 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPP: Towards Automated Product Poster Generation and Optimization
Dec 26, 2025Product posters blend striking visuals with informative text to highlight the product and capture customer attention. However, crafting appealing posters and manually optimizing them based on online performance is laborious and resource-consuming. To address this, we introduce AutoPP, an automated pipeline for product poster generation and optimization that eliminates the need for human intervention. Specifically, the generator, relying solely on basic product information, first uses a unified design module to integrate the three key elements of a poster (background, text, and layout) into a cohesive output. Then, an element rendering module encodes these elements into condition tokens, efficiently and controllably generating the product poster. Based on the generated poster, the optimizer enhances its Click-Through Rate (CTR) by leveraging online feedback. It systematically replaces elements to gather fine-grained CTR comparisons and utilizes Isolated Direct Preference Optimization (IDPO) to attribute CTR gains to isolated elements. Our work is supported by AutoPP1M, the largest dataset specifically designed for product poster generation and optimization, which contains one million high-quality posters and feedback collected from over one million users. Experiments demonstrate that AutoPP achieves state-of-the-art results in both offline and online settings. Our code and dataset are publicly available at: https://github.com/JD-GenX/AutoPP
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data
Dec 31, 2021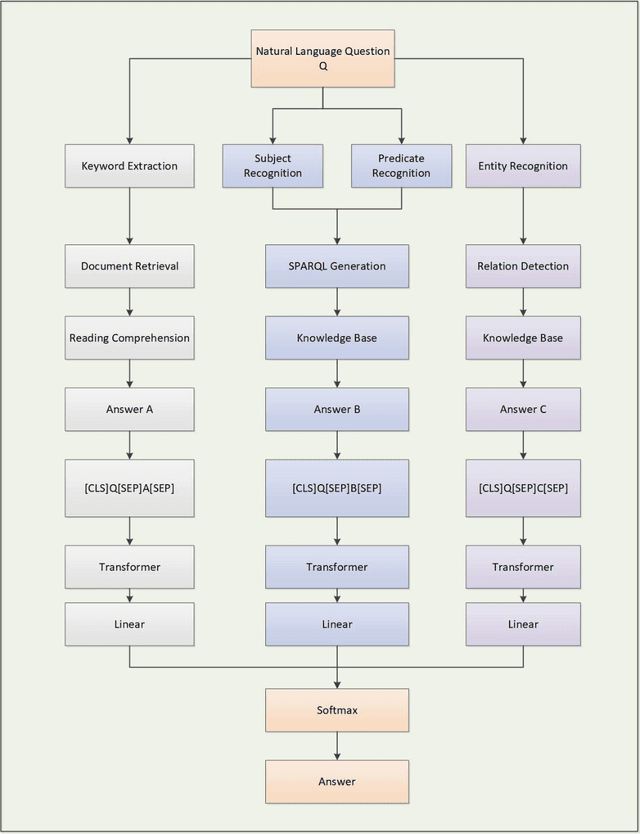
Search engines based on keyword retrieval can no longer adapt to the way of information acquisition in the era of intelligent Internet of Things due to the return of keyword related Internet pages. How to quickly, accurately and effectively obtain the information needed by users from massive Internet data has become one of the key issues urgently needed to be solved. We propose an intelligent question-answering system based on structured KB and unstructured data, called OpenQA, in which users can give query questions and the model can quickly give accurate answers back to users. We integrate KBQA structured question answering based on semantic parsing and deep representation learning, and two-stage unstructured question answering based on retrieval and neural machine reading comprehension into OpenQA, and return the final answer with the highest probability through the Transformer answer selection module in OpenQA. We carry out preliminary experiments on our constructed dataset, and the experimental results prove the effectiveness of the proposed intelligent question answering system. At the same time, the core technology of each module of OpenQA platform is still in the forefront of academic hot spots, and the theoretical essence and enrichment of OpenQA will be further explored based on these academic hot spots.
Improving Low-resource Reading Comprehension via Cross-lingual Transposition Rethinking
Jul 11, 2021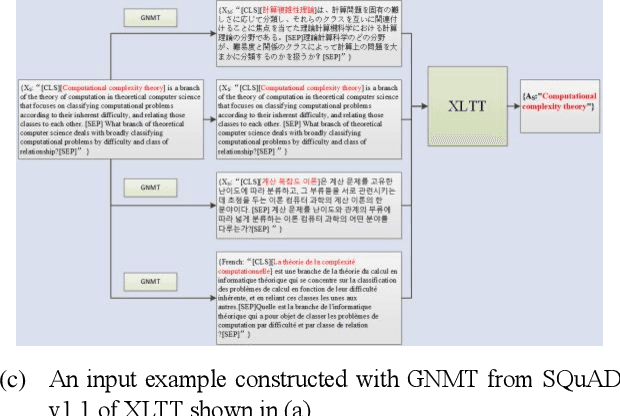
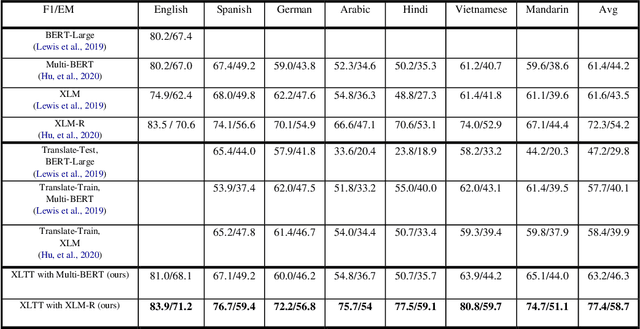
Extractive Reading Comprehension (ERC) has made tremendous advances enabled by the availability of large-scale high-quality ERC training data. Despite of such rapid progress and widespread application, the datasets in languages other than high-resource languages such as English remain scarce. To address this issue, we propose a Cross-Lingual Transposition ReThinking (XLTT) model by modelling existing high-quality extractive reading comprehension datasets in a multilingual environment. To be specific, we present multilingual adaptive attention (MAA) to combine intra-attention and inter-attention to learn more general generalizable semantic and lexical knowledge from each pair of language families. Furthermore, to make full use of existing datasets, we adopt a new training framework to train our model by calculating task-level similarities between each existing dataset and target dataset. The experimental results show that our XLTT model surpasses six baselines on two multilingual ERC benchmarks, especially more effective for low-resource languages with 3.9 and 4.1 average improvement in F1 and EM, respectively.
