 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Audio Control of Video Diffusion Transformers
Dec 21, 2025Recent advancements in video generation have seen a shift towards unified, transformer-based foundation models that can handle multiple conditional inputs in-context. However, these models have primarily focused on modalities like text, images, and depth maps, while strictly time-synchronous signals like audio have been underexplored. This paper introduces In-Context Audio Control of video diffusion transformers (ICAC), a framework that investigates the integration of audio signals for speech-driven video generation within a unified full-attention architecture, akin to FullDiT. We systematically explore three distinct mechanisms for injecting audio conditions: standard cross-attention, 2D self-attention, and unified 3D self-attention. Our findings reveal that while 3D attention offers the highest potential for capturing spatio-temporal audio-visual correlations, it presents significant training challenges. To overcome this, we propose a Masked 3D Attention mechanism that constrains the attention pattern to enforce temporal alignment, enabling stable training and superior performance. Our experiments demonstrate that this approach achieves strong lip synchronization and video quality, conditioned on an audio stream and reference images.
Learning to Integrate Diffusion ODEs by Averaging the Derivatives
May 20, 2025To accelerate diffusion model inference, numerical solvers perform poorly at extremely small steps, while distillation techniques often introduce complexity and instability. This work presents an intermediate strategy, balancing performance and cost, by learning ODE integration using loss functions derived from the derivative-integral relationship, inspired by Monte Carlo integration and Picard iteration. From a geometric perspective, the losses operate by gradually extending the tangent to the secant, thus are named as secant losses. The secant losses can rapidly convert (via fine-tuning or distillation) a pretrained diffusion model into its secant version. In our experiments, the secant version of EDM achieves a $10$-step FID of $2.14$ on CIFAR-10, while the secant version of SiT-XL/2 attains a $4$-step FID of $2.27$ and an $8$-step FID of $1.96$ on ImageNet-$256\times256$. Code will be available.
DiTCtrl: Exploring Attention Control in Multi-Modal Diffusion Transformer for Tuning-Free Multi-Prompt Longer Video Generation
Dec 24, 2024



Sora-like video generation models have achieved remarkable progress with a Multi-Modal Diffusion Transformer MM-DiT architecture. However, the current video generation models predominantly focus on single-prompt, struggling to generate coherent scenes with multiple sequential prompts that better reflect real-world dynamic scenarios. While some pioneering works have explored multi-prompt video generation, they face significant challenges including strict training data requirements, weak prompt following, and unnatural transitions. To address these problems, we propose DiTCtrl, a training-free multi-prompt video generation method under MM-DiT architectures for the first time. Our key idea is to take the multi-prompt video generation task as temporal video editing with smooth transitions. To achieve this goal, we first analyze MM-DiT's attention mechanism, finding that the 3D full attention behaves similarly to that of the cross/self-attention blocks in the UNet-like diffusion models, enabling mask-guided precise semantic control across different prompts with attention sharing for multi-prompt video generation. Based on our careful design, the video generated by DiTCtrl achieves smooth transitions and consistent object motion given multiple sequential prompts without additional training. Besides, we also present MPVBench, a new benchmark specially designed for multi-prompt video generation to evaluate the performance of multi-prompt generation. Extensive experiments demonstrate that our method achieves state-of-the-art performance without additional training.
Customize Your Visual Autoregressive Recipe with Set Autoregressive Modeling
Oct 14, 2024



We introduce a new paradigm for AutoRegressive (AR) image generation, termed Set AutoRegressive Modeling (SAR). SAR generalizes the conventional AR to the next-set setting, i.e., splitting the sequence into arbitrary sets containing multiple tokens, rather than outputting each token in a fixed raster order. To accommodate SAR, we develop a straightforward architecture termed Fully Masked Transformer. We reveal that existing AR variants correspond to specific design choices of sequence order and output intervals within the SAR framework, with AR and Masked AR (MAR) as two extreme instances. Notably, SAR facilitates a seamless transition from AR to MAR, where intermediate states allow for training a causal model that benefits from both few-step inference and KV cache acceleration, thus leveraging the advantages of both AR and MAR. On the ImageNet benchmark, we carefully explore the properties of SAR by analyzing the impact of sequence order and output intervals on performance, as well as the generalization ability regarding inference order and steps. We further validate the potential of SAR by training a 900M text-to-image model capable of synthesizing photo-realistic images with any resolution. We hope our work may inspire more exploration and application of AR-based modeling across diverse modalities.
Training Matting Models without Alpha Labels
Aug 20, 2024



