 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Depth Refinement with Noisy Poisson Fusion
Sep 26, 2024
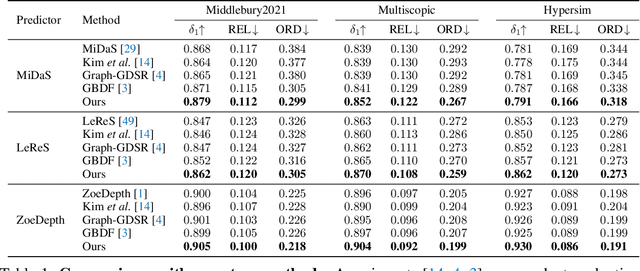

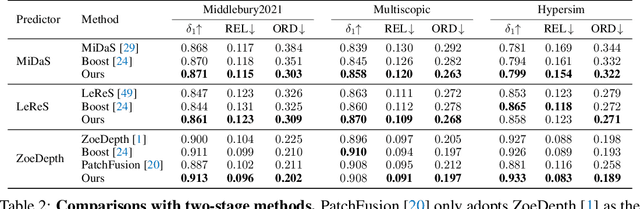
Depth refinement aims to infer high-resolution depth with fine-grained edges and details, refining low-resolution results of depth estimation models. The prevailing methods adopt tile-based manners by merging numerous patches, which lacks efficiency and produces inconsistency. Besides, prior arts suffer from fuzzy depth boundaries and limited generalizability. Analyzing the fundamental reasons for these limitations, we model depth refinement as a noisy Poisson fusion problem with local inconsistency and edge deformation noises. We propose the Self-distilled Depth Refinement (SDDR) framework to enforce robustness against the noises, which mainly consists of depth edge representation and edge-based guidance. With noisy depth predictions as input, SDDR generates low-noise depth edge representations as pseudo-labels by coarse-to-fine self-distillation. Edge-based guidance with edge-guided gradient loss and edge-based fusion loss serves as the optimization objective equivalent to Poisson fusion. When depth maps are better refined, the labels also become more noise-free. Our model can acquire strong robustness to the noises, achieving significant improvements in accuracy, edge quality, efficiency, and generalizability on five different benchmarks. Moreover, directly training another model with edge labels produced by SDDR brings improvements, suggesting that our method could help with training robust refinement models in future works.
PoseMamba: Monocular 3D Human Pose Estimation with Bidirectional Global-Local Spatio-Temporal State Space Model
Aug 07, 2024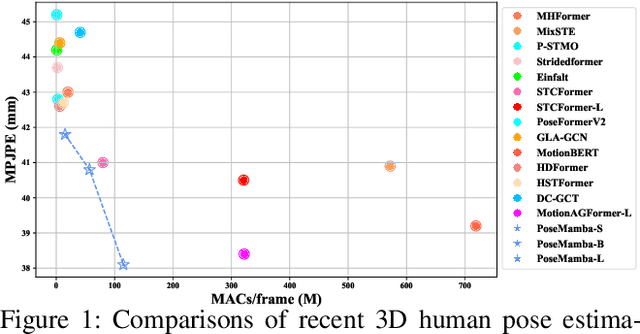

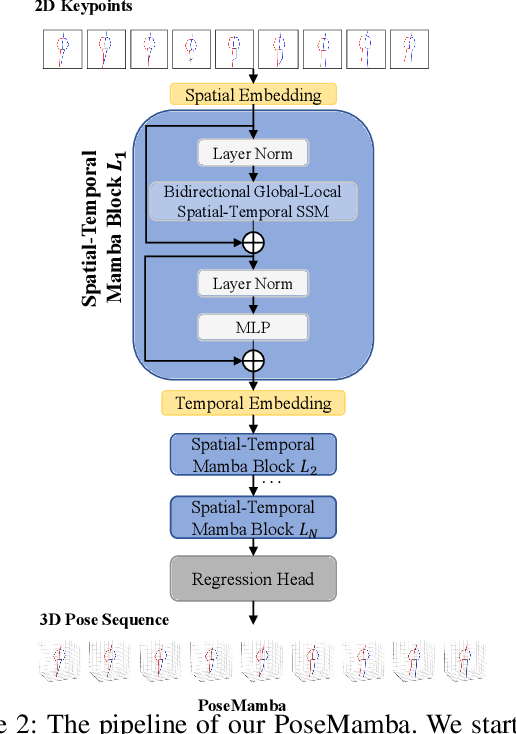

Transformers have significantly advanced the field of 3D human pose estimation (HPE). However, existing transformer-based methods primarily use self-attention mechanisms for spatio-temporal modeling, leading to a quadratic complexity, unidirectional modeling of spatio-temporal relationships, and insufficient learning of spatial-temporal correlations. Recently, the Mamba architecture, utilizing the state space model (SSM), has exhibited superior long-range modeling capabilities in a variety of vision tasks with linear complexity. In this paper, we propose PoseMamba, a novel purely SSM-based approach with linear complexity for 3D human pose estimation in monocular video. Specifically, we propose a bidirectional global-local spatio-temporal SSM block that comprehensively models human joint relations within individual frames as well as temporal correlations across frames. Within this bidirectional global-local spatio-temporal SSM block, we introduce a reordering strategy to enhance the local modeling capability of the SSM. This strategy provides a more logical geometric scanning order and integrates it with the global SSM, resulting in a combined global-local spatial scan. We have quantitatively and qualitatively evaluated our approach using two benchmark datasets: Human3.6M and MPI-INF-3DHP. Extensive experiments demonstrate that PoseMamba achieves state-of-the-art performance on both datasets while maintaining a smaller model size and reducing computational costs. The code and models will be released.
