 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Denoising Diffusion Codebook Models (gDDCM): Tokenizing images using a pre-trained diffusion model
Nov 18, 2025Recently, the Denoising Diffusion Codebook Models (DDCM) was proposed. DDCM leverages the Denoising Diffusion Probabilistic Model (DDPM) and replaces the random noise in the backward process with noise sampled from specific sets according to a predefined rule, thereby enabling image compression. However, DDCM cannot be applied to methods other than DDPM. In this paper, we propose the generalized Denoising Diffusion Compression Model (gDDCM), which extends DDCM to mainstream diffusion models and their variants, including DDPM, Score-Based Models, Consistency Models, and Rectified Flow. We evaluate our method on CIFAR-10 and LSUN Bedroom datasets. Experimental results demonstrate that our approach successfully generalizes DDCM to the aforementioned models and achieves improved performance.
PhaseNAS: Language-Model Driven Architecture Search with Dynamic Phase Adaptation
Jul 28, 2025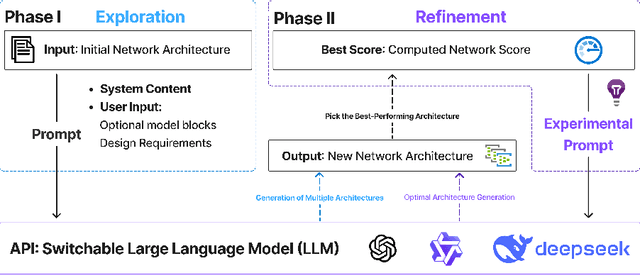
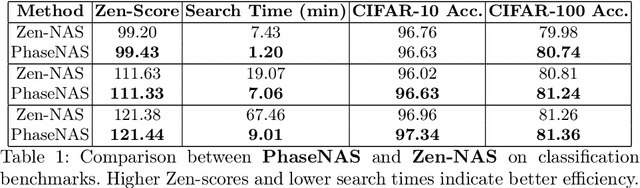
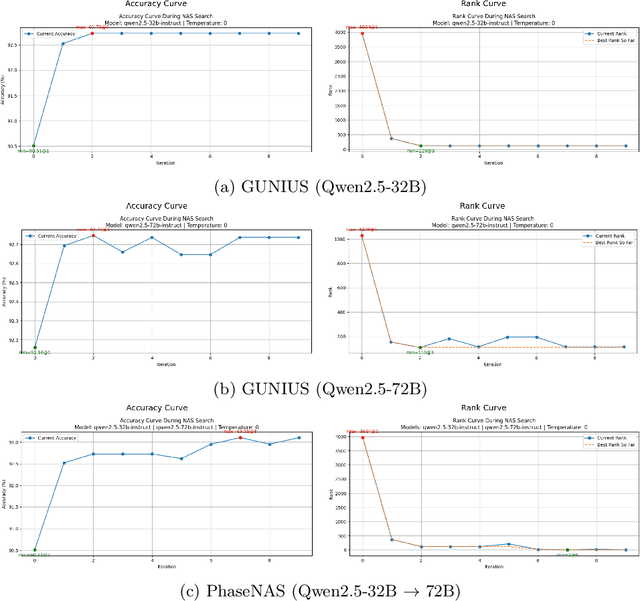
Neural Architecture Search (NAS) is challenged by the trade-off between search space exploration and efficiency, especially for complex tasks. While recent LLM-based NAS methods have shown promise, they often suffer from static search strategies and ambiguous architecture representations. We propose PhaseNAS, an LLM-based NAS framework with dynamic phase transitions guided by real-time score thresholds and a structured architecture template language for consistent code generation. On the NAS-Bench-Macro benchmark, PhaseNAS consistently discovers architectures with higher accuracy and better rank. For image classification (CIFAR-10/100), PhaseNAS reduces search time by up to 86% while maintaining or improving accuracy. In object detection, it automatically produces YOLOv8 variants with higher mAP and lower resource cost. These results demonstrate that PhaseNAS enables efficient, adaptive, and generalizable NAS across diverse vision tasks.
