 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove the Trade-off Between Watermark Strength and Speculative Sampling Efficiency for Language Models
Feb 01, 2026Watermarking is a principled approach for tracing the provenance of large language model (LLM) outputs, but its deployment in practice is hindered by inference inefficiency. Speculative sampling accelerates inference, with efficiency improving as the acceptance rate between draft and target models increases. Yet recent work reveals a fundamental trade-off: higher watermark strength reduces acceptance, preventing their simultaneous achievement. We revisit this trade-off and show it is not absolute. We introduce a quantitative measure of watermark strength that governs statistical detectability and is maximized when tokens are deterministic functions of pseudorandom numbers. Using this measure, we fully characterize the trade-off as a constrained optimization problem and derive explicit Pareto curves for two existing watermarking schemes. Finally, we introduce a principled mechanism that injects pseudorandomness into draft-token acceptance, ensuring maximal watermark strength while maintaining speculative sampling efficiency. Experiments further show that this approach improves detectability without sacrificing efficiency. Our findings uncover a principle that unites speculative sampling and watermarking, paving the way for their efficient and practical deployment.
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation
Sep 11, 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remain challenging due to dataset limitations. Existing datasets often lack extensive, high-quality motion and annotation and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark featuring dataset and methodological advancements. First, we consolidate and standardize 21.81 hours of HOI data from diverse sources, enriching it with detailed textual annotations. Second, we propose a unified optimization framework to enhance data quality by reducing artifacts and correcting hand motions. Leveraging the principle of contact invariance, we maintain human-object relationships while introducing motion variations, expanding the dataset to 30.70 hours. Third, we define six benchmarking tasks and develop a unified HOI generative modeling perspective, achieving state-of-the-art performance. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. To support continued research in this area, the dataset is publicly available at https://github.com/wzyabcas/InterAct, and will be actively maintained.
Theoretical Tensions in RLHF: Reconciling Empirical Success with Inconsistencies in Social Choice Theory
Jun 14, 2025Despite its empirical success, Reinforcement Learning from Human Feedback (RLHF) has been shown to violate almost all the fundamental axioms in social choice theory -- such as majority consistency, pairwise majority consistency, and Condorcet consistency. This raises a foundational question: why does RLHF perform so well in practice if it fails these seemingly essential properties? In this paper, we resolve this paradox by showing that under mild and empirically plausible assumptions on the preference profile, RLHF does satisfy pairwise majority and Condorcet consistency. These assumptions are frequently satisfied in real-world alignment tasks, offering a theoretical explanation for RLHF's strong practical performance. Furthermore, we show that a slight modification to the reward modeling objective can ensure pairwise majority or Condorcet consistency even under general preference profiles, thereby improving the alignment process. Finally, we go beyond classical axioms in economic and social choice theory and introduce new alignment criteria -- preference matching, preference equivalence, and group preference matching -- that better reflect the goal of learning distributions over responses. We show that while RLHF satisfies the first two properties, it fails to satisfy the third. We conclude by discussing how future alignment methods may be designed to satisfy all three.
Fundamental Limits of Game-Theoretic LLM Alignment: Smith Consistency and Preference Matching
May 27, 2025Nash Learning from Human Feedback is a game-theoretic framework for aligning large language models (LLMs) with human preferences by modeling learning as a two-player zero-sum game. However, using raw preference as the payoff in the game highly limits the potential of the game-theoretic LLM alignment framework. In this paper, we systematically study using what choices of payoff based on the pairwise human preferences can yield desirable alignment properties. We establish necessary and sufficient conditions for Condorcet consistency, diversity through mixed strategies, and Smith consistency. These results provide a theoretical foundation for the robustness of game-theoretic LLM alignment. Further, we show the impossibility of preference matching -- i.e., no smooth and learnable mappings of pairwise preferences can guarantee a unique Nash equilibrium that matches a target policy, even under standard assumptions like the Bradley-Terry-Luce model. This result highlights the fundamental limitation of game-theoretic LLM alignment.