iControl3D: An Interactive System for Controllable 3D Scene Generation
Aug 03, 2024

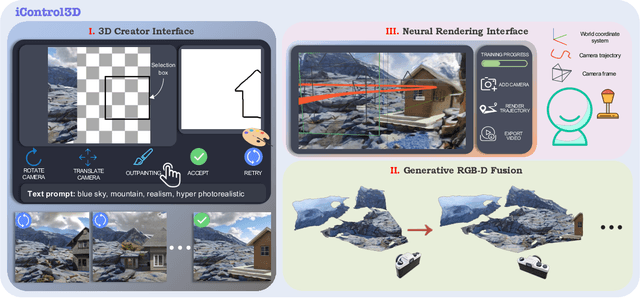
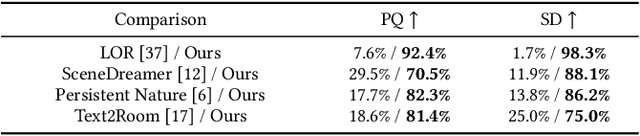
3D content creation has long been a complex and time-consuming process, often requiring specialized skills and resources. While recent advancements have allowed for text-guided 3D object and scene generation, they still fall short of providing sufficient control over the generation process, leading to a gap between the user's creative vision and the generated results. In this paper, we present iControl3D, a novel interactive system that empowers users to generate and render customizable 3D scenes with precise control. To this end, a 3D creator interface has been developed to provide users with fine-grained control over the creation process. Technically, we leverage 3D meshes as an intermediary proxy to iteratively merge individual 2D diffusion-generated images into a cohesive and unified 3D scene representation. To ensure seamless integration of 3D meshes, we propose to perform boundary-aware depth alignment before fusing the newly generated mesh with the existing one in 3D space. Additionally, to effectively manage depth discrepancies between remote content and foreground, we propose to model remote content separately with an environment map instead of 3D meshes. Finally, our neural rendering interface enables users to build a radiance field of their scene online and navigate the entire scene. Extensive experiments have been conducted to demonstrate the effectiveness of our system. The code will be made available at https://github.com/xingyi-li/iControl3D.
DyBluRF: Dynamic Neural Radiance Fields from Blurry Monocular Video
Mar 19, 2024Recent advancements in dynamic neural radiance field methods have yielded remarkable outcomes. However, these approaches rely on the assumption of sharp input images. When faced with motion blur, existing dynamic NeRF methods often struggle to generate high-quality novel views. In this paper, we propose DyBluRF, a dynamic radiance field approach that synthesizes sharp novel views from a monocular video affected by motion blur. To account for motion blur in input images, we simultaneously capture the camera trajectory and object Discrete Cosine Transform (DCT) trajectories within the scene. Additionally, we employ a global cross-time rendering approach to ensure consistent temporal coherence across the entire scene. We curate a dataset comprising diverse dynamic scenes that are specifically tailored for our task. Experimental results on our dataset demonstrate that our method outperforms existing approaches in generating sharp novel views from motion-blurred inputs while maintaining spatial-temporal consistency of the scene.