LRR-Bench: Left, Right or Rotate? Vision-Language models Still Struggle With Spatial Understanding Tasks
Jul 27, 2025Real-world applications, such as autonomous driving and humanoid robot manipulation, require precise spatial perception. However, it remains underexplored how Vision-Language Models (VLMs) recognize spatial relationships and perceive spatial movement. In this work, we introduce a spatial evaluation pipeline and construct a corresponding benchmark. Specifically, we categorize spatial understanding into two main types: absolute spatial understanding, which involves querying the absolute spatial position (e.g., left, right) of an object within an image, and 3D spatial understanding, which includes movement and rotation. Notably, our dataset is entirely synthetic, enabling the generation of test samples at a low cost while also preventing dataset contamination. We conduct experiments on multiple state-of-the-art VLMs and observe that there is significant room for improvement in their spatial understanding abilities. Explicitly, in our experiments, humans achieve near-perfect performance on all tasks, whereas current VLMs attain human-level performance only on the two simplest tasks. For the remaining tasks, the performance of VLMs is distinctly lower than that of humans. In fact, the best-performing Vision-Language Models even achieve near-zero scores on multiple tasks. The dataset and code are available on https://github.com/kong13661/LRR-Bench.
TruthPrInt: Mitigating LVLM Object Hallucination Via Latent Truthful-Guided Pre-Intervention
Mar 13, 2025Object Hallucination (OH) has been acknowledged as one of the major trustworthy challenges in Large Vision-Language Models (LVLMs). Recent advancements in Large Language Models (LLMs) indicate that internal states, such as hidden states, encode the "overall truthfulness" of generated responses. However, it remains under-explored how internal states in LVLMs function and whether they could serve as "per-token" hallucination indicators, which is essential for mitigating OH. In this paper, we first conduct an in-depth exploration of LVLM internal states in relation to OH issues and discover that (1) LVLM internal states are high-specificity per-token indicators of hallucination behaviors. Moreover, (2) different LVLMs encode universal patterns of hallucinations in common latent subspaces, indicating that there exist "generic truthful directions" shared by various LVLMs. Based on these discoveries, we propose Truthful-Guided Pre-Intervention (TruthPrInt) that first learns the truthful direction of LVLM decoding and then applies truthful-guided inference-time intervention during LVLM decoding. We further propose ComnHallu to enhance both cross-LVLM and cross-data hallucination detection transferability by constructing and aligning hallucination latent subspaces. We evaluate TruthPrInt in extensive experimental settings, including in-domain and out-of-domain scenarios, over popular LVLMs and OH benchmarks. Experimental results indicate that TruthPrInt significantly outperforms state-of-the-art methods. Codes will be available at https://github.com/jinhaoduan/TruthPrInt.
ACT: Adversarial Consistency Models
Nov 23, 2023



Though diffusion models excel in image generation, their step-by-step denoising leads to slow generation speeds. Consistency training addresses this issue with single-step sampling but often produces lower-quality generations and requires high training costs. In this paper, we show that optimizing consistency training loss minimizes the Wasserstein distance between target and generated distributions. As timestep increases, the upper bound accumulates previous consistency training losses. Therefore, larger batch sizes are needed to reduce both current and accumulated losses. We propose Adversarial Consistency Training (ACT), which directly minimizes the Jensen-Shannon (JS) divergence between distributions at each timestep using a discriminator. Theoretically, ACT enhances generation quality, and convergence. By incorporating a discriminator into the consistency training framework, our method achieves improved FID scores on CIFAR10 and ImageNet 64$\times$64, retains zero-shot image inpainting capabilities, and uses less than $1/6$ of the original batch size and fewer than $1/2$ of the model parameters and training steps compared to the baseline method, this leads to a substantial reduction in resource consumption.
Exposing the Fake: Effective Diffusion-Generated Images Detection
Jul 12, 2023



Image synthesis has seen significant advancements with the advent of diffusion-based generative models like Denoising Diffusion Probabilistic Models (DDPM) and text-to-image diffusion models. Despite their efficacy, there is a dearth of research dedicated to detecting diffusion-generated images, which could pose potential security and privacy risks. This paper addresses this gap by proposing a novel detection method called Stepwise Error for Diffusion-generated Image Detection (SeDID). Comprising statistical-based $\text{SeDID}_{\text{Stat}}$ and neural network-based $\text{SeDID}_{\text{NNs}}$, SeDID exploits the unique attributes of diffusion models, namely deterministic reverse and deterministic denoising computation errors. Our evaluations demonstrate SeDID's superior performance over existing methods when applied to diffusion models. Thus, our work makes a pivotal contribution to distinguishing diffusion model-generated images, marking a significant step in the domain of artificial intelligence security.