PolarGrad: A Class of Matrix-Gradient Optimizers from a Unifying Preconditioning Perspective
May 27, 2025The ever-growing scale of deep learning models and datasets underscores the critical importance of efficient optimization methods. While preconditioned gradient methods such as Adam and AdamW are the de facto optimizers for training neural networks and large language models, structure-aware preconditioned optimizers like Shampoo and Muon, which utilize the matrix structure of gradients, have demonstrated promising evidence of faster convergence. In this paper, we introduce a unifying framework for analyzing "matrix-aware" preconditioned methods, which not only sheds light on the effectiveness of Muon and related optimizers but also leads to a class of new structure-aware preconditioned methods. A key contribution of this framework is its precise distinction between preconditioning strategies that treat neural network weights as vectors (addressing curvature anisotropy) versus those that consider their matrix structure (addressing gradient anisotropy). This perspective provides new insights into several empirical phenomena in language model pre-training, including Adam's training instabilities, Muon's accelerated convergence, and the necessity of learning rate warmup for Adam. Building upon this framework, we introduce PolarGrad, a new class of preconditioned optimization methods based on the polar decomposition of matrix-valued gradients. As a special instance, PolarGrad includes Muon with updates scaled by the nuclear norm of the gradients. We provide numerical implementations of these methods, leveraging efficient numerical polar decomposition algorithms for enhanced convergence. Our extensive evaluations across diverse matrix optimization problems and language model pre-training tasks demonstrate that PolarGrad outperforms both Adam and Muon.
I2MoE: Interpretable Multimodal Interaction-aware Mixture-of-Experts
May 25, 2025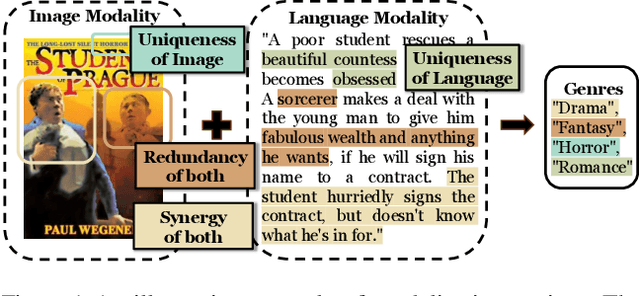
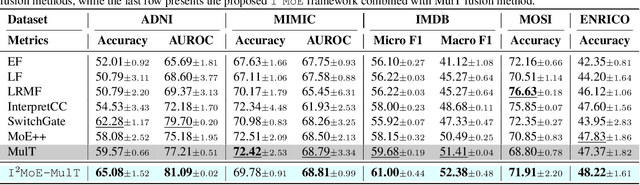

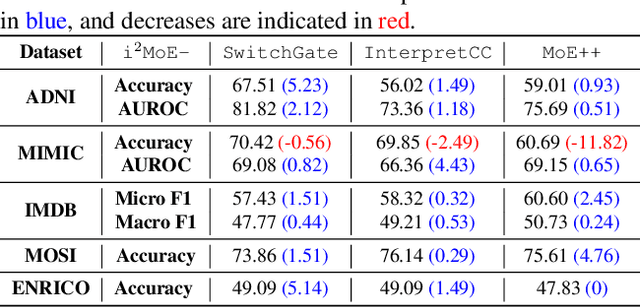
Modality fusion is a cornerstone of multimodal learning, enabling information integration from diverse data sources. However, vanilla fusion methods are limited by (1) inability to account for heterogeneous interactions between modalities and (2) lack of interpretability in uncovering the multimodal interactions inherent in the data. To this end, we propose I2MoE (Interpretable Multimodal Interaction-aware Mixture of Experts), an end-to-end MoE framework designed to enhance modality fusion by explicitly modeling diverse multimodal interactions, as well as providing interpretation on a local and global level. First, I2MoE utilizes different interaction experts with weakly supervised interaction losses to learn multimodal interactions in a data-driven way. Second, I2MoE deploys a reweighting model that assigns importance scores for the output of each interaction expert, which offers sample-level and dataset-level interpretation. Extensive evaluation of medical and general multimodal datasets shows that I2MoE is flexible enough to be combined with different fusion techniques, consistently improves task performance, and provides interpretation across various real-world scenarios. Code is available at https://github.com/Raina-Xin/I2MoE.
