 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Search: Towards Referential Anchoring in Composed Image Retrieval
Apr 07, 2026Composed Image Retrieval (CIR) has demonstrated significant potential by enabling flexible multimodal queries that combine a reference image and modification text. However, CIR inherently prioritizes semantic matching, struggling to reliably retrieve a user-specified instance across contexts. In practice, emphasizing concrete instance fidelity over broad semantics is often more consequential. In this work, we propose Object-Anchored Composed Image Retrieval (OACIR), a novel fine-grained retrieval task that mandates strict instance-level consistency. To advance research on this task, we construct OACIRR (OACIR on Real-world images), the first large-scale, multi-domain benchmark comprising over 160K quadruples and four challenging candidate galleries enriched with hard-negative instance distractors. Each quadruple augments the compositional query with a bounding box that visually anchors the object in the reference image, providing a precise and flexible way to ensure instance preservation. To address the OACIR task, we propose AdaFocal, a framework featuring a Context-Aware Attention Modulator that adaptively intensifies attention within the specified instance region, dynamically balancing focus between the anchored instance and the broader compositional context. Extensive experiments demonstrate that AdaFocal substantially outperforms existing compositional retrieval models, particularly in maintaining instance-level fidelity, thereby establishing a robust baseline for this challenging task while opening new directions for more flexible, instance-aware retrieval systems.
DetailFusion: A Dual-branch Framework with Detail Enhancement for Composed Image Retrieval
May 23, 2025Composed Image Retrieval (CIR) aims to retrieve target images from a gallery based on a reference image and modification text as a combined query. Recent approaches focus on balancing global information from two modalities and encode the query into a unified feature for retrieval. However, due to insufficient attention to fine-grained details, these coarse fusion methods often struggle with handling subtle visual alterations or intricate textual instructions. In this work, we propose DetailFusion, a novel dual-branch framework that effectively coordinates information across global and detailed granularities, thereby enabling detail-enhanced CIR. Our approach leverages atomic detail variation priors derived from an image editing dataset, supplemented by a detail-oriented optimization strategy to develop a Detail-oriented Inference Branch. Furthermore, we design an Adaptive Feature Compositor that dynamically fuses global and detailed features based on fine-grained information of each unique multimodal query. Extensive experiments and ablation analyses not only demonstrate that our method achieves state-of-the-art performance on both CIRR and FashionIQ datasets but also validate the effectiveness and cross-domain adaptability of detail enhancement for CIR.
DOGE: Towards Versatile Visual Document Grounding and Referring
Nov 26, 2024



In recent years, Multimodal Large Language Models (MLLMs) have increasingly emphasized grounding and referring capabilities to achieve detailed understanding and flexible user interaction. However, in the realm of visual document understanding, these capabilities lag behind due to the scarcity of fine-grained datasets and comprehensive benchmarks. To fill this gap, we propose the DOcument Grounding and Eferring data engine (DOGE-Engine), which produces two types of high-quality fine-grained document data: multi-granular parsing data for enhancing fundamental text localization and recognition capabilities; and instruction-tuning data to activate MLLM's grounding and referring capabilities during dialogue and reasoning. Additionally, using our engine, we construct DOGE-Bench, which encompasses 7 grounding and referring tasks across 3 document types (chart, poster, PDF document), providing comprehensive evaluations for fine-grained document understanding. Furthermore, leveraging the data generated by our engine, we develop a strong baseline model, DOGE. This pioneering MLLM is capable of accurately referring and grounding texts at multiple granularities within document images. Our code, data, and model will be open-sourced for community development.
Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
Jun 06, 2023
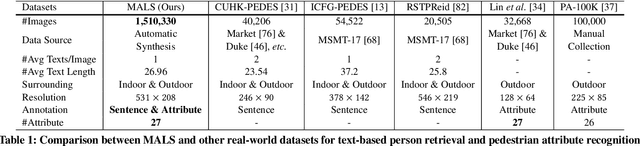
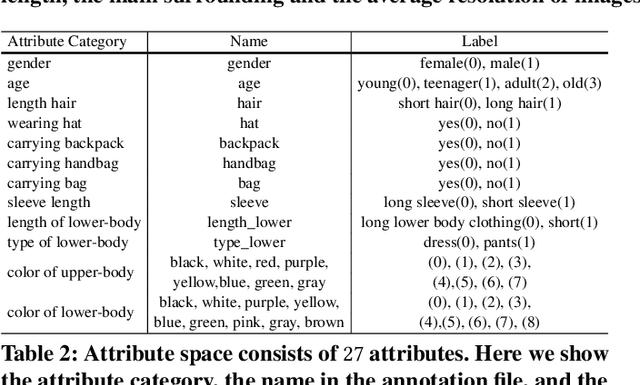

In this paper, we introduce a large Multi-Attribute and Language Search dataset for text-based person retrieval, called MALS, and explore the feasibility of performing pre-training on both attribute recognition and image-text matching tasks in one stone. In particular, MALS contains 1,510,330 image-text pairs, which is about 37.5 times larger than prevailing CUHK-PEDES, and all images are annotated with 27 attributes. Considering the privacy concerns and annotation costs, we leverage the off-the-shelf diffusion models to generate the dataset. To verify the feasibility of learning from the generated data, we develop a new joint Attribute Prompt Learning and Text Matching Learning (APTM) framework, considering the shared knowledge between attribute and text. As the name implies, APTM contains an attribute prompt learning stream and a text matching learning stream. (1) The attribute prompt learning leverages the attribute prompts for image-attribute alignment, which enhances the text matching learning. (2) The text matching learning facilitates the representation learning on fine-grained details, and in turn, boosts the attribute prompt learning. Extensive experiments validate the effectiveness of the pre-training on MALS, achieving state-of-the-art retrieval performance via APTM on three challenging real-world benchmarks. In particular, APTM achieves a consistent improvement of +6.60%, +7.39%, and +15.90% Recall@1 accuracy on CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets by a clear margin, respectively.