 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-Agent: Test-Time Multimodal Reasoning for Training-Free Language-Guided Segmentation
May 13, 2026Language-guided segmentation transcends the scope limitations of traditional semantic segmentation, enabling models to segment arbitrary target regions based on natural language instructions. Existing approaches typically adopt a two-stage framework: employing Multimodal Large Language Models (MLLMs) to interpret instructions and generate visual prompts, followed by foundational segmentation models (e.g., SAM) to produce masks. However, due to the limited spatial grounding capabilities of off-the-shelf MLLMs, these methods often rely on extensive training on large-scale datasets to achieve satisfactory accuracy. While recent advances have introduced reasoning mechanisms to improve performance, they predominantly operate within the textual domain, performing chain-of-thought reasoning solely based on abstract text representations without direct visual feedback. In this paper, we propose Seg-Agent, a completely training-free framework that pioneers Explicit Multimodal Chain-of-Reasoning. Unlike prior text-only reasoning, our approach constructs an interactive visual reasoning loop comprising three stages: generation, selection, and refinement. Specifically, we leverage Set-of-Mark (SoM) visual prompting to render candidate regions directly onto the image, allowing the MLLM to ``see'' and iteratively reason about spatial relationships in the visual domain rather than just the textual one. This explicit multimodal interaction enables Seg-Agent to achieve performance comparable to state-of-the-art training-based methods without any parameter updates. Furthermore, to comprehensively evaluate generalization across diverse scenarios, we introduce Various-LangSeg, a novel benchmark covering explicit semantic, generic object, and reasoning-guided segmentation tasks. Extensive experiments demonstrate the effectiveness and robustness of our method.
Beyond Text Prompts: Visual-to-Visual Generation as A Unified Paradigm
May 12, 2026Humans often specify and create through visual artifacts: typography sheets, sketches, reference images, and annotated scenes. Yet modern visual generators still ask users to serialize this intent into text, a bottleneck that compresses signals like spatial structure, exact appearance, and glyph shape. We propose \textbf{\emph{visual-to-visual} (V2V)} generation, in which the user conditions a generative model with a visual specification page rather than a text prompt. The page is not an edit target, but a visual document that specifies the desired output. We introduce \textbf{V2V-Zero}, a training-free framework that exposes this interface in existing vision-language model (VLM) conditioned generators by replacing text-only conditioning with final-layer hidden states extracted from visual pages, exploiting the fact that the frozen VLM already maps both text and images into the generator's conditioning space. On GenEval, V2V-Zero reaches 0.85 with a frozen Qwen-Image backbone, closely matching its optimized text-to-image performance without fine-tuning. To evaluate the broader V2V space, we introduce \textbf{Simple-V2V Bench}, spanning seven visual-conditioning tasks and seven models, including GPT Image 2, Nano Banana 2, Seedream 5.0 Lite, open-weight baselines, and a video extension. V2V-Zero scores 32.7/100, outperforming evaluated open-weight image baselines and revealing a clear capability hierarchy: attribute binding is strong, content generation is unreliable, and structural control remains hard even for commercial systems. A HunyuanVideo-1.5 extension scores 20.2/100, showing the interface transfers beyond images. Mechanistic analysis shows the default reasoning path is primarily visually routed, with 95.0\% of conditioning-token attention mass on visual-page hidden states.
CutClaw: Agentic Hours-Long Video Editing via Music Synchronization
Mar 31, 2026Editing the video content with audio alignment forms a digital human-made art in current social media. However, the time-consuming and repetitive nature of manual video editing has long been a challenge for filmmakers and professional content creators alike. In this paper, we introduce CutClaw, an autonomous multi-agent framework designed to edit hours-long raw footage into meaningful short videos that leverages the capabilities of multiple Multimodal Language Models~(MLLMs) as an agent system. It produces videos with synchronized music, followed by instructions, and a visually appealing appearance. In detail, our approach begins by employing a hierarchical multimodal decomposition that captures both fine-grained details and global structures across visual and audio footage. Then, to ensure narrative consistency, a Playwriter Agent orchestrates the whole storytelling flow and structures the long-term narrative, anchoring visual scenes to musical shifts. Finally, to construct a short edited video, Editor and Reviewer Agents collaboratively optimize the final cut via selecting fine-grained visual content based on rigorous aesthetic and semantic criteria. We conduct detailed experiments to demonstrate that CutClaw significantly outperforms state-of-the-art baselines in generating high-quality, rhythm-aligned videos. The code is available at: https://github.com/GVCLab/CutClaw.