S-DyRF: Reference-Based Stylized Radiance Fields for Dynamic Scenes
Mar 13, 2024



Current 3D stylization methods often assume static scenes, which violates the dynamic nature of our real world. To address this limitation, we present S-DyRF, a reference-based spatio-temporal stylization method for dynamic neural radiance fields. However, stylizing dynamic 3D scenes is inherently challenging due to the limited availability of stylized reference images along the temporal axis. Our key insight lies in introducing additional temporal cues besides the provided reference. To this end, we generate temporal pseudo-references from the given stylized reference. These pseudo-references facilitate the propagation of style information from the reference to the entire dynamic 3D scene. For coarse style transfer, we enforce novel views and times to mimic the style details present in pseudo-references at the feature level. To preserve high-frequency details, we create a collection of stylized temporal pseudo-rays from temporal pseudo-references. These pseudo-rays serve as detailed and explicit stylization guidance for achieving fine style transfer. Experiments on both synthetic and real-world datasets demonstrate that our method yields plausible stylized results of space-time view synthesis on dynamic 3D scenes.
Semi-Supervised Class-Agnostic Motion Prediction with Pseudo Label Regeneration and BEVMix
Dec 14, 2023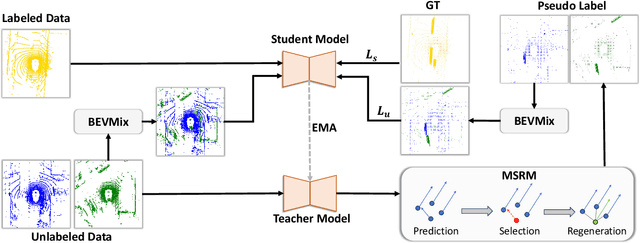
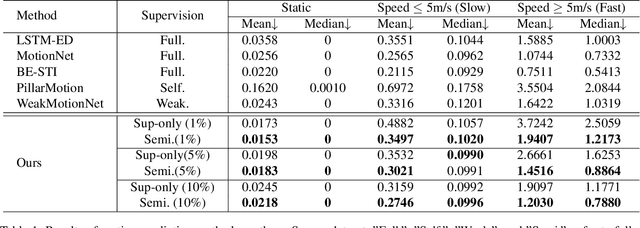
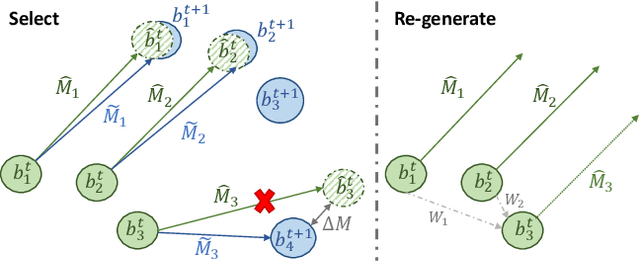
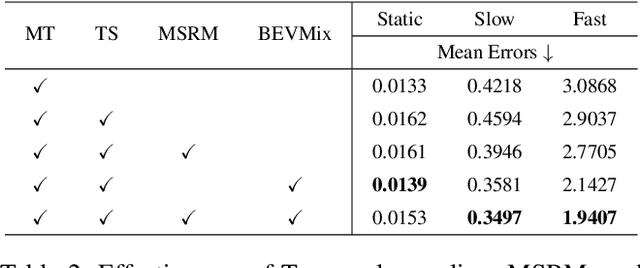
Class-agnostic motion prediction methods aim to comprehend motion within open-world scenarios, holding significance for autonomous driving systems. However, training a high-performance model in a fully-supervised manner always requires substantial amounts of manually annotated data, which can be both expensive and time-consuming to obtain. To address this challenge, our study explores the potential of semi-supervised learning (SSL) for class-agnostic motion prediction. Our SSL framework adopts a consistency-based self-training paradigm, enabling the model to learn from unlabeled data by generating pseudo labels through test-time inference. To improve the quality of pseudo labels, we propose a novel motion selection and re-generation module. This module effectively selects reliable pseudo labels and re-generates unreliable ones. Furthermore, we propose two data augmentation strategies: temporal sampling and BEVMix. These strategies facilitate consistency regularization in SSL. Experiments conducted on nuScenes demonstrate that our SSL method can surpass the self-supervised approach by a large margin by utilizing only a tiny fraction of labeled data. Furthermore, our method exhibits comparable performance to weakly and some fully supervised methods. These results highlight the ability of our method to strike a favorable balance between annotation costs and performance. Code will be available at https://github.com/kwwcv/SSMP.
