 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-Aware CoT: Achieving High-Fidelity Visual Consistency in Unified Models
Dec 22, 2025Recently, the introduction of Chain-of-Thought (CoT) has largely improved the generation ability of unified models. However, it is observed that the current thinking process during generation mainly focuses on the text consistency with the text prompt, ignoring the \textbf{visual context consistency} with the visual reference images during the multi-modal generation, e.g., multi-reference generation. The lack of such consistency results in the failure in maintaining key visual features (like human ID, object attribute, style). To this end, we integrate the visual context consistency into the reasoning of unified models, explicitly motivating the model to sustain such consistency by 1) Adaptive Visual Planning: generating structured visual check list to figure out the visual element of needed consistency keeping, and 2) Iterative Visual Correction: performing self-reflection with the guidance of check lists and refining the generated result in an iterative manner. To achieve this, we use supervised finetuning to teach the model how to plan the visual checking, conduct self-reflection and self-refinement, and use flow-GRPO to further enhance the visual consistency through a customized visual checking reward. The experiments show that our method outperforms both zero-shot unified models and those with text CoTs in multi-modal generation, demonstrating higher visual context consistency.
FullDiT2: Efficient In-Context Conditioning for Video Diffusion Transformers
Jun 05, 2025


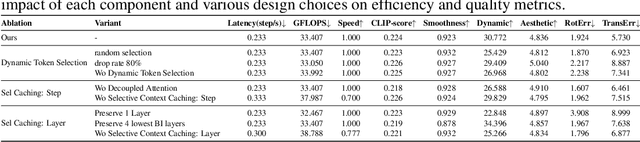
Fine-grained and efficient controllability on video diffusion transformers has raised increasing desires for the applicability. Recently, In-context Conditioning emerged as a powerful paradigm for unified conditional video generation, which enables diverse controls by concatenating varying context conditioning signals with noisy video latents into a long unified token sequence and jointly processing them via full-attention, e.g., FullDiT. Despite their effectiveness, these methods face quadratic computation overhead as task complexity increases, hindering practical deployment. In this paper, we study the efficiency bottleneck neglected in original in-context conditioning video generation framework. We begin with systematic analysis to identify two key sources of the computation inefficiencies: the inherent redundancy within context condition tokens and the computational redundancy in context-latent interactions throughout the diffusion process. Based on these insights, we propose FullDiT2, an efficient in-context conditioning framework for general controllability in both video generation and editing tasks, which innovates from two key perspectives. Firstly, to address the token redundancy, FullDiT2 leverages a dynamic token selection mechanism to adaptively identify important context tokens, reducing the sequence length for unified full-attention. Additionally, a selective context caching mechanism is devised to minimize redundant interactions between condition tokens and video latents. Extensive experiments on six diverse conditional video editing and generation tasks demonstrate that FullDiT2 achieves significant computation reduction and 2-3 times speedup in averaged time cost per diffusion step, with minimal degradation or even higher performance in video generation quality. The project page is at \href{https://fulldit2.github.io/}{https://fulldit2.github.io/}.
UNIC: Unified In-Context Video Editing
Jun 04, 2025

Recent advances in text-to-video generation have sparked interest in generative video editing tasks. Previous methods often rely on task-specific architectures (e.g., additional adapter modules) or dedicated customizations (e.g., DDIM inversion), which limit the integration of versatile editing conditions and the unification of various editing tasks. In this paper, we introduce UNified In-Context Video Editing (UNIC), a simple yet effective framework that unifies diverse video editing tasks within a single model in an in-context manner. To achieve this unification, we represent the inputs of various video editing tasks as three types of tokens: the source video tokens, the noisy video latent, and the multi-modal conditioning tokens that vary according to the specific editing task. Based on this formulation, our key insight is to integrate these three types into a single consecutive token sequence and jointly model them using the native attention operations of DiT, thereby eliminating the need for task-specific adapter designs. Nevertheless, direct task unification under this framework is challenging, leading to severe token collisions and task confusion due to the varying video lengths and diverse condition modalities across tasks. To address these, we introduce task-aware RoPE to facilitate consistent temporal positional encoding, and condition bias that enables the model to clearly differentiate different editing tasks. This allows our approach to adaptively perform different video editing tasks by referring the source video and varying condition tokens "in context", and support flexible task composition. To validate our method, we construct a unified video editing benchmark containing six representative video editing tasks. Results demonstrate that our unified approach achieves superior performance on each task and exhibits emergent task composition abilities.
StyleMaster: Stylize Your Video with Artistic Generation and Translation
Dec 10, 2024