PatentMiner: Patent Vacancy Mining via Context-enhanced and Knowledge-guided Graph Attention
Jul 10, 2021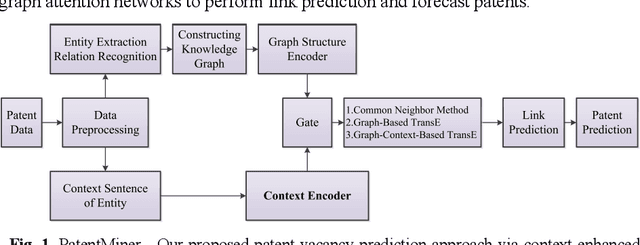
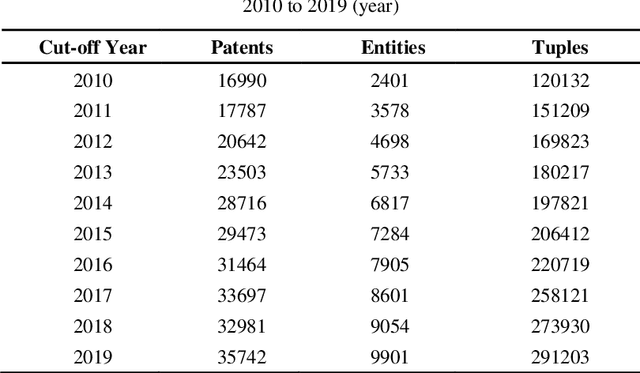
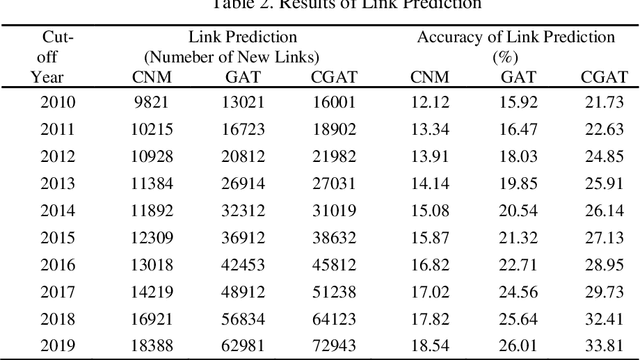
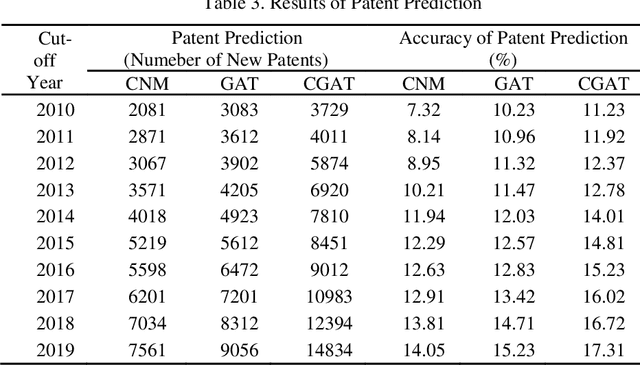
Although there are a small number of work to conduct patent research by building knowledge graph, but without constructing patent knowledge graph using patent documents and combining latest natural language processing methods to mine hidden rich semantic relationships in existing patents and predict new possible patents. In this paper, we propose a new patent vacancy prediction approach named PatentMiner to mine rich semantic knowledge and predict new potential patents based on knowledge graph (KG) and graph attention mechanism. Firstly, patent knowledge graph over time (e.g. year) is constructed by carrying out named entity recognition and relation extrac-tion from patent documents. Secondly, Common Neighbor Method (CNM), Graph Attention Networks (GAT) and Context-enhanced Graph Attention Networks (CGAT) are proposed to perform link prediction in the constructed knowledge graph to dig out the potential triples. Finally, patents are defined on the knowledge graph by means of co-occurrence relationship, that is, each patent is represented as a fully connected subgraph containing all its entities and co-occurrence relationships of the patent in the knowledge graph; Furthermore, we propose a new patent prediction task which predicts a fully connected subgraph with newly added prediction links as a new pa-tent. The experimental results demonstrate that our proposed patent predic-tion approach can correctly predict new patents and Context-enhanced Graph Attention Networks is much better than the baseline. Meanwhile, our proposed patent vacancy prediction task still has significant room to im-prove.