 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOGE: Towards Versatile Visual Document Grounding and Referring
Nov 26, 2024



In recent years, Multimodal Large Language Models (MLLMs) have increasingly emphasized grounding and referring capabilities to achieve detailed understanding and flexible user interaction. However, in the realm of visual document understanding, these capabilities lag behind due to the scarcity of fine-grained datasets and comprehensive benchmarks. To fill this gap, we propose the DOcument Grounding and Eferring data engine (DOGE-Engine), which produces two types of high-quality fine-grained document data: multi-granular parsing data for enhancing fundamental text localization and recognition capabilities; and instruction-tuning data to activate MLLM's grounding and referring capabilities during dialogue and reasoning. Additionally, using our engine, we construct DOGE-Bench, which encompasses 7 grounding and referring tasks across 3 document types (chart, poster, PDF document), providing comprehensive evaluations for fine-grained document understanding. Furthermore, leveraging the data generated by our engine, we develop a strong baseline model, DOGE. This pioneering MLLM is capable of accurately referring and grounding texts at multiple granularities within document images. Our code, data, and model will be open-sourced for community development.
Beyond Walking: A Large-Scale Image-Text Benchmark for Text-based Person Anomaly Search
Nov 26, 2024



Text-based person search aims to retrieve specific individuals across camera networks using natural language descriptions. However, current benchmarks often exhibit biases towards common actions like walking or standing, neglecting the critical need for identifying abnormal behaviors in real-world scenarios. To meet such demands, we propose a new task, text-based person anomaly search, locating pedestrians engaged in both routine or anomalous activities via text. To enable the training and evaluation of this new task, we construct a large-scale image-text Pedestrian Anomaly Behavior (PAB) benchmark, featuring a broad spectrum of actions, e.g., running, performing, playing soccer, and the corresponding anomalies, e.g., lying, being hit, and falling of the same identity. The training set of PAB comprises 1,013,605 synthesized image-text pairs of both normalities and anomalies, while the test set includes 1,978 real-world image-text pairs. To validate the potential of PAB, we introduce a cross-modal pose-aware framework, which integrates human pose patterns with identity-based hard negative pair sampling. Extensive experiments on the proposed benchmark show that synthetic training data facilitates the fine-grained behavior retrieval in the real-world test set, while the proposed pose-aware method further improves the recall@1 by 2.88%. We will release the dataset, code, and checkpoints to facilitate further research and ensure the reproducibility of our results.
A Real-World Quadrupedal Locomotion Benchmark for Offline Reinforcement Learning
Sep 13, 2023Online reinforcement learning (RL) methods are often data-inefficient or unreliable, making them difficult to train on real robotic hardware, especially quadruped robots. Learning robotic tasks from pre-collected data is a promising direction. Meanwhile, agile and stable legged robotic locomotion remains an open question in their general form. Offline reinforcement learning (ORL) has the potential to make breakthroughs in this challenging field, but its current bottleneck lies in the lack of diverse datasets for challenging realistic tasks. To facilitate the development of ORL, we benchmarked 11 ORL algorithms in the realistic quadrupedal locomotion dataset. Such dataset is collected by the classic model predictive control (MPC) method, rather than the model-free online RL method commonly used by previous benchmarks. Extensive experimental results show that the best-performing ORL algorithms can achieve competitive performance compared with the model-free RL, and even surpass it in some tasks. However, there is still a gap between the learning-based methods and MPC, especially in terms of stability and rapid adaptation. Our proposed benchmark will serve as a development platform for testing and evaluating the performance of ORL algorithms in real-world legged locomotion tasks.
Towards Unified Text-based Person Retrieval: A Large-scale Multi-Attribute and Language Search Benchmark
Jun 06, 2023
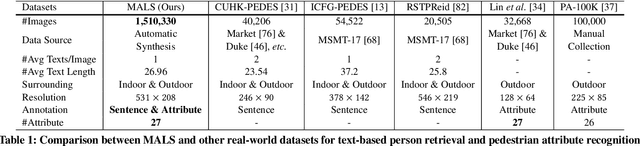
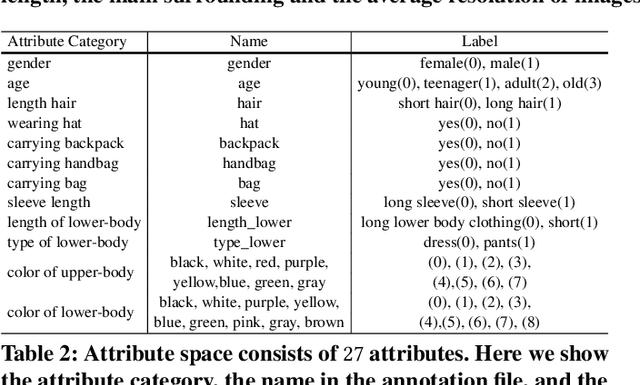