Style control has been popular in video generation models. Existing methods often generate videos far from the given style, cause content leakage, and struggle to transfer one video to the desired style. Our first observation is that the style extraction stage matters, whereas existing methods emphasize global style but ignore local textures. In order to bring texture features while preventing content leakage, we filter content-related patches while retaining style ones based on prompt-patch similarity; for global style extraction, we generate a paired style dataset through model illusion to facilitate contrastive learning, which greatly enhances the absolute style consistency. Moreover, to fill in the image-to-video gap, we train a lightweight motion adapter on still videos, which implicitly enhances stylization extent, and enables our image-trained model to be seamlessly applied to videos. Benefited from these efforts, our approach, StyleMaster, not only achieves significant improvement in both style resemblance and temporal coherence, but also can easily generalize to video style transfer with a gray tile ControlNet. Extensive experiments and visualizations demonstrate that StyleMaster significantly outperforms competitors, effectively generating high-quality stylized videos that align with textual content and closely resemble the style of reference images. Our project page is at https://zixuan-ye.github.io/stylemaster
big.LITTLE Vision Transformer for Efficient Visual Recognition
Oct 14, 2024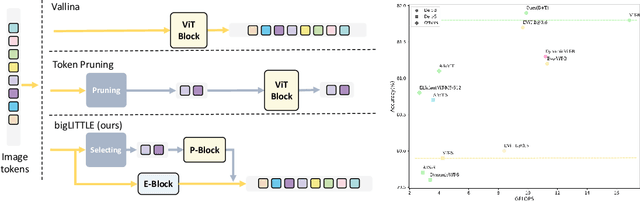
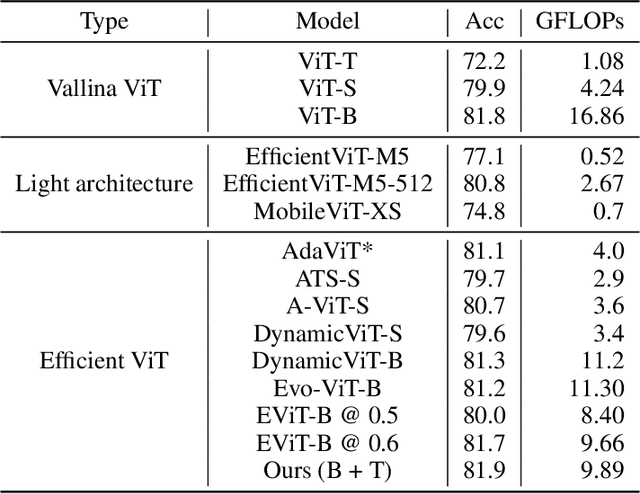
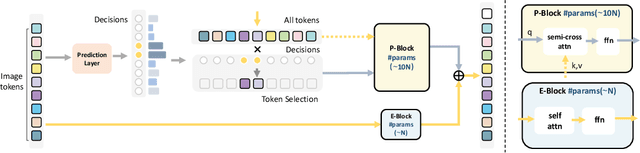

In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.
Training Matting Models without Alpha Labels
Aug 20, 2024