Restoring Calibration for Aligned Large Language Models: A Calibration-Aware Fine-Tuning Approach
May 04, 2025



One of the key technologies for the success of Large Language Models (LLMs) is preference alignment. However, a notable side effect of preference alignment is poor calibration: while the pre-trained models are typically well-calibrated, LLMs tend to become poorly calibrated after alignment with human preferences. In this paper, we investigate why preference alignment affects calibration and how to address this issue. For the first question, we observe that the preference collapse issue in alignment undesirably generalizes to the calibration scenario, causing LLMs to exhibit overconfidence and poor calibration. To address this, we demonstrate the importance of fine-tuning with domain-specific knowledge to alleviate the overconfidence issue. To further analyze whether this affects the model's performance, we categorize models into two regimes: calibratable and non-calibratable, defined by bounds of Expected Calibration Error (ECE). In the calibratable regime, we propose a calibration-aware fine-tuning approach to achieve proper calibration without compromising LLMs' performance. However, as models are further fine-tuned for better performance, they enter the non-calibratable regime. For this case, we develop an EM-algorithm-based ECE regularization for the fine-tuning loss to maintain low calibration error. Extensive experiments validate the effectiveness of the proposed methods.
Efficient MAP Estimation of LLM Judgment Performance with Prior Transfer
Apr 17, 2025



LLM ensembles are widely used for LLM judges. However, how to estimate their accuracy, especially in an efficient way, is unknown. In this paper, we present a principled maximum a posteriori (MAP) framework for an economical and precise estimation of the performance of LLM ensemble judgment. We first propose a mixture of Beta-Binomial distributions to model the judgment distribution, revising from the vanilla Binomial distribution. Next, we introduce a conformal prediction-driven approach that enables adaptive stopping during iterative sampling to balance accuracy with efficiency. Furthermore, we design a prior transfer mechanism that utilizes learned distributions on open-source datasets to improve estimation on a target dataset when only scarce annotations are available. Finally, we present BetaConform, a framework that integrates our distribution assumption, adaptive stopping, and the prior transfer mechanism to deliver a theoretically guaranteed distribution estimation of LLM ensemble judgment with minimum labeled samples. BetaConform is also validated empirically. For instance, with only 10 samples from the TruthfulQA dataset, for a Llama ensembled judge, BetaConform gauges its performance with error margin as small as 3.37%.
Statistical Impossibility and Possibility of Aligning LLMs with Human Preferences: From Condorcet Paradox to Nash Equilibrium
Mar 14, 2025Aligning large language models (LLMs) with diverse human preferences is critical for ensuring fairness and informed outcomes when deploying these models for decision-making. In this paper, we seek to uncover fundamental statistical limits concerning aligning LLMs with human preferences, with a focus on the probabilistic representation of human preferences and the preservation of diverse preferences in aligned LLMs. We first show that human preferences can be represented by a reward model if and only if the preference among LLM-generated responses is free of any Condorcet cycle. Moreover, we prove that Condorcet cycles exist with probability converging to one exponentially fast under a probabilistic preference model, thereby demonstrating the impossibility of fully aligning human preferences using reward-based approaches such as reinforcement learning from human feedback. Next, we explore the conditions under which LLMs would employ mixed strategies -- meaning they do not collapse to a single response -- when aligned in the limit using a non-reward-based approach, such as Nash learning from human feedback (NLHF). We identify a necessary and sufficient condition for mixed strategies: the absence of a response that is preferred over all others by a majority. As a blessing, we prove that this condition holds with high probability under the probabilistic preference model, thereby highlighting the statistical possibility of preserving minority preferences without explicit regularization in aligning LLMs. Finally, we leverage insights from our statistical results to design a novel, computationally efficient algorithm for finding Nash equilibria in aligning LLMs with NLHF. Our experiments show that Llama-3.2-1B, aligned with our algorithm, achieves a win rate of 60.55\% against the base model.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.