 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacoDepth: Towards Efficient Radar-Camera Depth Estimation with One-stage Fusion
Apr 16, 2025



Radar-Camera depth estimation aims to predict dense and accurate metric depth by fusing input images and Radar data. Model efficiency is crucial for this task in pursuit of real-time processing on autonomous vehicles and robotic platforms. However, due to the sparsity of Radar returns, the prevailing methods adopt multi-stage frameworks with intermediate quasi-dense depth, which are time-consuming and not robust. To address these challenges, we propose TacoDepth, an efficient and accurate Radar-Camera depth estimation model with one-stage fusion. Specifically, the graph-based Radar structure extractor and the pyramid-based Radar fusion module are designed to capture and integrate the graph structures of Radar point clouds, delivering superior model efficiency and robustness without relying on the intermediate depth results. Moreover, TacoDepth can be flexible for different inference modes, providing a better balance of speed and accuracy. Extensive experiments are conducted to demonstrate the efficacy of our method. Compared with the previous state-of-the-art approach, TacoDepth improves depth accuracy and processing speed by 12.8% and 91.8%. Our work provides a new perspective on efficient Radar-Camera depth estimation.
Infusing Definiteness into Randomness: Rethinking Composition Styles for Deep Image Matting
Dec 27, 2022We study the composition style in deep image matting, a notion that characterizes a data generation flow on how to exploit limited foregrounds and random backgrounds to form a training dataset. Prior art executes this flow in a completely random manner by simply going through the foreground pool or by optionally combining two foregrounds before foreground-background composition. In this work, we first show that naive foreground combination can be problematic and therefore derive an alternative formulation to reasonably combine foregrounds. Our second contribution is an observation that matting performance can benefit from a certain occurrence frequency of combined foregrounds and their associated source foregrounds during training. Inspired by this, we introduce a novel composition style that binds the source and combined foregrounds in a definite triplet. In addition, we also find that different orders of foreground combination lead to different foreground patterns, which further inspires a quadruplet-based composition style. Results under controlled experiments on four matting baselines show that our composition styles outperform existing ones and invite consistent performance improvement on both composited and real-world datasets. Code is available at: https://github.com/coconuthust/composition_styles
SymmNeRF: Learning to Explore Symmetry Prior for Single-View View Synthesis
Sep 29, 2022
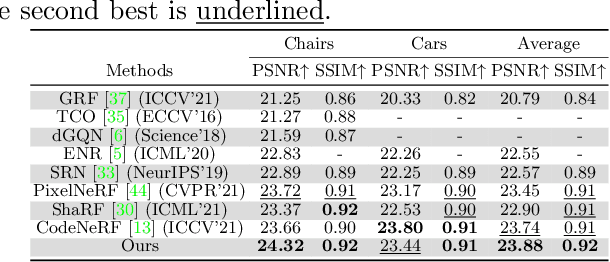
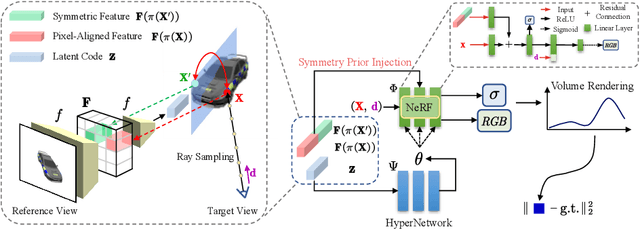
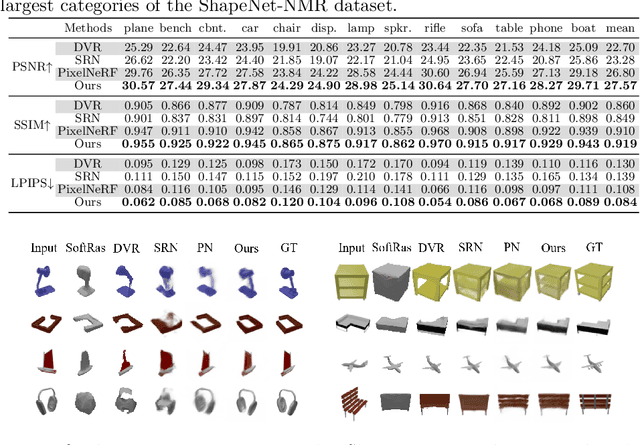
We study the problem of novel view synthesis of objects from a single image. Existing methods have demonstrated the potential in single-view view synthesis. However, they still fail to recover the fine appearance details, especially in self-occluded areas. This is because a single view only provides limited information. We observe that manmade objects usually exhibit symmetric appearances, which introduce additional prior knowledge. Motivated by this, we investigate the potential performance gains of explicitly embedding symmetry into the scene representation. In this paper, we propose SymmNeRF, a neural radiance field (NeRF) based framework that combines local and global conditioning under the introduction of symmetry priors. In particular, SymmNeRF takes the pixel-aligned image features and the corresponding symmetric features as extra inputs to the NeRF, whose parameters are generated by a hypernetwork. As the parameters are conditioned on the image-encoded latent codes, SymmNeRF is thus scene-independent and can generalize to new scenes. Experiments on synthetic and realworld datasets show that SymmNeRF synthesizes novel views with more details regardless of the pose transformation, and demonstrates good generalization when applied to unseen objects. Code is available at: https://github.com/xingyi-li/SymmNeRF.