 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepGuard: Guarding Web Navigation via Single-Step Calibration
Jun 16, 2026Web navigation requires agents to follow natural language goals, interact with web pages, and produce accurate answers. While recent advances leverage vision-language models and reinforcement learning, existing methods still suffer from single-step fragility due to reward misalignment and error propagation. To tackle the reward entanglement, we design Dynamic Dual-Policy Optimization (DDPO), which dynamically switches between a navigation-first mode for exploration and an answer-first mode for question-answering to mitigate reward conflict. To calibrate the single-step error, we propose Confidence-Guided Adaptive Navigation Reflection (CANR), a mechanism that estimates per-step confidence, triggers reflection only when necessary, and uses contrastive rewards to encourage self-correction to calibrate the single-step inaccuracy. With the above as the main components, we finally develop our StepGuard, a new framework of Guarding Web Navigation via Single-Step Calibration. Experiments demonstrate that our approach significantly improves navigation and answer accuracy, setting new state-of-the-art performance on standard web navigation benchmarks.
CORE: Conflict-Oriented Reasoning for General Multimodal Manipulation Detection
Jun 02, 2026The rapid rise of generative AI has made multimodal fake news increasingly realistic and pervasive, posing severe threats to public trust and social stability. Existing detection methods rely heavily on manipulation-specific models and large-scale labeled data, resulting in poor generalization to emerging manipulation types. We observed that the essence of manipulated misinformation lies in its intrinsic conflicts, \textbf{i.e.,} semantic or physical inconsistencies either across modalities or with common world knowledge. Inspired by this observation, we propose \textbf{C}onflict-\textbf{O}riented \textbf{RE}asoning (\textbf{CORE}) framework, an effective paradigm that learns to endows multimodal large language models (MLLMs) with explicit conflict-capturing capability. To this end, CORE first constructs the Conflict Attribution Corpus (CAC) with fine-grained annotations of conflict factors and sources, providing essential data support for subsequent conflict perception training. By performing conflict-oriented representation enhancement and reasoning based on CAC, CORE achieves robust and generalizable conflict detection, effectively and rapidly adapting to unseen manipulation types with a few samples or in even zero-shot settings. Extensive experiments demonstrate that CORE surpasses state-of-the-art models. The dataset and code are publicly available at https://github.com/shen8424/CORE.
Process Over Outcome: Cultivating Forensic Reasoning for Generalizable Multimodal Manipulation Detection
Mar 02, 2026Recent advances in generative AI have significantly enhanced the realism of multimodal media manipulation, thereby posing substantial challenges to manipulation detection. Existing manipulation detection and grounding approaches predominantly focus on manipulation type classification under result-oriented supervision, which not only lacks interpretability but also tends to overfit superficial artifacts. In this paper, we argue that generalizable detection requires incorporating explicit forensic reasoning, rather than merely classifying a limited set of manipulation types, which fails to generalize to unseen manipulation patterns. To this end, we propose REFORM, a reasoning-driven framework that shifts learning from outcome fitting to process modeling. REFORM adopts a three-stage curriculum that first induces forensic rationales, then aligns reasoning with final judgments, and finally refines logical consistency via reinforcement learning. To support this paradigm, we introduce ROM, a large-scale dataset with rich reasoning annotations. Extensive experiments show that REFORM establishes new state-of-the-art performance with superior generalization, achieving 81.52% ACC on ROM, 76.65% ACC on DGM4, and 74.9 F1 on MMFakeBench.