An Efficient Membership Inference Attack for the Diffusion Model by Proximal Initialization
May 26, 2023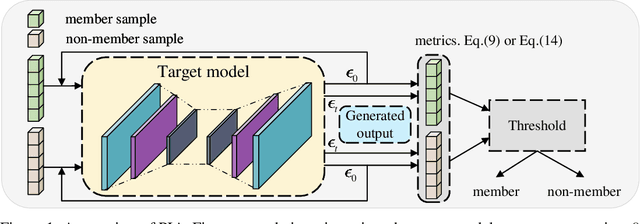
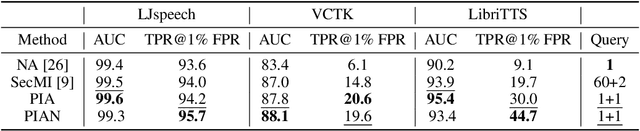
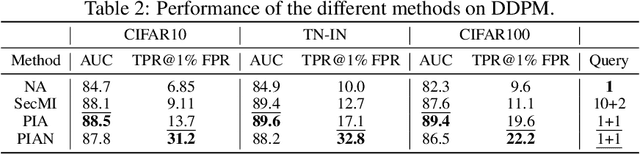
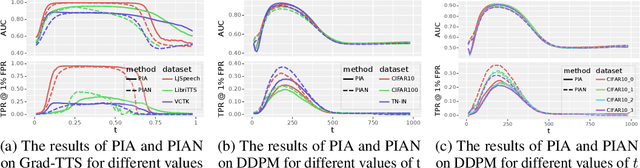
Recently, diffusion models have achieved remarkable success in generating tasks, including image and audio generation. However, like other generative models, diffusion models are prone to privacy issues. In this paper, we propose an efficient query-based membership inference attack (MIA), namely Proximal Initialization Attack (PIA), which utilizes groundtruth trajectory obtained by $\epsilon$ initialized in $t=0$ and predicted point to infer memberships. Experimental results indicate that the proposed method can achieve competitive performance with only two queries on both discrete-time and continuous-time diffusion models. Moreover, previous works on the privacy of diffusion models have focused on vision tasks without considering audio tasks. Therefore, we also explore the robustness of diffusion models to MIA in the text-to-speech (TTS) task, which is an audio generation task. To the best of our knowledge, this work is the first to study the robustness of diffusion models to MIA in the TTS task. Experimental results indicate that models with mel-spectrogram (image-like) output are vulnerable to MIA, while models with audio output are relatively robust to MIA. {Code is available at \url{https://github.com/kong13661/PIA}}.
Federated contrastive learning models for prostate cancer diagnosis and Gleason grading
Feb 17, 2023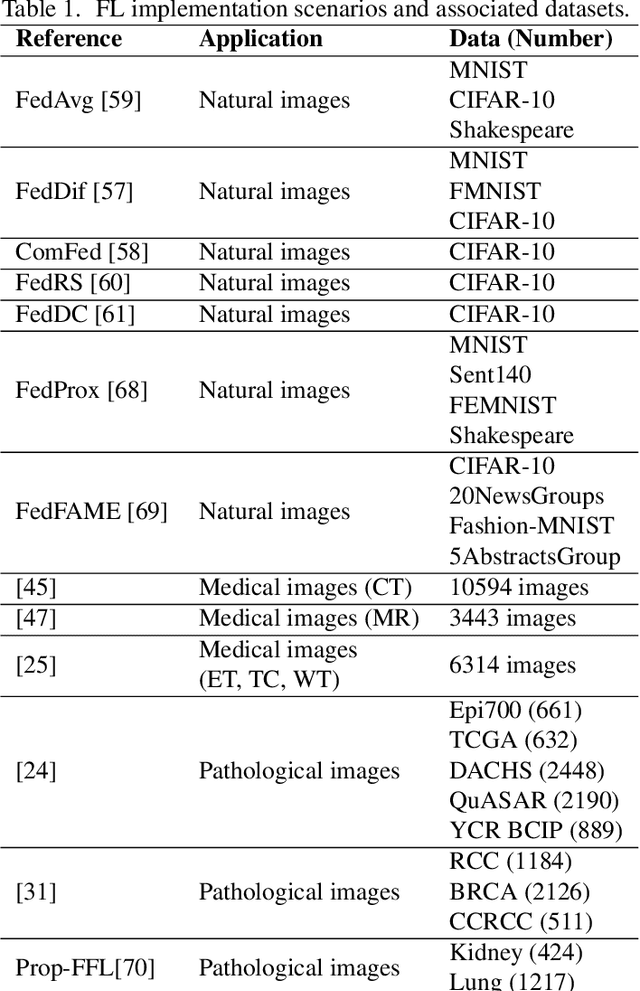
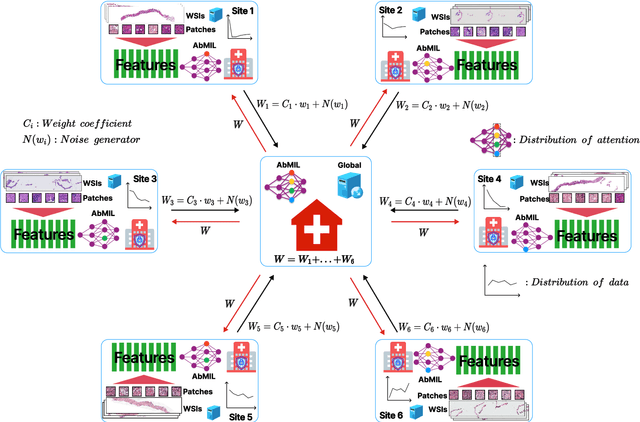
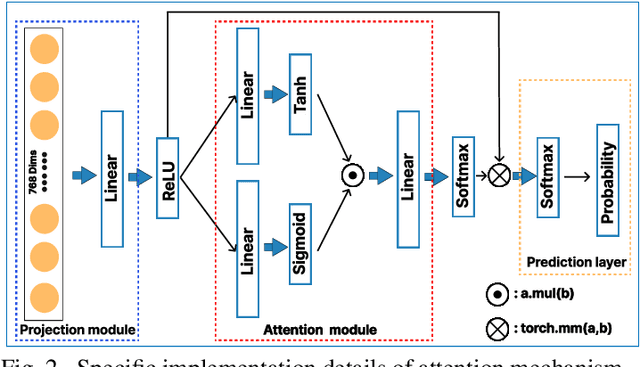
