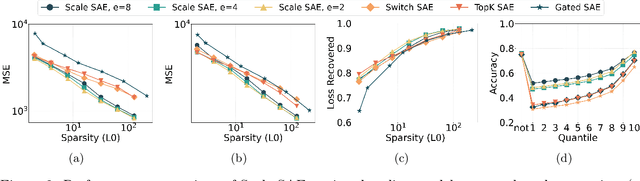
Sparse autoencoders (SAEs) have emerged as a powerful tool for interpreting large language models (LLMs) by decomposing token activations into combinations of human-understandable features. While SAEs provide crucial insights into LLM explanations, their practical adoption faces a fundamental challenge: better interpretability demands that SAEs' hidden layers have high dimensionality to satisfy sparsity constraints, resulting in prohibitive training and inference costs. Recent Mixture of Experts (MoE) approaches attempt to address this by partitioning SAEs into narrower expert networks with gated activation, thereby reducing computation. In a well-designed MoE, each expert should focus on learning a distinct set of features. However, we identify a \textit{critical limitation} in MoE-SAE: Experts often fail to specialize, which means they frequently learn overlapping or identical features. To deal with it, we propose two key innovations: (1) Multiple Expert Activation that simultaneously engages semantically weighted expert subsets to encourage specialization, and (2) Feature Scaling that enhances diversity through adaptive high-frequency scaling. Experiments demonstrate a 24\% lower reconstruction error and a 99\% reduction in feature redundancy compared to existing MoE-SAE methods. This work bridges the interpretability-efficiency gap in LLM analysis, allowing transparent model inspection without compromising computational feasibility.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
Multi-Agent Debate for LLM Judges with Adaptive Stability Detection
Oct 14, 2025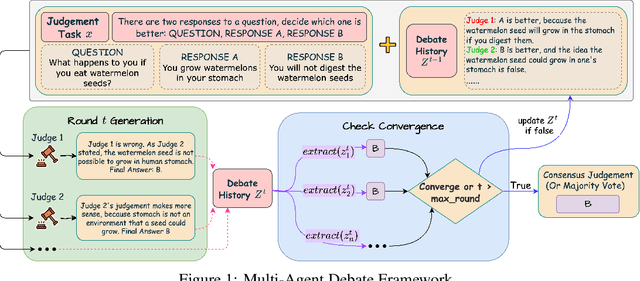
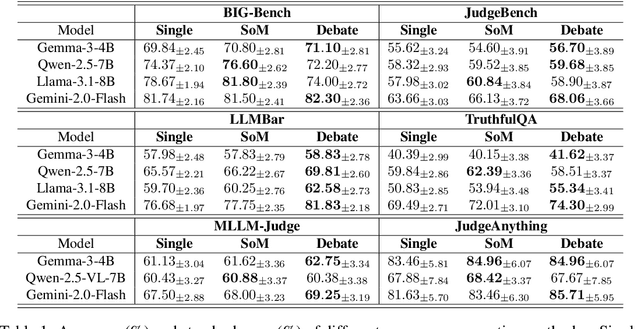
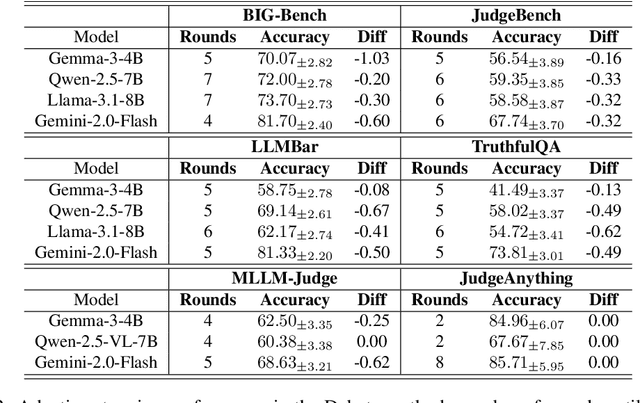
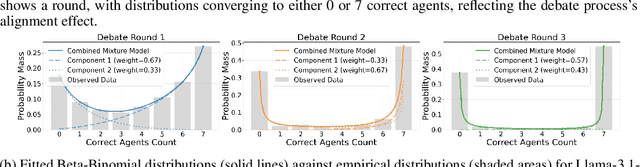
With advancements in reasoning capabilities, Large Language Models (LLMs) are increasingly employed for automated judgment tasks. While LLMs-as-Judges offer promise in automating evaluations, current approaches often rely on simplistic aggregation methods (e.g., majority voting), which can fail even when individual agents provide correct answers. To address this, we propose a multi-agent debate judge framework where agents collaboratively reason and iteratively refine their responses. We formalize the debate process mathematically, analyzing agent interactions and proving that debate amplifies correctness compared to static ensembles. To enhance efficiency, we introduce a stability detection mechanism that models judge consensus dynamics via a time-varying Beta-Binomial mixture, with adaptive stopping based on distributional similarity (Kolmogorov-Smirnov test). This mechanism models the judges' collective correct rate dynamics using a time-varying mixture of Beta-Binomial distributions and employs an adaptive stopping criterion based on distributional similarity (Kolmogorov-Smirnov statistic). Experiments across multiple benchmarks and models demonstrate that our framework improves judgment accuracy over majority voting while maintaining computational efficiency.
