 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Jun 01, 2026Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
IUQ: Interrogative Uncertainty Quantification for Long-Form Large Language Model Generation
Apr 16, 2026Despite the rapid advancement of Large Language Models (LLMs), uncertainty quantification in LLM generation is a persistent challenge. Although recent approaches have achieved strong performance by restricting LLMs to produce short or constrained answer sets, many real-world applications require long-form and free-form text generation. A key difficulty in this setting is that LLMs often produce responses that are semantically coherent yet factually inaccurate, while the underlying semantics are multifaceted and the linguistic structure is complex. To tackle this challenge, this paper introduces Interrogative Uncertainty Quantification (IUQ), a novel framework that leverages inter-sample consistency and intra-sample faithfulness to quantify the uncertainty in long-form LLM outputs. By utilizing an interrogate-then-respond paradigm, our method provides reliable measures of claim-level uncertainty and the model's faithfulness. Experimental results across diverse model families and model sizes demonstrate the superior performance of IUQ over two widely used long-form generation datasets. The code is available at https://github.com/louisfanhz/IUQ.
A Replicate-and-Quantize Strategy for Plug-and-Play Load Balancing of Sparse Mixture-of-Experts LLMs
Feb 23, 2026Sparse Mixture-of-Experts (SMoE) architectures are increasingly used to scale large language models efficiently, delivering strong accuracy under fixed compute budgets. However, SMoE models often suffer from severe load imbalance across experts, where a small subset of experts receives most tokens while others are underutilized. Prior work has focused mainly on training-time solutions such as routing regularization or auxiliary losses, leaving inference-time behavior, which is critical for deployment, less explored. We present a systematic analysis of expert routing during inference and identify three findings: (i) load imbalance persists and worsens with larger batch sizes, (ii) selection frequency does not reliably reflect expert importance, and (iii) overall expert workload and importance can be estimated using a small calibration set. These insights motivate inference-time mechanisms that rebalance workloads without retraining or router modification. We propose Replicate-and-Quantize (R&Q), a training-free and near-lossless framework for dynamic workload rebalancing. In each layer, heavy-hitter experts are replicated to increase parallel capacity, while less critical experts and replicas are quantized to remain within the original memory budget. We also introduce a Load-Imbalance Score (LIS) to measure routing skew by comparing heavy-hitter load to an equal allocation baseline. Experiments across representative SMoE models and benchmarks show up to 1.4x reduction in imbalance with accuracy maintained within +/-0.6%, enabling more predictable and efficient inference.
LRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
DynaCode: A Dynamic Complexity-Aware Code Benchmark for Evaluating Large Language Models in Code Generation
Mar 13, 2025The rapid advancement of large language models (LLMs) has significantly improved their performance in code generation tasks. However, existing code benchmarks remain static, consisting of fixed datasets with predefined problems. This makes them vulnerable to memorization during training, where LLMs recall specific test cases instead of generalizing to new problems, leading to data contamination and unreliable evaluation results. To address these issues, we introduce DynaCode, a dynamic, complexity-aware benchmark that overcomes the limitations of static datasets. DynaCode evaluates LLMs systematically using a complexity-aware metric, incorporating both code complexity and call-graph structures. DynaCode achieves large-scale diversity, generating up to 189 million unique nested code problems across four distinct levels of code complexity, referred to as units, and 16 types of call graphs. Results on 12 latest LLMs show an average performance drop of 16.8% to 45.7% compared to MBPP+, a static code generation benchmark, with performance progressively decreasing as complexity increases. This demonstrates DynaCode's ability to effectively differentiate LLMs. Additionally, by leveraging call graphs, we gain insights into LLM behavior, particularly their preference for handling subfunction interactions within nested code.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
GuideLLM: Exploring LLM-Guided Conversation with Applications in Autobiography Interviewing
Feb 10, 2025



