 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCR-Bench: A Comprehensive Evaluation Framework for Video Chain-of-Thought Reasoning
Apr 10, 2025The advancement of Chain-of-Thought (CoT) reasoning has significantly enhanced the capabilities of large language models (LLMs) and large vision-language models (LVLMs). However, a rigorous evaluation framework for video CoT reasoning remains absent. Current video benchmarks fail to adequately assess the reasoning process and expose whether failures stem from deficiencies in perception or reasoning capabilities. Therefore, we introduce VCR-Bench, a novel benchmark designed to comprehensively evaluate LVLMs' Video Chain-of-Thought Reasoning capabilities. VCR-Bench comprises 859 videos spanning a variety of video content and durations, along with 1,034 high-quality question-answer pairs. Each pair is manually annotated with a stepwise CoT rationale, where every step is tagged to indicate its association with the perception or reasoning capabilities. Furthermore, we design seven distinct task dimensions and propose the CoT score to assess the entire CoT process based on the stepwise tagged CoT rationals. Extensive experiments on VCR-Bench highlight substantial limitations in current LVLMs. Even the top-performing model, o1, only achieves a 62.8% CoT score and an 56.7% accuracy, while most models score below 40%. Experiments show most models score lower on perception than reasoning steps, revealing LVLMs' key bottleneck in temporal-spatial information processing for complex video reasoning. A robust positive correlation between the CoT score and accuracy confirms the validity of our evaluation framework and underscores the critical role of CoT reasoning in solving complex video reasoning tasks. We hope VCR-Bench to serve as a standardized evaluation framework and expose the actual drawbacks in complex video reasoning task.
Mono2Stereo: A Benchmark and Empirical Study for Stereo Conversion
Mar 28, 2025With the rapid proliferation of 3D devices and the shortage of 3D content, stereo conversion is attracting increasing attention. Recent works introduce pretrained Diffusion Models (DMs) into this task. However, due to the scarcity of large-scale training data and comprehensive benchmarks, the optimal methodologies for employing DMs in stereo conversion and the accurate evaluation of stereo effects remain largely unexplored. In this work, we introduce the Mono2Stereo dataset, providing high-quality training data and benchmark to support in-depth exploration of stereo conversion. With this dataset, we conduct an empirical study that yields two primary findings. 1) The differences between the left and right views are subtle, yet existing metrics consider overall pixels, failing to concentrate on regions critical to stereo effects. 2) Mainstream methods adopt either one-stage left-to-right generation or warp-and-inpaint pipeline, facing challenges of degraded stereo effect and image distortion respectively. Based on these findings, we introduce a new evaluation metric, Stereo Intersection-over-Union, which prioritizes disparity and achieves a high correlation with human judgments on stereo effect. Moreover, we propose a strong baseline model, harmonizing the stereo effect and image quality simultaneously, and notably surpassing current mainstream methods. Our code and data will be open-sourced to promote further research in stereo conversion. Our models are available at mono2stereo-bench.github.io.
DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation
Mar 27, 2025Human image animation has recently gained significant attention due to advancements in generative models. However, existing methods still face two major challenges: (1) architectural limitations, most models rely on U-Net, which underperforms compared to the MM-DiT; and (2) the neglect of textual information, which can enhance controllability. In this work, we introduce DynamiCtrl, a novel framework that not only explores different pose-guided control structures in MM-DiT, but also reemphasizes the crucial role of text in this task. Specifically, we employ a Shared VAE encoder for both reference images and driving pose videos, eliminating the need for an additional pose encoder and simplifying the overall framework. To incorporate pose features into the full attention blocks, we propose Pose-adaptive Layer Norm (PadaLN), which utilizes adaptive layer normalization to encode sparse pose features. The encoded features are directly added to the visual input, preserving the spatiotemporal consistency of the backbone while effectively introducing pose control into MM-DiT. Furthermore, within the full attention mechanism, we align textual and visual features to enhance controllability. By leveraging text, we not only enable fine-grained control over the generated content, but also, for the first time, achieve simultaneous control over both background and motion. Experimental results verify the superiority of DynamiCtrl on benchmark datasets, demonstrating its strong identity preservation, heterogeneous character driving, background controllability, and high-quality synthesis. The project page is available at https://gulucaptain.github.io/DynamiCtrl/.
VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models
Dec 27, 2024Zero-shot customized video generation has gained significant attention due to its substantial application potential. Existing methods rely on additional models to extract and inject reference subject features, assuming that the Video Diffusion Model (VDM) alone is insufficient for zero-shot customized video generation. However, these methods often struggle to maintain consistent subject appearance due to suboptimal feature extraction and injection techniques. In this paper, we reveal that VDM inherently possesses the force to extract and inject subject features. Departing from previous heuristic approaches, we introduce a novel framework that leverages VDM's inherent force to enable high-quality zero-shot customized video generation. Specifically, for feature extraction, we directly input reference images into VDM and use its intrinsic feature extraction process, which not only provides fine-grained features but also significantly aligns with VDM's pre-trained knowledge. For feature injection, we devise an innovative bidirectional interaction between subject features and generated content through spatial self-attention within VDM, ensuring that VDM has better subject fidelity while maintaining the diversity of the generated video.Experiments on both customized human and object video generation validate the effectiveness of our framework.
DOGE: Towards Versatile Visual Document Grounding and Referring
Nov 26, 2024



In recent years, Multimodal Large Language Models (MLLMs) have increasingly emphasized grounding and referring capabilities to achieve detailed understanding and flexible user interaction. However, in the realm of visual document understanding, these capabilities lag behind due to the scarcity of fine-grained datasets and comprehensive benchmarks. To fill this gap, we propose the DOcument Grounding and Eferring data engine (DOGE-Engine), which produces two types of high-quality fine-grained document data: multi-granular parsing data for enhancing fundamental text localization and recognition capabilities; and instruction-tuning data to activate MLLM's grounding and referring capabilities during dialogue and reasoning. Additionally, using our engine, we construct DOGE-Bench, which encompasses 7 grounding and referring tasks across 3 document types (chart, poster, PDF document), providing comprehensive evaluations for fine-grained document understanding. Furthermore, leveraging the data generated by our engine, we develop a strong baseline model, DOGE. This pioneering MLLM is capable of accurately referring and grounding texts at multiple granularities within document images. Our code, data, and model will be open-sourced for community development.
mR$^2$AG: Multimodal Retrieval-Reflection-Augmented Generation for Knowledge-Based VQA
Nov 22, 2024



Advanced Multimodal Large Language Models (MLLMs) struggle with recent Knowledge-based VQA tasks, such as INFOSEEK and Encyclopedic-VQA, due to their limited and frozen knowledge scope, often leading to ambiguous and inaccurate responses. Thus, multimodal Retrieval-Augmented Generation (mRAG) is naturally introduced to provide MLLMs with comprehensive and up-to-date knowledge, effectively expanding the knowledge scope. However, current mRAG methods have inherent drawbacks, including: 1) Performing retrieval even when external knowledge is not needed. 2) Lacking of identification of evidence that supports the query. 3) Increasing model complexity due to additional information filtering modules or rules. To address these shortcomings, we propose a novel generalized framework called \textbf{m}ultimodal \textbf{R}etrieval-\textbf{R}eflection-\textbf{A}ugmented \textbf{G}eneration (mR$^2$AG), which achieves adaptive retrieval and useful information localization to enable answers through two easy-to-implement reflection operations, preventing high model complexity. In mR$^2$AG, Retrieval-Reflection is designed to distinguish different user queries and avoids redundant retrieval calls, and Relevance-Reflection is introduced to guide the MLLM in locating beneficial evidence of the retrieved content and generating answers accordingly. In addition, mR$^2$AG can be integrated into any well-trained MLLM with efficient fine-tuning on the proposed mR$^2$AG Instruction-Tuning dataset (mR$^2$AG-IT). mR$^2$AG significantly outperforms state-of-the-art MLLMs (e.g., GPT-4v/o) and RAG-based MLLMs on INFOSEEK and Encyclopedic-VQA, while maintaining the exceptional capabilities of base MLLMs across a wide range of Visual-dependent tasks.
