 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Video Diffusion Models Predict Past Frames? Bidirectional Cycle Consistency for Reversible Interpolation
Apr 02, 2026Video frame interpolation aims to synthesize realistic intermediate frames between given endpoints while adhering to specific motion semantics. While recent generative models have improved visual fidelity, they predominantly operate in a unidirectional manner, lacking mechanisms to self-verify temporal consistency. This often leads to motion drift, directional ambiguity, and boundary misalignment, especially in long-range sequences. Inspired by the principle of temporal cycle-consistency in self-supervised learning, we propose a novel bidirectional framework that enforces symmetry between forward and backward generation trajectories. Our approach introduces learnable directional tokens to explicitly condition a shared backbone on temporal orientation, enabling the model to jointly optimize forward synthesis and backward reconstruction within a single unified architecture. This cycle-consistent supervision acts as a powerful regularizer, ensuring that generated motion paths are logically reversible. Furthermore, we employ a curriculum learning strategy that progressively trains the model from short to long sequences, stabilizing dynamics across varying durations. Crucially, our cyclic constraints are applied only during training; inference requires a single forward pass, maintaining the high efficiency of the base model. Extensive experiments show that our method achieves state-of-the-art performance in imaging quality, motion smoothness, and dynamic control on both 37-frame and 73-frame tasks, outperforming strong baselines while incurring no additional computational overhead.
Look, Compare and Draw: Differential Query Transformer for Automatic Oil Painting
Mar 29, 2026This work introduces a new approach to automatic oil painting that emphasizes the creation of dynamic and expressive brushstrokes. A pivotal challenge lies in mitigating the duplicate and common-place strokes, which often lead to less aesthetic outcomes. Inspired by the human painting process, \ie, observing, comparing, and drawing, we incorporate differential image analysis into a neural oil painting model, allowing the model to effectively concentrate on the incremental impact of successive brushstrokes. To operationalize this concept, we propose the Differential Query Transformer (DQ-Transformer), a new architecture that leverages differentially derived image representations enriched with positional encoding to guide the stroke prediction process. This integration enables the model to maintain heightened sensitivity to local details, resulting in more refined and nuanced stroke generation. Furthermore, we incorporate adversarial training into our framework, enhancing the accuracy of stroke prediction and thereby improving the overall realism and fidelity of the synthesized paintings. Extensive qualitative evaluations, complemented by a controlled user study, validate that our DQ-Transformer surpasses existing methods in both visual realism and artistic authenticity, typically achieving these results with fewer strokes. The stroke-by-stroke painting animations are available on our project website.
Every Painting Awakened: A Training-free Framework for Painting-to-Animation Generation
Mar 31, 2025We introduce a training-free framework specifically designed to bring real-world static paintings to life through image-to-video (I2V) synthesis, addressing the persistent challenge of aligning these motions with textual guidance while preserving fidelity to the original artworks. Existing I2V methods, primarily trained on natural video datasets, often struggle to generate dynamic outputs from static paintings. It remains challenging to generate motion while maintaining visual consistency with real-world paintings. This results in two distinct failure modes: either static outputs due to limited text-based motion interpretation or distorted dynamics caused by inadequate alignment with real-world artistic styles. We leverage the advanced text-image alignment capabilities of pre-trained image models to guide the animation process. Our approach introduces synthetic proxy images through two key innovations: (1) Dual-path score distillation: We employ a dual-path architecture to distill motion priors from both real and synthetic data, preserving static details from the original painting while learning dynamic characteristics from synthetic frames. (2) Hybrid latent fusion: We integrate hybrid features extracted from real paintings and synthetic proxy images via spherical linear interpolation in the latent space, ensuring smooth transitions and enhancing temporal consistency. Experimental evaluations confirm that our approach significantly improves semantic alignment with text prompts while faithfully preserving the unique characteristics and integrity of the original paintings. Crucially, by achieving enhanced dynamic effects without requiring any model training or learnable parameters, our framework enables plug-and-play integration with existing I2V methods, making it an ideal solution for animating real-world paintings. More animated examples can be found on our project website.