Learning from Diverse Reasoning Paths with Routing and Collaboration
Aug 23, 2025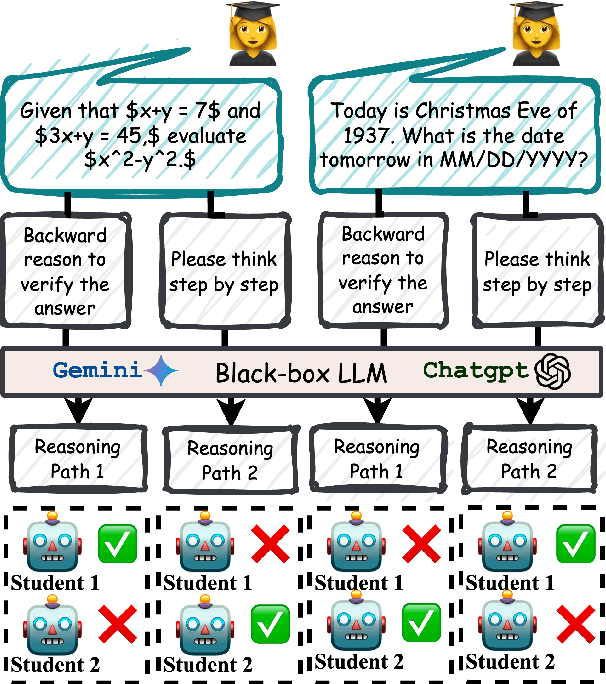
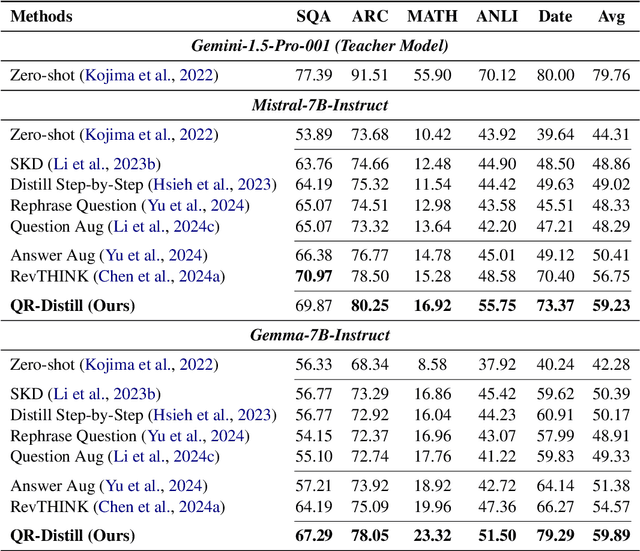
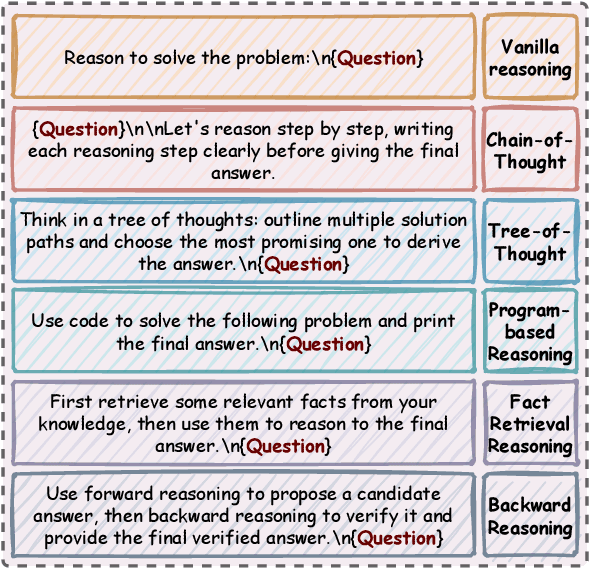
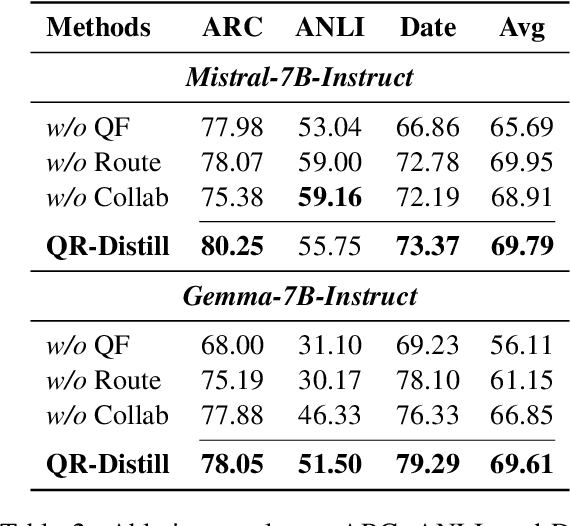
Advances in large language models (LLMs) significantly enhance reasoning capabilities but their deployment is restricted in resource-constrained scenarios. Knowledge distillation addresses this by transferring knowledge from powerful teacher models to compact and transparent students. However, effectively capturing the teacher's comprehensive reasoning is challenging due to conventional token-level supervision's limited scope. Using multiple reasoning paths per query alleviates this problem, but treating each path identically is suboptimal as paths vary widely in quality and suitability across tasks and models. We propose Quality-filtered Routing with Cooperative Distillation (QR-Distill), combining path quality filtering, conditional routing, and cooperative peer teaching. First, quality filtering retains only correct reasoning paths scored by an LLM-based evaluation. Second, conditional routing dynamically assigns paths tailored to each student's current learning state. Finally, cooperative peer teaching enables students to mutually distill diverse insights, addressing knowledge gaps and biases toward specific reasoning styles. Experiments demonstrate QR-Distill's superiority over traditional single- and multi-path distillation methods. Ablation studies further highlight the importance of each component including quality filtering, conditional routing, and peer teaching in effective knowledge transfer. Our code is available at https://github.com/LzyFischer/Distill.
Transferring Expert Cognitive Models to Social Robots via Agentic Concept Bottleneck Models