Taming Rectified Flow for Inversion and Editing
Nov 07, 2024



Rectified-flow-based diffusion transformers, such as FLUX and OpenSora, have demonstrated exceptional performance in the field of image and video generation. Despite their robust generative capabilities, these models often suffer from inaccurate inversion, which could further limit their effectiveness in downstream tasks such as image and video editing. To address this issue, we propose RF-Solver, a novel training-free sampler that enhances inversion precision by reducing errors in the process of solving rectified flow ODEs. Specifically, we derive the exact formulation of the rectified flow ODE and perform a high-order Taylor expansion to estimate its nonlinear components, significantly decreasing the approximation error at each timestep. Building upon RF-Solver, we further design RF-Edit, which comprises specialized sub-modules for image and video editing. By sharing self-attention layer features during the editing process, RF-Edit effectively preserves the structural information of the source image or video while achieving high-quality editing results. Our approach is compatible with any pre-trained rectified-flow-based models for image and video tasks, requiring no additional training or optimization. Extensive experiments on text-to-image generation, image & video inversion, and image & video editing demonstrate the robust performance and adaptability of our methods. Code is available at https://github.com/wangjiangshan0725/RF-Solver-Edit.
E.T. Bench: Towards Open-Ended Event-Level Video-Language Understanding
Sep 26, 2024



Recent advances in Video Large Language Models (Video-LLMs) have demonstrated their great potential in general-purpose video understanding. To verify the significance of these models, a number of benchmarks have been proposed to diagnose their capabilities in different scenarios. However, existing benchmarks merely evaluate models through video-level question-answering, lacking fine-grained event-level assessment and task diversity. To fill this gap, we introduce E.T. Bench (Event-Level & Time-Sensitive Video Understanding Benchmark), a large-scale and high-quality benchmark for open-ended event-level video understanding. Categorized within a 3-level task taxonomy, E.T. Bench encompasses 7.3K samples under 12 tasks with 7K videos (251.4h total length) under 8 domains, providing comprehensive evaluations. We extensively evaluated 8 Image-LLMs and 12 Video-LLMs on our benchmark, and the results reveal that state-of-the-art models for coarse-level (video-level) understanding struggle to solve our fine-grained tasks, e.g., grounding event-of-interests within videos, largely due to the short video context length, improper time representations, and lack of multi-event training data. Focusing on these issues, we further propose a strong baseline model, E.T. Chat, together with an instruction-tuning dataset E.T. Instruct 164K tailored for fine-grained event-level understanding. Our simple but effective solution demonstrates superior performance in multiple scenarios.
CustomCrafter: Customized Video Generation with Preserving Motion and Concept Composition Abilities
Aug 23, 2024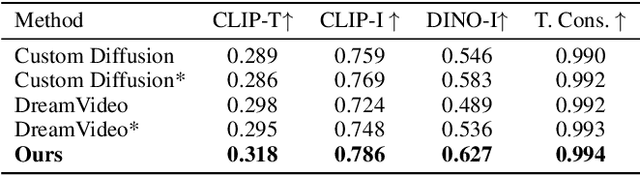
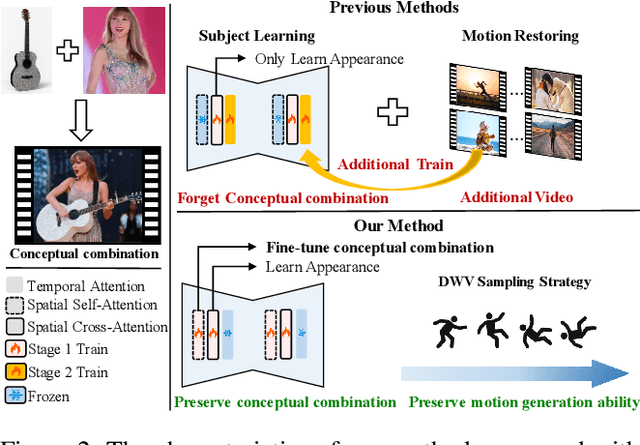


Customized video generation aims to generate high-quality videos guided by text prompts and subject's reference images. However, since it is only trained on static images, the fine-tuning process of subject learning disrupts abilities of video diffusion models (VDMs) to combine concepts and generate motions. To restore these abilities, some methods use additional video similar to the prompt to fine-tune or guide the model. This requires frequent changes of guiding videos and even re-tuning of the model when generating different motions, which is very inconvenient for users. In this paper, we propose CustomCrafter, a novel framework that preserves the model's motion generation and conceptual combination abilities without additional video and fine-tuning to recovery. For preserving conceptual combination ability, we design a plug-and-play module to update few parameters in VDMs, enhancing the model's ability to capture the appearance details and the ability of concept combinations for new subjects. For motion generation, we observed that VDMs tend to restore the motion of video in the early stage of denoising, while focusing on the recovery of subject details in the later stage. Therefore, we propose Dynamic Weighted Video Sampling Strategy. Using the pluggability of our subject learning modules, we reduce the impact of this module on motion generation in the early stage of denoising, preserving the ability to generate motion of VDMs. In the later stage of denoising, we restore this module to repair the appearance details of the specified subject, thereby ensuring the fidelity of the subject's appearance. Experimental results show that our method has a significant improvement compared to previous methods.