Efficient Encoder-Free Fourier-based 3D Large Multimodal Model
Feb 26, 2026Large Multimodal Models (LMMs) that process 3D data typically rely on heavy, pre-trained visual encoders to extract geometric features. While recent 2D LMMs have begun to eliminate such encoders for efficiency and scalability, extending this paradigm to 3D remains challenging due to the unordered and large-scale nature of point clouds. This leaves a critical unanswered question: How can we design an LMM that tokenizes unordered 3D data effectively and efficiently without a cumbersome encoder? We propose Fase3D, the first efficient encoder-free Fourier-based 3D scene LMM. Fase3D tackles the challenges of scalability and permutation invariance with a novel tokenizer that combines point cloud serialization and the Fast Fourier Transform (FFT) to approximate self-attention. This design enables an effective and computationally minimal architecture, built upon three key innovations: First, we represent large scenes compactly via structured superpoints. Second, our space-filling curve serialization followed by an FFT enables efficient global context modeling and graph-based token merging. Lastly, our Fourier-augmented LoRA adapters inject global frequency-aware interactions into the LLMs at a negligible cost. Fase3D achieves performance comparable to encoder-based 3D LMMs while being significantly more efficient in computation and parameters. Project website: https://tev-fbk.github.io/Fase3D.
The Coherence Trap: When MLLM-Crafted Narratives Exploit Manipulated Visual Contexts
May 23, 2025The detection and grounding of multimedia manipulation has emerged as a critical challenge in combating AI-generated disinformation. While existing methods have made progress in recent years, we identify two fundamental limitations in current approaches: (1) Underestimation of MLLM-driven deception risk: prevailing techniques primarily address rule-based text manipulations, yet fail to account for sophisticated misinformation synthesized by multimodal large language models (MLLMs) that can dynamically generate semantically coherent, contextually plausible yet deceptive narratives conditioned on manipulated images; (2) Unrealistic misalignment artifacts: currently focused scenarios rely on artificially misaligned content that lacks semantic coherence, rendering them easily detectable. To address these gaps holistically, we propose a new adversarial pipeline that leverages MLLMs to generate high-risk disinformation. Our approach begins with constructing the MLLM-Driven Synthetic Multimodal (MDSM) dataset, where images are first altered using state-of-the-art editing techniques and then paired with MLLM-generated deceptive texts that maintain semantic consistency with the visual manipulations. Building upon this foundation, we present the Artifact-aware Manipulation Diagnosis via MLLM (AMD) framework featuring two key innovations: Artifact Pre-perception Encoding strategy and Manipulation-Oriented Reasoning, to tame MLLMs for the MDSM problem. Comprehensive experiments validate our framework's superior generalization capabilities as a unified architecture for detecting MLLM-powered multimodal deceptions.
A Large-scale Interpretable Multi-modality Benchmark for Facial Image Forgery Localization
Dec 27, 2024Image forgery localization, which centers on identifying tampered pixels within an image, has seen significant advancements. Traditional approaches often model this challenge as a variant of image segmentation, treating the binary segmentation of forged areas as the end product. We argue that the basic binary forgery mask is inadequate for explaining model predictions. It doesn't clarify why the model pinpoints certain areas and treats all forged pixels the same, making it hard to spot the most fake-looking parts. In this study, we mitigate the aforementioned limitations by generating salient region-focused interpretation for the forgery images. To support this, we craft a Multi-Modal Tramper Tracing (MMTT) dataset, comprising facial images manipulated using deepfake techniques and paired with manual, interpretable textual annotations. To harvest high-quality annotation, annotators are instructed to meticulously observe the manipulated images and articulate the typical characteristics of the forgery regions. Subsequently, we collect a dataset of 128,303 image-text pairs. Leveraging the MMTT dataset, we develop ForgeryTalker, an architecture designed for concurrent forgery localization and interpretation. ForgeryTalker first trains a forgery prompter network to identify the pivotal clues within the explanatory text. Subsequently, the region prompter is incorporated into multimodal large language model for finetuning to achieve the dual goals of localization and interpretation. Extensive experiments conducted on the MMTT dataset verify the superior performance of our proposed model. The dataset, code as well as pretrained checkpoints will be made publicly available to facilitate further research and ensure the reproducibility of our results.