LightCtrl: Training-free Controllable Video Relighting
Mar 28, 2026Recent diffusion models have achieved remarkable success in image relighting, and this success has quickly been extended to video relighting. However, existing methods offer limited explicit control over illumination in the relighted output. We present LightCtrl, the first controllable video relighting method that enables explicit control of video illumination through a user-supplied light trajectory in a training-free manner. Our approach combines pre-trained diffusion models: an image relighting model processes each frame individually, followed by a video diffusion prior to enhance temporal consistency. To achieve explicit control over dynamically varying lighting, we introduce two key components. First, a Light Map Injection module samples light trajectory-specific noise and injects it into the latent representation of the source video, improving illumination coherence with the conditional light trajectory. Second, a Geometry-Aware Relighting module dynamically combines RGB and normal map latents in the frequency domain to suppress the influence of the original lighting, further enhancing adherence to the input light trajectory. Experiments show that LightCtrl produces high-quality videos with diverse illumination changes that closely follow the specified light trajectory, demonstrating improved controllability over baseline methods. Code is available at: https://github.com/GVCLab/LightCtrl.
MLLM-4D: Towards Visual-based Spatial-Temporal Intelligence
Feb 28, 2026Humans are born with vision-based 4D spatial-temporal intelligence, which enables us to perceive and reason about the evolution of 3D space over time from purely visual inputs. Despite its importance, this capability remains a significant bottleneck for current multimodal large language models (MLLMs). To tackle this challenge, we introduce MLLM-4D, a comprehensive framework designed to bridge the gaps in training data curation and model post-training for spatiotemporal understanding and reasoning. On the data front, we develop a cost-efficient data curation pipeline that repurposes existing stereo video datasets into high-quality 4D spatiotemporal instructional data. This results in the MLLM4D-2M and MLLM4D-R1-30k datasets for Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT), alongside MLLM4D-Bench for comprehensive evaluation. Regarding model training, our post-training strategy establishes a foundational 4D understanding via SFT and further catalyzes 4D reasoning capabilities by employing Group Relative Policy Optimization (GRPO) with specialized Spatiotemporal Chain of Thought (ST-CoT) prompting and Spatiotemporal reward functions (ST-reward) without involving the modification of architecture. Extensive experiments demonstrate that MLLM-4D achieves state-of-the-art spatial-temporal understanding and reasoning capabilities from purely 2D RGB inputs. Project page: https://github.com/GVCLab/MLLM-4D.
EasyOmnimatte: Taming Pretrained Inpainting Diffusion Models for End-to-End Video Layered Decomposition
Dec 26, 2025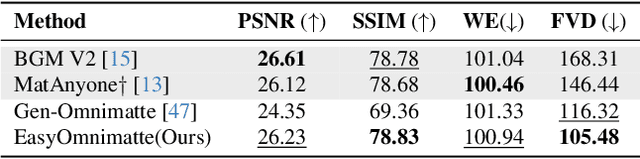
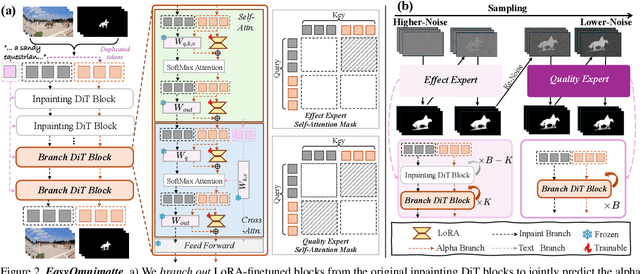
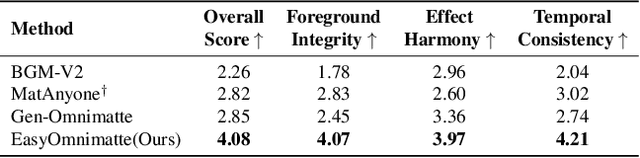
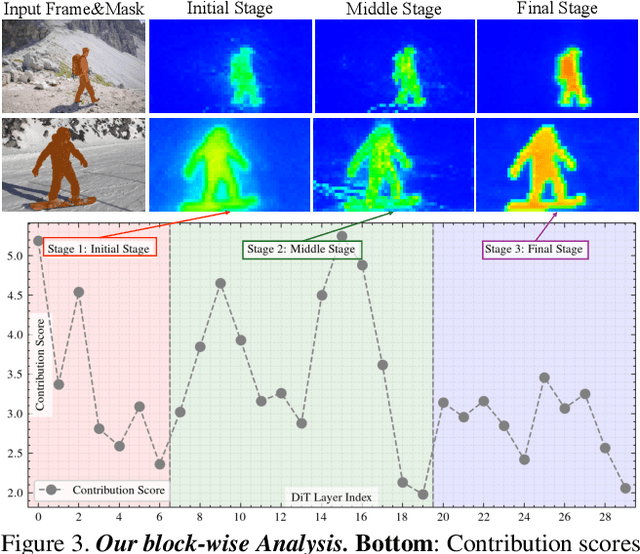