Aug 06, 2025Successful group meetings, such as those implemented in group behavioral-change programs, work meetings, and other social contexts, must promote individual goal setting and execution while strengthening the social relationships within the group. Consequently, an ideal facilitator must be sensitive to the subtle dynamics of disengagement, difficulties with individual goal setting and execution, and interpersonal difficulties that signal a need for intervention. The challenges and cognitive load experienced by facilitators create a critical gap for an embodied technology that can interpret social exchanges while remaining aware of the needs of the individuals in the group and providing transparent recommendations that go beyond powerful but "black box" foundation models (FMs) that identify social cues. We address this important demand with a social robot co-facilitator that analyzes multimodal meeting data and provides discreet cues to the facilitator. The robot's reasoning is powered by an agentic concept bottleneck model (CBM), which makes decisions based on human-interpretable concepts like participant engagement and sentiments, ensuring transparency and trustworthiness. Our core contribution is a transfer learning framework that distills the broad social understanding of an FM into our specialized and transparent CBM. This concept-driven system significantly outperforms direct zero-shot FMs in predicting the need for intervention and enables real-time human correction of its reasoning. Critically, we demonstrate robust knowledge transfer: the model generalizes across different groups and successfully transfers the expertise of senior human facilitators to improve the performance of novices. By transferring an expert's cognitive model into an interpretable robotic partner, our work provides a powerful blueprint for augmenting human capabilities in complex social domains.