PerLA: Perceptive 3D Language Assistant
Nov 29, 2024
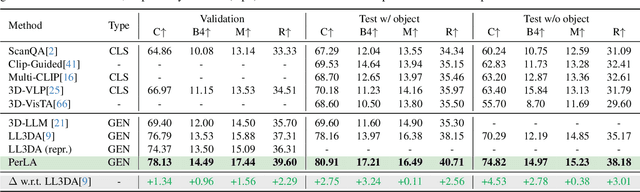
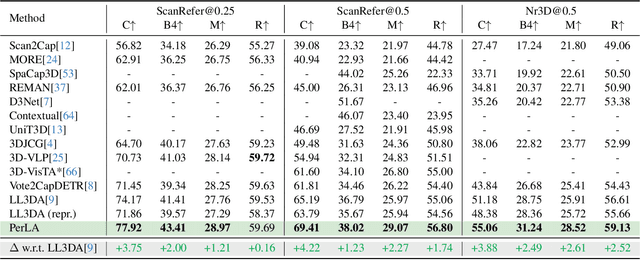

Enabling Large Language Models (LLMs) to understand the 3D physical world is an emerging yet challenging research direction. Current strategies for processing point clouds typically downsample the scene or divide it into smaller parts for separate analysis. However, both approaches risk losing key local details or global contextual information. In this paper, we introduce PerLA, a 3D language assistant designed to be more perceptive to both details and context, making visual representations more informative for the LLM. PerLA captures high-resolution (local) details in parallel from different point cloud areas and integrates them with (global) context obtained from a lower-resolution whole point cloud. We present a novel algorithm that preserves point cloud locality through the Hilbert curve and effectively aggregates local-to-global information via cross-attention and a graph neural network. Lastly, we introduce a novel loss for local representation consensus to promote training stability. PerLA outperforms state-of-the-art 3D language assistants, with gains of up to +1.34 CiDEr on ScanQA for question answering, and +4.22 on ScanRefer and +3.88 on Nr3D for dense captioning.\url{https://gfmei.github.io/PerLA/}
CaLa: Complementary Association Learning for Augmenting Composed Image Retrieval
May 29, 2024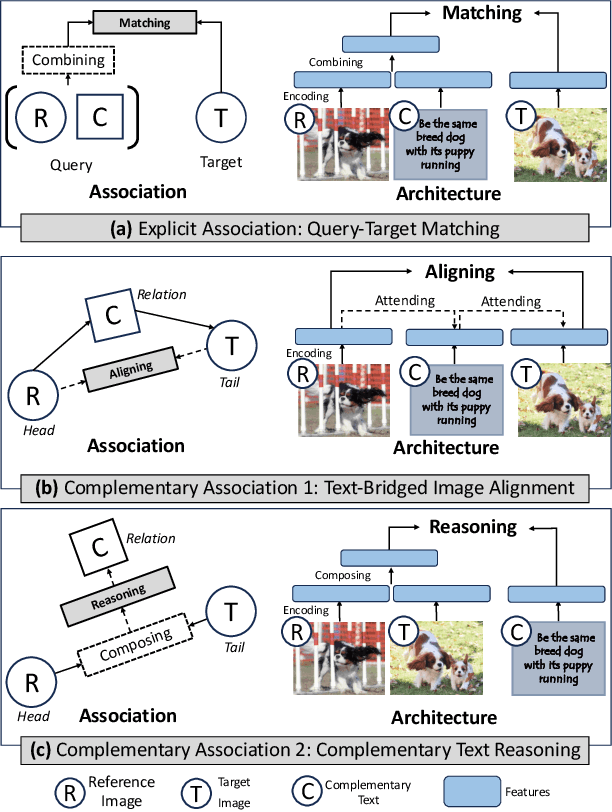
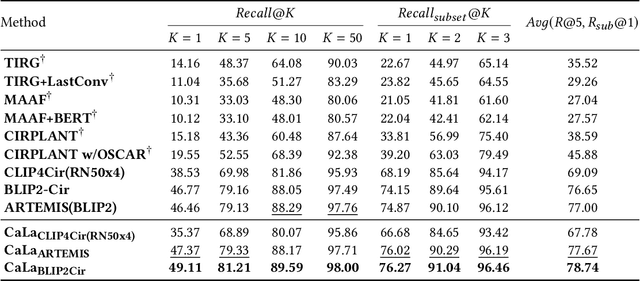
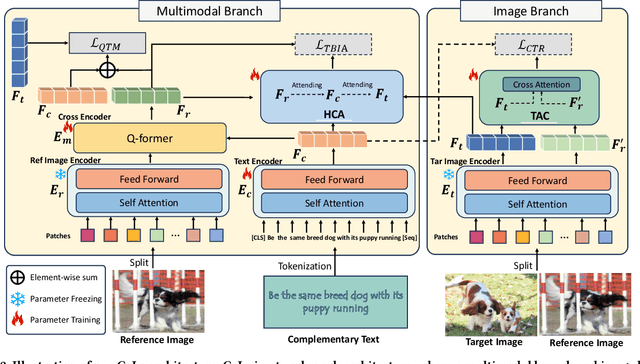
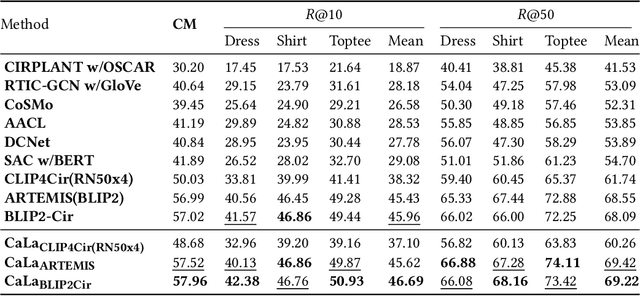
Composed Image Retrieval (CIR) involves searching for target images based on an image-text pair query. While current methods treat this as a query-target matching problem, we argue that CIR triplets contain additional associations beyond this primary relation. In our paper, we identify two new relations within triplets, treating each triplet as a graph node. Firstly, we introduce the concept of text-bridged image alignment, where the query text serves as a bridge between the query image and the target image. We propose a hinge-based cross-attention mechanism to incorporate this relation into network learning. Secondly, we explore complementary text reasoning, considering