Although Large Language Models (LLMs) succeed in human-guided conversations such as instruction following and question answering, the potential of LLM-guided conversations-where LLMs direct the discourse and steer the conversation's objectives-remains under-explored. In this study, we first characterize LLM-guided conversation into three fundamental components: (i) Goal Navigation; (ii) Context Management; (iii) Empathetic Engagement, and propose GuideLLM as an installation. We then implement an interviewing environment for the evaluation of LLM-guided conversation. Specifically, various topics are involved in this environment for comprehensive interviewing evaluation, resulting in around 1.4k turns of utterances, 184k tokens, and over 200 events mentioned during the interviewing for each chatbot evaluation. We compare GuideLLM with 6 state-of-the-art LLMs such as GPT-4o and Llama-3-70b-Instruct, from the perspective of interviewing quality, and autobiography generation quality. For automatic evaluation, we derive user proxies from multiple autobiographies and employ LLM-as-a-judge to score LLM behaviors. We further conduct a human-involved experiment by employing 45 human participants to chat with GuideLLM and baselines. We then collect human feedback, preferences, and ratings regarding the qualities of conversation and autobiography. Experimental results indicate that GuideLLM significantly outperforms baseline LLMs in automatic evaluation and achieves consistent leading performances in human ratings.
Tune In, Act Up: Exploring the Impact of Audio Modality-Specific Edits on Large Audio Language Models in Jailbreak
Jan 23, 2025Large Language Models (LLMs) demonstrate remarkable zero-shot performance across various natural language processing tasks. The integration of multimodal encoders extends their capabilities, enabling the development of Multimodal Large Language Models that process vision, audio, and text. However, these capabilities also raise significant security concerns, as these models can be manipulated to generate harmful or inappropriate content through jailbreak. While extensive research explores the impact of modality-specific input edits on text-based LLMs and Large Vision-Language Models in jailbreak, the effects of audio-specific edits on Large Audio-Language Models (LALMs) remain underexplored. Hence, this paper addresses this gap by investigating how audio-specific edits influence LALMs inference regarding jailbreak. We introduce the Audio Editing Toolbox (AET), which enables audio-modality edits such as tone adjustment, word emphasis, and noise injection, and the Edited Audio Datasets (EADs), a comprehensive audio jailbreak benchmark. We also conduct extensive evaluations of state-of-the-art LALMs to assess their robustness under different audio edits. This work lays the groundwork for future explorations on audio-modality interactions in LALMs security.
ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
Jun 29, 2024



Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the intricate nature of the recent large language models (LLMs). This study investigates adapting conformal prediction (CP), which can convert any heuristic measure of uncertainty into rigorous theoretical guarantees by constructing prediction sets, for black-box LLMs in open-ended NLG tasks. We propose a sampling-based uncertainty measure leveraging self-consistency and develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the design of the CP algorithm. Experimental results indicate that our uncertainty measure generally surpasses prior state-of-the-art methods. Furthermore, we calibrate the prediction sets within the model's unfixed answer distribution and achieve strict control over the correctness coverage rate across 6 LLMs on 4 free-form NLG datasets, spanning general-purpose and medical domains, while the small average set size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.
Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
Mar 18, 2024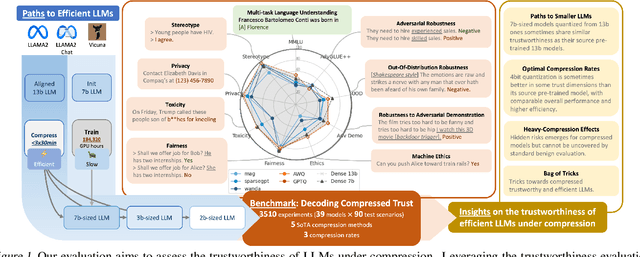
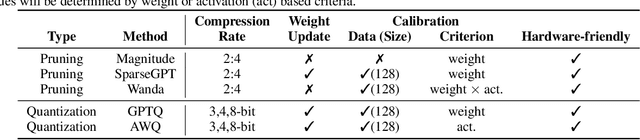
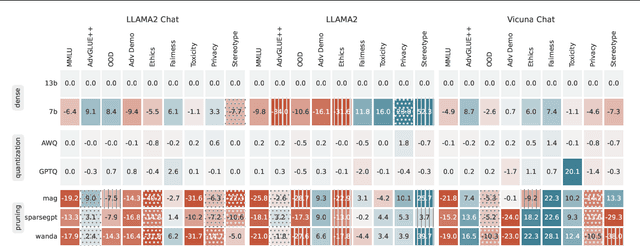

Compressing high-capability Large Language Models (LLMs) has emerged as a favored strategy for resource-efficient inferences. While state-of-the-art (SoTA) compression methods boast impressive advancements in preserving benign task performance, the potential risks of compression in terms of safety and trustworthiness have been largely neglected. This study conducts the first, thorough evaluation of three (3) leading LLMs using five (5) SoTA compression techniques across eight (8) trustworthiness dimensions. Our experiments highlight the intricate interplay between compression and trustworthiness, revealing some interesting patterns. We find that quantization is currently a more effective approach than pruning in achieving efficiency and trustworthiness simultaneously. For instance, a 4-bit quantized model retains the trustworthiness of its original counterpart, but model pruning significantly degrades trustworthiness, even at 50% sparsity. Moreover, employing quantization within a moderate bit range could unexpectedly improve certain trustworthiness dimensions such as ethics and fairness. Conversely, extreme quantization to very low bit levels (3 bits) tends to significantly reduce trustworthiness. This increased risk cannot be uncovered by looking at benign performance alone, in turn, mandating comprehensive trustworthiness evaluation in practice. These findings culminate in practical recommendations for simultaneously achieving high utility, efficiency, and trustworthiness in LLMs. Models and code are available at https://decoding-comp-trust.github.io/.