A Large-scale Interpretable Multi-modality Benchmark for Facial Image Forgery Localization
Dec 27, 2024Image forgery localization, which centers on identifying tampered pixels within an image, has seen significant advancements. Traditional approaches often model this challenge as a variant of image segmentation, treating the binary segmentation of forged areas as the end product. We argue that the basic binary forgery mask is inadequate for explaining model predictions. It doesn't clarify why the model pinpoints certain areas and treats all forged pixels the same, making it hard to spot the most fake-looking parts. In this study, we mitigate the aforementioned limitations by generating salient region-focused interpretation for the forgery images. To support this, we craft a Multi-Modal Tramper Tracing (MMTT) dataset, comprising facial images manipulated using deepfake techniques and paired with manual, interpretable textual annotations. To harvest high-quality annotation, annotators are instructed to meticulously observe the manipulated images and articulate the typical characteristics of the forgery regions. Subsequently, we collect a dataset of 128,303 image-text pairs. Leveraging the MMTT dataset, we develop ForgeryTalker, an architecture designed for concurrent forgery localization and interpretation. ForgeryTalker first trains a forgery prompter network to identify the pivotal clues within the explanatory text. Subsequently, the region prompter is incorporated into multimodal large language model for finetuning to achieve the dual goals of localization and interpretation. Extensive experiments conducted on the MMTT dataset verify the superior performance of our proposed model. The dataset, code as well as pretrained checkpoints will be made publicly available to facilitate further research and ensure the reproducibility of our results.
OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data
Dec 31, 2021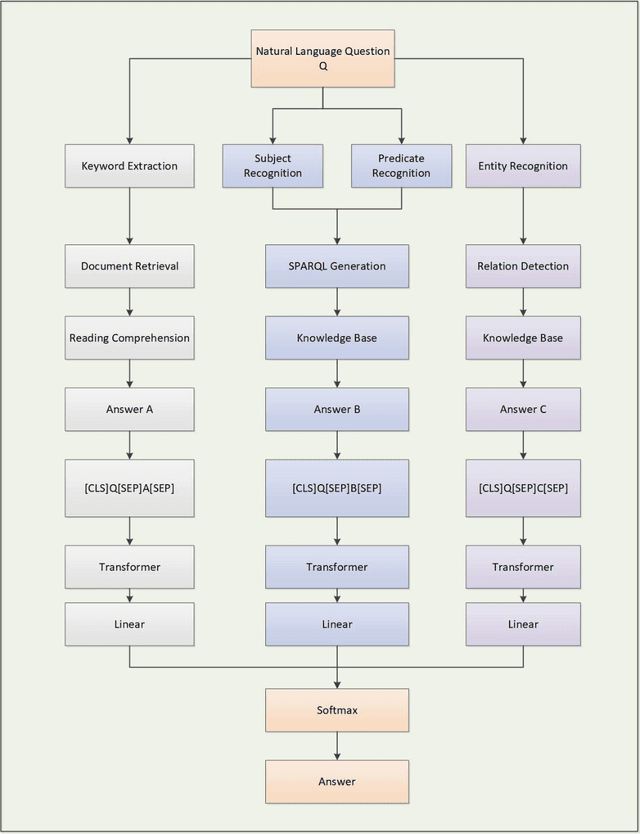
Search engines based on keyword retrieval can no longer adapt to the way of information acquisition in the era of intelligent Internet of Things due to the return of keyword related Internet pages. How to quickly, accurately and effectively obtain the information needed by users from massive Internet data has become one of the key issues urgently needed to be solved. We propose an intelligent question-answering system based on structured KB and unstructured data, called OpenQA, in which users can give query questions and the model can quickly give accurate answers back to users. We integrate KBQA structured question answering based on semantic parsing and deep representation learning, and two-stage unstructured question answering based on retrieval and neural machine reading comprehension into OpenQA, and return the final answer with the highest probability through the Transformer answer selection module in OpenQA. We carry out preliminary experiments on our constructed dataset, and the experimental results prove the effectiveness of the proposed intelligent question answering system. At the same time, the core technology of each module of OpenQA platform is still in the forefront of academic hot spots, and the theoretical essence and enrichment of OpenQA will be further explored based on these academic hot spots.