CIR as a form of cross-modal retrieval where two images compose to reason about complementary text. To integrate these perspectives effectively, we design a twin attention-based compositor. By combining these complementary associations with the explicit query pair-target image relation, we establish a comprehensive set of constraints for CIR. Our framework, CaLa (Complementary Association Learning for Augmenting Composed Image Retrieval), leverages these insights. We evaluate CaLa on CIRR and FashionIQ benchmarks with multiple backbones, demonstrating its superiority in composed image retrieval.
Beyond Known Clusters: Probe New Prototypes for Efficient Generalized Class Discovery
Apr 13, 2024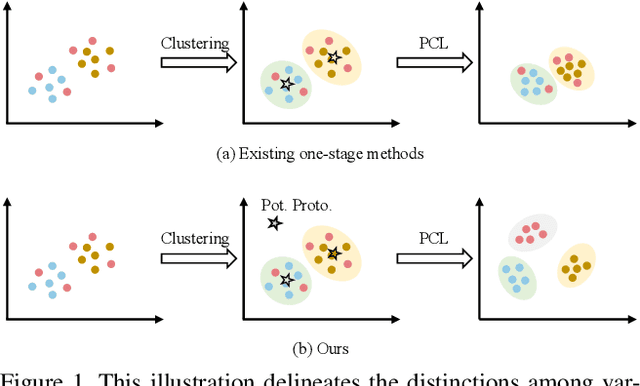
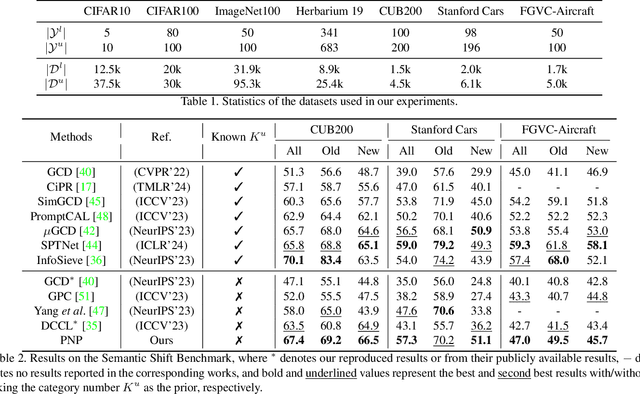
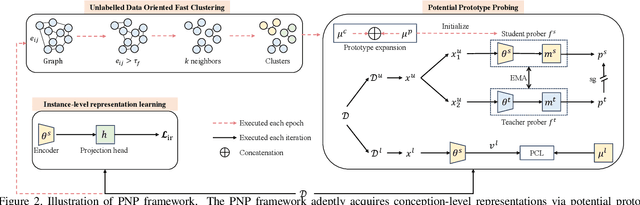
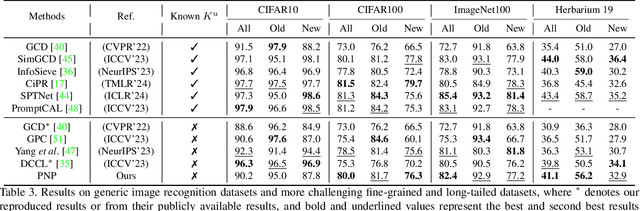
Generalized Class Discovery (GCD) aims to dynamically assign labels to unlabelled data partially based on knowledge learned from labelled data, where the unlabelled data may come from known or novel classes. The prevailing approach generally involves clustering across all data and learning conceptions by prototypical contrastive learning. However, existing methods largely hinge on the performance of clustering algorithms and are thus subject to their inherent limitations. Firstly, the estimated cluster number is often smaller than the ground truth, making the existing methods suffer from the lack of prototypes for comprehensive conception learning. To address this issue, we propose an adaptive probing mechanism that introduces learnable potential prototypes to expand cluster prototypes (centers). As there is no ground truth for the potential prototype, we develop a self-supervised prototype learning framework to optimize the potential prototype in an end-to-end fashion. Secondly, clustering is computationally intensive, and the conventional strategy of clustering both labelled and unlabelled instances exacerbates this issue. To counteract this inefficiency, we opt to cluster only the unlabelled instances and subsequently expand the cluster prototypes with our introduced potential prototypes to fast explore novel classes. Despite the simplicity of our proposed method, extensive empirical analysis on a wide range of