The labelling difficulty has been a longstanding problem in deep image matting. To escape from fine labels, this work explores using rough annotations such as trimaps coarsely indicating the foreground/background as supervision. We present that the cooperation between learned semantics from indicated known regions and proper assumed matting rules can help infer alpha values at transition areas. Inspired by the nonlocal principle in traditional image matting, we build a directional distance consistency loss (DDC loss) at each pixel neighborhood to constrain the alpha values conditioned on the input image. DDC loss forces the distance of similar pairs on the alpha matte and on its corresponding image to be consistent. In this way, the alpha values can be propagated from learned known regions to unknown transition areas. With only images and trimaps, a matting model can be trained under the supervision of a known loss and the proposed DDC loss. Experiments on AM-2K and P3M-10K dataset show that our paradigm achieves comparable performance with the fine-label-supervised baseline, while sometimes offers even more satisfying results than human-labelled ground truth. Code is available at \url{https://github.com/poppuppy/alpha-free-matting}.
SCAPE: A Simple and Strong Category-Agnostic Pose Estimator
Jul 18, 2024Category-Agnostic Pose Estimation (CAPE) aims to localize keypoints on an object of any category given few exemplars in an in-context manner. Prior arts involve sophisticated designs, e.g., sundry modules for similarity calculation and a two-stage framework, or takes in extra heatmap generation and supervision. We notice that CAPE is essentially a task about feature matching, which can be solved within the attention process. Therefore we first streamline the architecture into a simple baseline consisting of several pure self-attention layers and an MLP regression head -- this simplification means that one only needs to consider the attention quality to boost the performance of CAPE. Towards an effective attention process for CAPE, we further introduce two key modules: i) a global keypoint feature perceptor to inject global semantic information into support keypoints, and ii) a keypoint attention refiner to enhance inter-node correlation between keypoints. They jointly form a Simple and strong Category-Agnostic Pose Estimator (SCAPE). Experimental results show that SCAPE outperforms prior arts by 2.2 and 1.3 PCK under 1-shot and 5-shot settings with faster inference speed and lighter model capacity, excelling in both accuracy and efficiency. Code and models are available at https://github.com/tiny-smart/SCAPE
In-Context Matting
Mar 23, 2024We introduce in-context matting, a novel task setting of image matting. Given a reference image of a certain foreground and guided priors such as points, scribbles, and masks, in-context matting enables automatic alpha estimation on a batch of target images of the same foreground category, without additional auxiliary input. This setting marries good performance in auxiliary input-based matting and ease of use in automatic matting, which finds a good trade-off between customization and automation. To overcome the key challenge of accurate foreground matching, we introduce IconMatting, an in-context matting model built upon a pre-trained text-to-image diffusion model. Conditioned on inter- and intra-similarity matching, IconMatting can make full use of reference context to generate accurate target alpha mattes. To benchmark the task, we also introduce a novel testing dataset ICM-$57$, covering 57 groups of real-world images. Quantitative and qualitative results on the ICM-57 testing set show that IconMatting rivals the accuracy of trimap-based matting while retaining the automation level akin to automatic matting. Code is available at https://github.com/tiny-smart/in-context-matting
Infusing Definiteness into Randomness: Rethinking Composition Styles for Deep Image Matting
Dec 27, 2022We study the composition style in deep image matting, a notion that characterizes a data generation flow on how to exploit limited foregrounds and random backgrounds to form a training dataset. Prior art executes this flow in a completely random manner by simply going through the foreground pool or by optionally combining two foregrounds before foreground-background composition. In this work, we first show that naive foreground combination can be problematic and therefore derive an alternative formulation to reasonably combine foregrounds. Our second contribution is an observation that matting performance can benefit from a certain occurrence frequency of combined foregrounds and their associated source foregrounds during training. Inspired by this, we introduce a novel composition style that binds the source and combined foregrounds in a definite triplet. In addition, we also find that different orders of foreground combination lead to different foreground patterns, which further inspires a quadruplet-based composition style. Results under controlled experiments on four matting baselines show that our composition styles outperform existing ones and invite consistent performance improvement on both composited and real-world datasets. Code is available at: https://github.com/coconuthust/composition_styles
SAPA: Similarity-Aware Point Affiliation for Feature Upsampling
Sep 26, 2022



We introduce point affiliation into feature upsampling, a notion that describes the affiliation of each upsampled point to a semantic cluster formed by local decoder feature points with semantic similarity. By rethinking point affiliation, we present a generic formulation for generating upsampling kernels. The kernels encourage not only semantic smoothness but also boundary sharpness in the upsampled feature maps. Such properties are particularly useful for some dense prediction tasks such as semantic segmentation. The key idea of our formulation is to generate similarity-aware kernels by comparing the similarity between each encoder feature point and the spatially associated local region of decoder features. In this way, the encoder feature point can function as a cue to inform the semantic cluster of upsampled feature points. To embody the formulation, we further instantiate a lightweight upsampling operator, termed Similarity-Aware Point Affiliation (SAPA), and investigate its variants. SAPA invites consistent performance improvements on a number of dense prediction tasks, including semantic segmentation, object detection, depth estimation, and image matting. Code is available at: https://github.com/poppinace/sapa