SynopGround: A Large-Scale Dataset for Multi-Paragraph Video Grounding from TV Dramas and Synopses
Aug 07, 2024
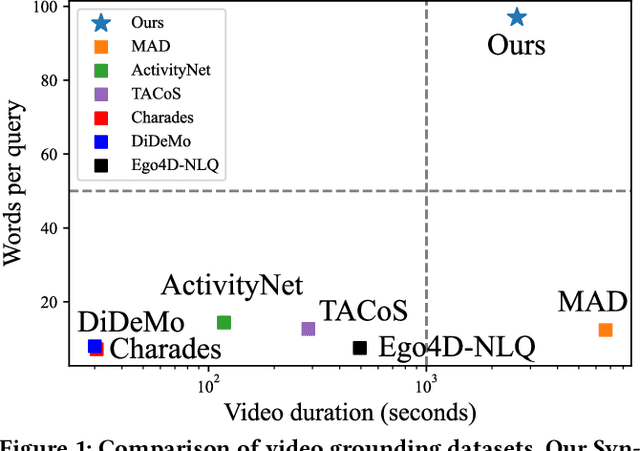
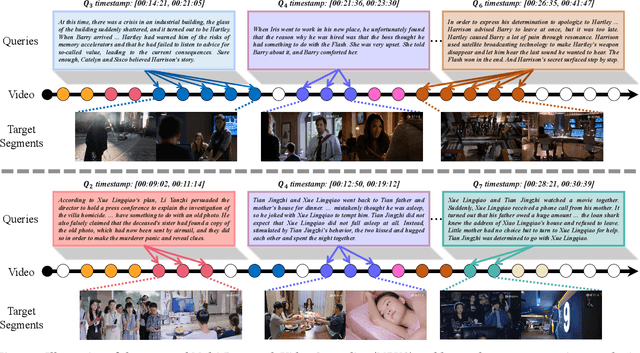
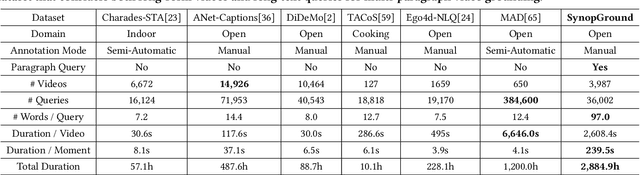
Video grounding is a fundamental problem in multimodal content understanding, aiming to localize specific natural language queries in an untrimmed video. However, current video grounding datasets merely focus on simple events and are either limited to shorter videos or brief sentences, which hinders the model from evolving toward stronger multimodal understanding capabilities. To address these limitations, we present a large-scale video grounding dataset named SynopGround, in which more than 2800 hours of videos are sourced from popular TV dramas and are paired with accurately localized human-written synopses. Each paragraph in the synopsis serves as a language query and is manually annotated with precise temporal boundaries in the long video. These paragraph queries are tightly correlated to each other and contain a wealth of abstract expressions summarizing video storylines and specific descriptions portraying event details, which enables the model to learn multimodal perception on more intricate concepts over longer context dependencies. Based on the dataset, we further introduce a more complex setting of video grounding dubbed Multi-Paragraph Video Grounding (MPVG), which takes as input multiple paragraphs and a long video for grounding each paragraph query to its temporal interval. In addition, we propose a novel Local-Global Multimodal Reasoner (LGMR) to explicitly model the local-global structures of long-term multimodal inputs for MPVG. Our method provides an effective baseline solution to the multi-paragraph video grounding problem. Extensive experiments verify the proposed model's effectiveness as well as its superiority in long-term multi-paragraph video grounding over prior state-of-the-arts. Dataset and code are publicly available. Project page: https://synopground.github.io/.