The labelling difficulty has been a longstanding problem in deep image matting. To escape from fine labels, this work explores using rough annotations such as trimaps coarsely indicating the foreground/background as supervision. We present that the cooperation between learned semantics from indicated known regions and proper assumed matting rules can help infer alpha values at transition areas. Inspired by the nonlocal principle in traditional image matting, we build a directional distance consistency loss (DDC loss) at each pixel neighborhood to constrain the alpha values conditioned on the input image. DDC loss forces the distance of similar pairs on the alpha matte and on its corresponding image to be consistent. In this way, the alpha values can be propagated from learned known regions to unknown transition areas. With only images and trimaps, a matting model can be trained under the supervision of a known loss and the proposed DDC loss. Experiments on AM-2K and P3M-10K dataset show that our paradigm achieves comparable performance with the fine-label-supervised baseline, while sometimes offers even more satisfying results than human-labelled ground truth. Code is available at \url{https://github.com/poppuppy/alpha-free-matting}.
FADE: A Task-Agnostic Upsampling Operator for Encoder-Decoder Architectures
Jul 18, 2024The goal of this work is to develop a task-agnostic feature upsampling operator for dense prediction where the operator is required to facilitate not only region-sensitive tasks like semantic segmentation but also detail-sensitive tasks such as image matting. Prior upsampling operators often can work well in either type of the tasks, but not both. We argue that task-agnostic upsampling should dynamically trade off between semantic preservation and detail delineation, instead of having a bias between the two properties. In this paper, we present FADE, a novel, plug-and-play, lightweight, and task-agnostic upsampling operator by fusing the assets of decoder and encoder features at three levels: i) considering both the encoder and decoder feature in upsampling kernel generation; ii) controlling the per-point contribution of the encoder/decoder feature in upsampling kernels with an efficient semi-shift convolutional operator; and iii) enabling the selective pass of encoder features with a decoder-dependent gating mechanism for compensating details. To improve the practicality of FADE, we additionally study parameter- and memory-efficient implementations of semi-shift convolution. We analyze the upsampling behavior of FADE on toy data and show through large-scale experiments that FADE is task-agnostic with consistent performance improvement on a number of dense prediction tasks with little extra cost. For the first time, we demonstrate robust feature upsampling on both region- and detail-sensitive tasks successfully. Code is made available at: https://github.com/poppinace/fade
SCAPE: A Simple and Strong Category-Agnostic Pose Estimator
Jul 18, 2024Category-Agnostic Pose Estimation (CAPE) aims to localize keypoints on an object of any category given few exemplars in an in-context manner. Prior arts involve sophisticated designs, e.g., sundry modules for similarity calculation and a two-stage framework, or takes in extra heatmap generation and supervision. We notice that CAPE is essentially a task about feature matching, which can be solved within the attention process. Therefore we first streamline the architecture into a simple baseline consisting of several pure self-attention layers and an MLP regression head -- this simplification means that one only needs to consider the attention quality to boost the performance of CAPE. Towards an effective attention process for CAPE, we further introduce two key modules: i) a global keypoint feature perceptor to inject global semantic information into support keypoints, and ii) a keypoint attention refiner to enhance inter-node correlation between keypoints. They jointly form a Simple and strong Category-Agnostic Pose Estimator (SCAPE). Experimental results show that SCAPE outperforms prior arts by 2.2 and 1.3 PCK under 1-shot and 5-shot settings with faster inference speed and lighter model capacity, excelling in both accuracy and efficiency. Code and models are available at https://github.com/tiny-smart/SCAPE
Learning to Upsample by Learning to Sample
Aug 29, 2023