Existing video omnimatte methods typically rely on slow, multi-stage, or inference-time optimization pipelines that fail to fully exploit powerful generative priors, producing suboptimal decompositions. Our key insight is that, if a video inpainting model can be finetuned to remove the foreground-associated effects, then it must be inherently capable of perceiving these effects, and hence can also be finetuned for the complementary task: foreground layer decomposition with associated effects. However, although naïvely finetuning the inpainting model with LoRA applied to all blocks can produce high-quality alpha mattes, it fails to capture associated effects. Our systematic analysis reveals this arises because effect-related cues are primarily encoded in specific DiT blocks and become suppressed when LoRA is applied across all blocks. To address this, we introduce EasyOmnimatte, the first unified, end-to-end video omnimatte method. Concretely, we finetune a pretrained video inpainting diffusion model to learn dual complementary experts while keeping its original weights intact: an Effect Expert, where LoRA is applied only to effect-sensitive DiT blocks to capture the coarse structure of the foreground and associated effects, and a fully LoRA-finetuned Quality Expert learns to refine the alpha matte. During sampling, Effect Expert is used for denoising at early, high-noise steps, while Quality Expert takes over at later, low-noise steps. This design eliminates the need for two full diffusion passes, significantly reducing computational cost without compromising output quality. Ablation studies validate the effectiveness of this Dual-Expert strategy. Experiments demonstrate that EasyOmnimatte sets a new state-of-the-art for video omnimatte and enables various downstream tasks, significantly outperforming baselines in both quality and efficiency.
PersonaLive! Expressive Portrait Image Animation for Live Streaming
Dec 12, 2025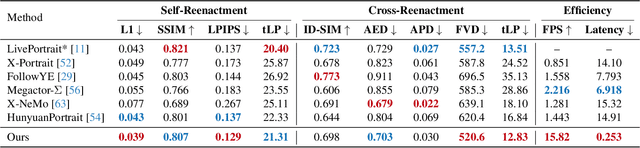
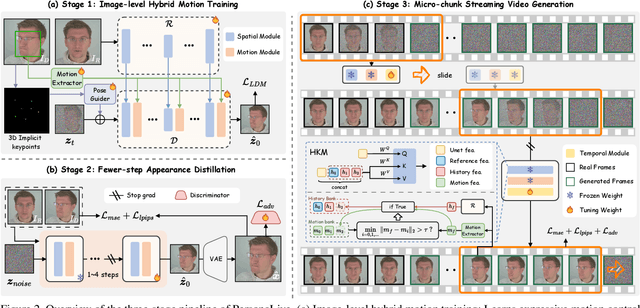

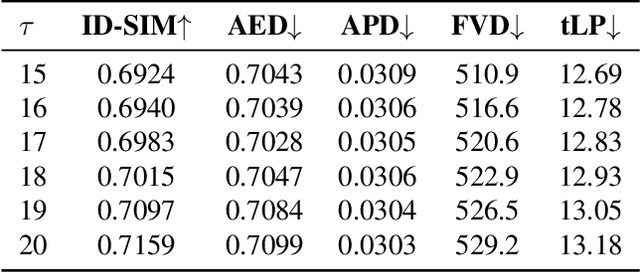
Current diffusion-based portrait animation models predominantly focus on enhancing visual quality and expression realism, while overlooking generation latency and real-time performance, which restricts their application range in the live streaming scenario. We propose PersonaLive, a novel diffusion-based framework towards streaming real-time portrait animation with multi-stage training recipes. Specifically, we first adopt hybrid implicit signals, namely implicit facial representations and 3D implicit keypoints, to achieve expressive image-level motion control. Then, a fewer-step appearance distillation strategy is proposed to eliminate appearance redundancy in the denoising process, greatly improving inference efficiency. Finally, we introduce an autoregressive micro-chunk streaming generation paradigm equipped with a sliding training strategy and a historical keyframe mechanism to enable low-latency and stable long-term video generation. Extensive experiments demonstrate that PersonaLive achieves state-of-the-art performance with up to 7-22x speedup over prior diffusion-based portrait animation models.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025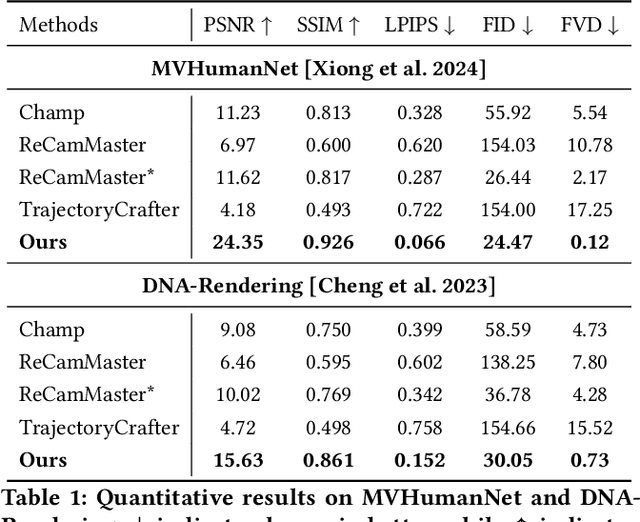