In this paper, we introduce a large Multi-Attribute and Language Search dataset for text-based person retrieval, called MALS, and explore the feasibility of performing pre-training on both attribute recognition and image-text matching tasks in one stone. In particular, MALS contains 1,510,330 image-text pairs, which is about 37.5 times larger than prevailing CUHK-PEDES, and all images are annotated with 27 attributes. Considering the privacy concerns and annotation costs, we leverage the off-the-shelf diffusion models to generate the dataset. To verify the feasibility of learning from the generated data, we develop a new joint Attribute Prompt Learning and Text Matching Learning (APTM) framework, considering the shared knowledge between attribute and text. As the name implies, APTM contains an attribute prompt learning stream and a text matching learning stream. (1) The attribute prompt learning leverages the attribute prompts for image-attribute alignment, which enhances the text matching learning. (2) The text matching learning facilitates the representation learning on fine-grained details, and in turn, boosts the attribute prompt learning. Extensive experiments validate the effectiveness of the pre-training on MALS, achieving state-of-the-art retrieval performance via APTM on three challenging real-world benchmarks. In particular, APTM achieves a consistent improvement of +6.60%, +7.39%, and +15.90% Recall@1 accuracy on CUHK-PEDES, ICFG-PEDES, and RSTPReid datasets by a clear margin, respectively.
Imitation and Adaptation Based on Consistency: A Quadruped Robot Imitates Animals from Videos Using Deep Reinforcement Learning
Mar 02, 2022

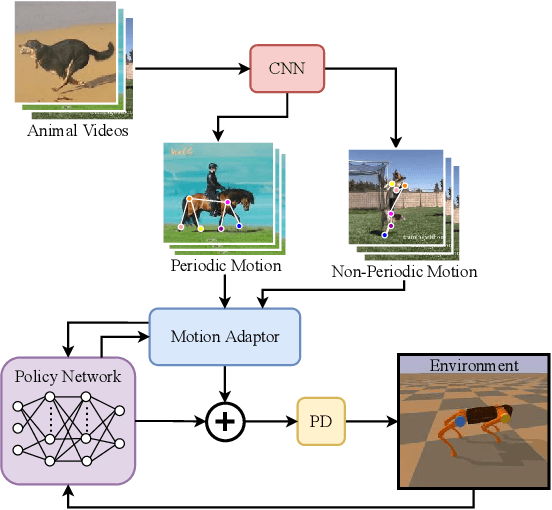

The essence of quadrupeds' movements is the movement of the center of gravity, which has a pattern in the action of quadrupeds. However, the gait motion planning of the quadruped robot is time-consuming. Animals in nature can provide a large amount of gait information for robots to learn and imitate. Common methods learn animal posture with a motion capture system or numerous motion data points. In this paper, we propose a video imitation adaptation network (VIAN) that can imitate the action of animals and adapt it to the robot from a few seconds of video. The deep learning model extracts key points during animal motion from videos. The VIAN eliminates noise and extracts key information of motion with a motion adaptor, and then applies the extracted movements function as the motion pattern into deep reinforcement learning (DRL). To ensure similarity between the learning result and the animal motion in the video, we introduce rewards that are based on the consistency of the motion. DRL explores and learns to maintain balance from movement patterns from videos, imitates the action of animals, and eventually, allows the model to learn the gait or skills from short motion videos of different animals and to transfer the motion pattern to the real robot.
A Transferable Legged Mobile Manipulation Framework Based on Disturbance Predictive Control
Mar 02, 2022
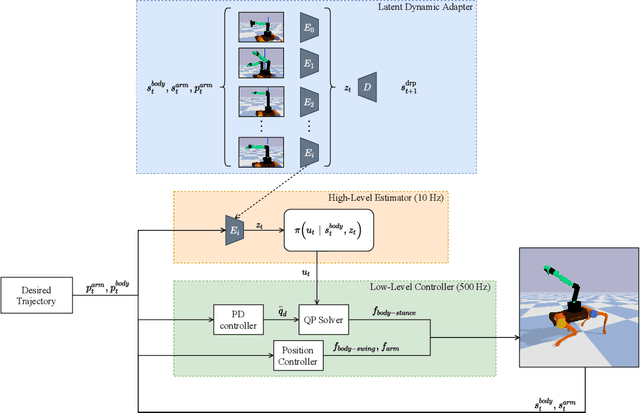

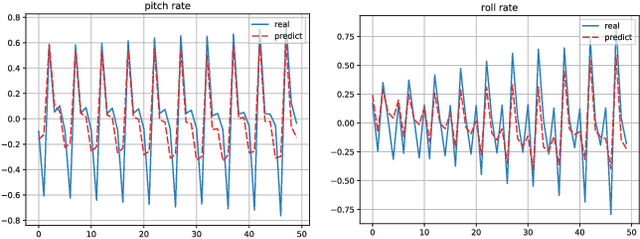
Due to their ability to adapt to different terrains, quadruped robots have drawn much attention in the research field of robot learning. Legged mobile manipulation, where a quadruped robot is equipped with a robotic arm, can greatly enhance the performance of the robot in diverse manipulation tasks. Several prior works have investigated legged mobile manipulation from the viewpoint of control theory. However, modeling a unified structure for various robotic arms and quadruped robots is a challenging task. In this paper, we propose a unified framework disturbance predictive control where a reinforcement learning scheme with a latent dynamic adapter is embedded into our proposed low-level controller. Our method can adapt well to various types of robotic arms with a few random motion samples and the experimental results demonstrate the effectiveness of our method.