We present DySample, an ultra-lightweight and effective dynamic upsampler. While impressive performance gains have been witnessed from recent kernel-based dynamic upsamplers such as CARAFE, FADE, and SAPA, they introduce much workload, mostly due to the time-consuming dynamic convolution and the additional sub-network used to generate dynamic kernels. Further, the need for high-res feature guidance of FADE and SAPA somehow limits their application scenarios. To address these concerns, we bypass dynamic convolution and formulate upsampling from the perspective of point sampling, which is more resource-efficient and can be easily implemented with the standard built-in function in PyTorch. We first showcase a naive design, and then demonstrate how to strengthen its upsampling behavior step by step towards our new upsampler, DySample. Compared with former kernel-based dynamic upsamplers, DySample requires no customized CUDA package and has much fewer parameters, FLOPs, GPU memory, and latency. Besides the light-weight characteristics, DySample outperforms other upsamplers across five dense prediction tasks, including semantic segmentation, object detection, instance segmentation, panoptic segmentation, and monocular depth estimation. Code is available at https://github.com/tiny-smart/dysample.
On Point Affiliation in Feature Upsampling
Jul 17, 2023We introduce the notion of point affiliation into feature upsampling. By abstracting a feature map into non-overlapped semantic clusters formed by points of identical semantic meaning, feature upsampling can be viewed as point affiliation -- designating a semantic cluster for each upsampled point. In the framework of kernel-based dynamic upsampling, we show that an upsampled point can resort to its low-res decoder neighbors and high-res encoder point to reason the affiliation, conditioned on the mutual similarity between them. We therefore present a generic formulation for generating similarity-aware upsampling kernels and prove that such kernels encourage not only semantic smoothness but also boundary sharpness. This formulation constitutes a novel, lightweight, and universal upsampling solution, Similarity-Aware Point Affiliation (SAPA). We show its working mechanism via our preliminary designs with window-shape kernel. After probing the limitations of the designs on object detection, we reveal additional insights for upsampling, leading to SAPA with the dynamic kernel shape. Extensive experiments demonstrate that SAPA outperforms prior upsamplers and invites consistent performance improvements on a number of dense prediction tasks, including semantic segmentation, object detection, instance segmentation, panoptic segmentation, image matting, and depth estimation. Code is made available at: https://github.com/tiny-smart/sapa
Box-DETR: Understanding and Boxing Conditional Spatial Queries
Jul 17, 2023


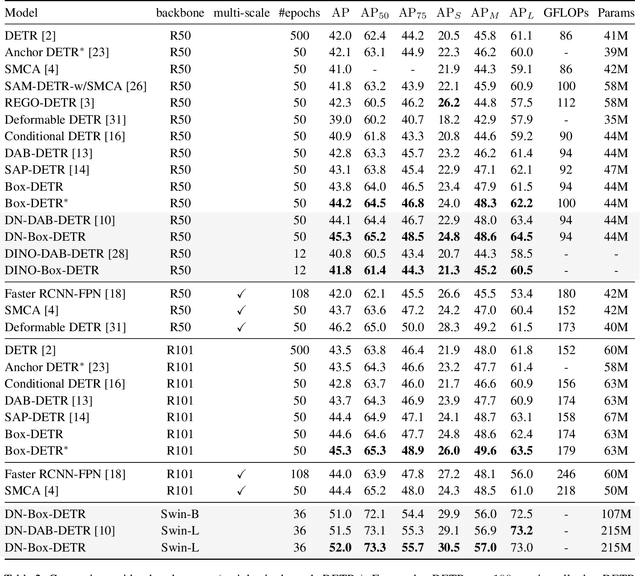
Conditional spatial queries are recently introduced into DEtection TRansformer (DETR) to accelerate convergence. In DAB-DETR, such queries are modulated by the so-called conditional linear projection at each decoder stage, aiming to search for positions of interest such as the four extremities of the box. Each decoder stage progressively updates the box by predicting the anchor box offsets, while in cross-attention only the box center is informed as the reference point. The use of only box center, however, leaves the width and height of the previous box unknown to the current stage, which hinders accurate prediction of offsets. We argue that the explicit use of the entire box information in cross-attention matters. In this work, we propose Box Agent to condense the box into head-specific agent points. By replacing the box center with the agent point as the reference point in each head, the conditional cross-attention can search for positions from a more reasonable starting point by considering the full scope of the previous box, rather than always from the previous box center. This significantly reduces the burden of the conditional linear projection. Experimental results show that the box agent leads to not only faster convergence but also improved detection performance, e.g., our single-scale model achieves $44.2$ AP with ResNet-50 based on DAB-DETR. Our Box Agent requires minor modifications to the code and has negligible computational workload. Code is available at https://github.com/tiny-smart/box-detr.