datasets confirms that our method consistently delivers state-of-the-art results. Specifically, our method surpasses the nearest competitor by a significant margin of \textbf{9.7}$\%$ within the Stanford Cars dataset and \textbf{12$\times$} clustering efficiency within the Herbarium 19 dataset. We will make the code and checkpoints publicly available at \url{https://github.com/xjtuYW/PNP.git}.
Dual Relation Alignment for Composed Image Retrieval
Sep 05, 2023



Composed image retrieval, a task involving the search for a target image using a reference image and a complementary text as the query, has witnessed significant advancements owing to the progress made in cross-modal modeling. Unlike the general image-text retrieval problem with only one alignment relation, i.e., image-text, we argue for the existence of two types of relations in composed image retrieval. The explicit relation pertains to the reference image & complementary text-target image, which is commonly exploited by existing methods. Besides this intuitive relation, the observations during our practice have uncovered another implicit yet crucial relation, i.e., reference image & target image-complementary text, since we found that the complementary text can be inferred by studying the relation between the target image and the reference image. Regrettably, existing methods largely focus on leveraging the explicit relation to learn their networks, while overlooking the implicit relation. In response to this weakness, We propose a new framework for composed image retrieval, termed dual relation alignment, which integrates both explicit and implicit relations to fully exploit the correlations among the triplets. Specifically, we design a vision compositor to fuse reference image and target image at first, then the resulted representation will serve two roles: (1) counterpart for semantic alignment with the complementary text and (2) compensation for the complementary text to boost the explicit relation modeling, thereby implant the implicit relation into the alignment learning. Our method is evaluated on two popular datasets, CIRR and FashionIQ, through extensive experiments. The results confirm the effectiveness of our dual-relation learning in substantially enhancing composed image retrieval performance.