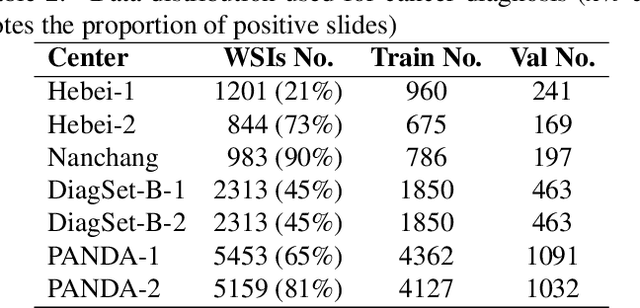
The application effect of artificial intelligence (AI) in the field of medical imaging is remarkable. Robust AI model training requires large datasets, but data collection faces communication, ethics, and privacy protection constraints. Fortunately, federated learning can solve the above problems by coordinating multiple clients to train the model without sharing the original data. In this study, we design a federated contrastive learning framework (FCL) for large-scale pathology images and the heterogeneity challenges. It enhances the model's generalization ability by maximizing the attention consistency between the local client and server models. To alleviate the privacy leakage problem when transferring parameters and verify the robustness of FCL, we use differential privacy to further protect the model by adding noise. We evaluate the effectiveness of FCL on the cancer diagnosis task and Gleason grading task on 19,635 prostate cancer WSIs from multiple clients. In the diagnosis task, the average AUC of 7 clients is 95% when the categories are relatively balanced, and our FCL achieves 97%. In the Gleason grading task, the average Kappa of 6 clients is 0.74, and the Kappa of FCL reaches 0.84. Furthermore, we also validate the robustness of the model on external datasets(one public dataset and two private datasets). In addition, to better explain the classification effect of the model, we show whether the model focuses on the lesion area by drawing a heatmap. Finally, FCL brings a robust, accurate, low-cost AI training model to biomedical research, effectively protecting medical data privacy.
Are Diffusion Models Vulnerable to Membership Inference Attacks?