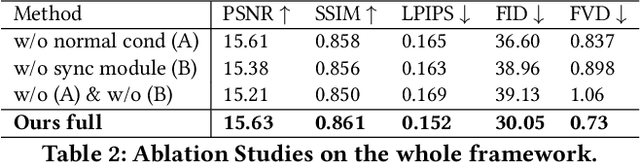
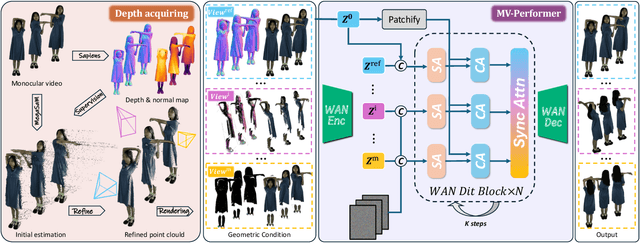
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
May 29, 2025Video Anomaly Understanding (VAU) is essential for applications such as smart cities, security surveillance, and disaster alert systems, yet remains challenging due to its demand for fine-grained spatio-temporal perception and robust reasoning under ambiguity. Despite advances in anomaly detection, existing methods often lack interpretability and struggle to capture the causal and contextual aspects of abnormal events. This limitation is further compounded by the absence of comprehensive benchmarks for evaluating reasoning ability in anomaly scenarios. To address both challenges, we introduce VAU-R1, a data-efficient framework built upon Multimodal Large Language Models (MLLMs), which enhances anomaly reasoning through Reinforcement Fine-Tuning (RFT). Besides, we propose VAU-Bench, the first Chain-of-Thought benchmark tailored for video anomaly reasoning, featuring multiple-choice QA, detailed rationales, temporal annotations, and descriptive captions. Empirical results show that VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence across diverse contexts. Together, our method and benchmark establish a strong foundation for interpretable and reasoning-aware video anomaly understanding. Our code is available at https://github.com/GVCLab/VAU-R1.
Sci-Fi: Symmetric Constraint for Frame Inbetweening
May 27, 2025



Frame inbetweening aims to synthesize intermediate video sequences conditioned on the given start and end frames. Current state-of-the-art methods mainly extend large-scale pre-trained Image-to-Video Diffusion models (I2V-DMs) by incorporating end-frame constraints via directly fine-tuning or omitting training. We identify a critical limitation in their design: Their injections of the end-frame constraint usually utilize the same mechanism that originally imposed the start-frame (single image) constraint. However, since the original I2V-DMs are adequately trained for the start-frame condition in advance, naively introducing the end-frame constraint by the same mechanism with much less (even zero) specialized training probably can't make the end frame have a strong enough impact on the intermediate content like the start frame. This asymmetric control strength of the two frames over the intermediate content likely leads to inconsistent motion or appearance collapse in generated frames. To efficiently achieve symmetric constraints of start and end frames, we propose a novel framework, termed Sci-Fi, which applies a stronger injection for the constraint of a smaller training scale. Specifically, it deals with the start-frame constraint as before, while introducing the end-frame constraint by an improved mechanism. The new mechanism is based on a well-designed lightweight module, named EF-Net, which encodes only the end frame and expands it into temporally adaptive frame-wise features injected into the I2V-DM. This makes the end-frame constraint as strong as the start-frame constraint, enabling our Sci-Fi to produce more harmonious transitions in various scenarios. Extensive experiments prove the superiority of our Sci-Fi compared with other baselines.