Feb 02, 2023Diffusion-based generative models have shown great potential for image synthesis, but there is a lack of research on the security and privacy risks they may pose. In this paper, we investigate the vulnerability of diffusion models to Membership Inference Attacks (MIAs), a common privacy concern. Our results indicate that existing MIAs designed for GANs or VAE are largely ineffective on diffusion models, either due to inapplicable scenarios (e.g., requiring the discriminator of GANs) or inappropriate assumptions (e.g., closer distances between synthetic images and member images). To address this gap, we propose Step-wise Error Comparing Membership Inference (SecMI), a black-box MIA that infers memberships by assessing the matching of forward process posterior estimation at each timestep. SecMI follows the common overfitting assumption in MIA where member samples normally have smaller estimation errors, compared with hold-out samples. We consider both the standard diffusion models, e.g., DDPM, and the text-to-image diffusion models, e.g., Stable Diffusion. Experimental results demonstrate that our methods precisely infer the membership with high confidence on both of the two scenarios across six different datasets
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Jul 11, 2021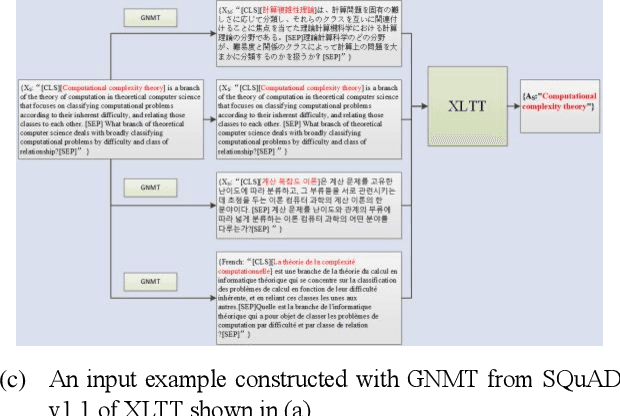
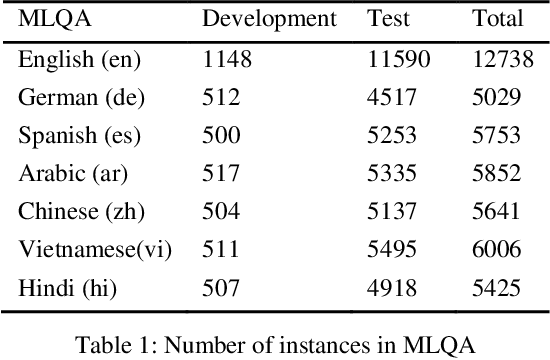
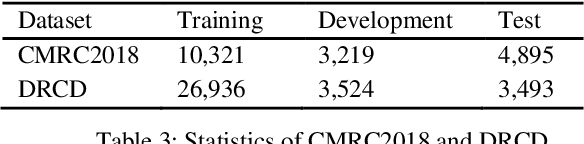
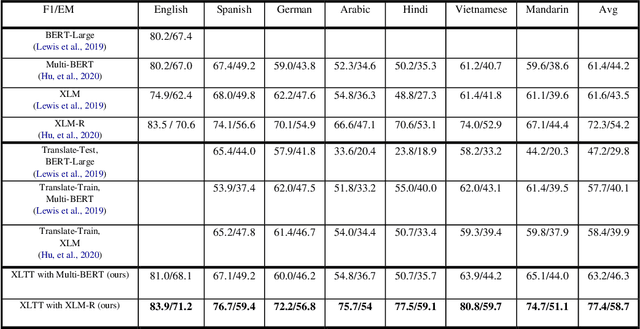
Extractive Reading Comprehension (ERC) has made tremendous advances enabled by the availability of large-scale high-quality ERC training data. Despite of such rapid progress and widespread application, the datasets in languages other than high-resource languages such as English remain scarce. To address this issue, we propose a Cross-Lingual Transposition ReThinking (XLTT) model by modelling existing high-quality extractive reading comprehension datasets in a multilingual environment. To be specific, we present multilingual adaptive attention (MAA) to combine intra-attention and inter-attention to learn more general generalizable semantic and lexical knowledge from each pair of language families. Furthermore, to make full use of existing datasets, we adopt a new training framework to train our model by calculating task-level similarities between each existing dataset and target dataset. The experimental results show that our XLTT model surpasses six baselines on two multilingual ERC benchmarks, especially more effective for low-resource languages with 3.9 and 4.1 average improvement in F1 and EM, respectively.