Make-It-4D: Synthesizing a Consistent Long-Term Dynamic Scene Video from a Single Image
Aug 20, 2023
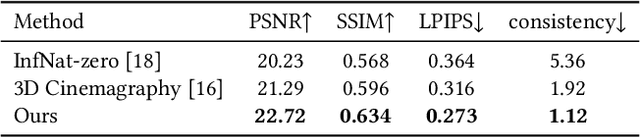
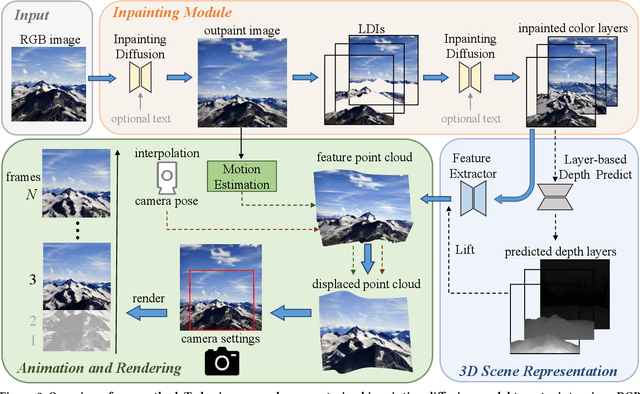
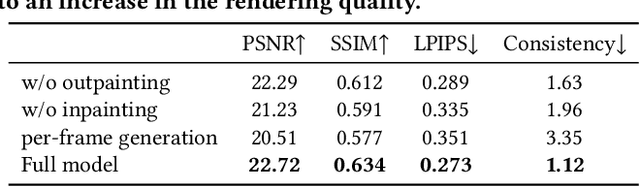
We study the problem of synthesizing a long-term dynamic video from only a single image. This is challenging since it requires consistent visual content movements given large camera motions. Existing methods either hallucinate inconsistent perpetual views or struggle with long camera trajectories. To address these issues, it is essential to estimate the underlying 4D (including 3D geometry and scene motion) and fill in the occluded regions. To this end, we present Make-It-4D, a novel method that can generate a consistent long-term dynamic video from a single image. On the one hand, we utilize layered depth images (LDIs) to represent a scene, and they are then unprojected to form a feature point cloud. To animate the visual content, the feature point cloud is displaced based on the scene flow derived from motion estimation and the corresponding camera pose. Such 4D representation enables our method to maintain the global consistency of the generated dynamic video. On the other hand, we fill in the occluded regions by using a pretrained diffusion model to inpaint and outpaint the input image. This enables our method to work under large camera motions. Benefiting from our design, our method can be training-free which saves a significant amount of training time. Experimental results demonstrate the effectiveness of our approach, which showcases compelling rendering results.
Neural Video Depth Stabilizer
Aug 10, 2023Video depth estimation aims to infer temporally consistent depth. Some methods achieve temporal consistency by finetuning a single-image depth model during test time using geometry and re-projection constraints, which is inefficient and not robust. An alternative approach is to learn how to enforce temporal consistency from data, but this requires well-designed models and sufficient video depth data. To address these challenges, we propose a plug-and-play framework called Neural Video Depth Stabilizer (NVDS) that stabilizes inconsistent depth estimations and can be applied to different single-image depth models without extra effort. We also introduce a large-scale dataset, Video Depth in the Wild (VDW), which consists of 14,203 videos with over two million frames, making it the largest natural-scene video depth dataset to our knowledge. We evaluate our method on the VDW dataset as well as two public benchmarks and demonstrate significant improvements in consistency, accuracy, and efficiency compared to previous approaches. Our work serves as a solid baseline and provides a data foundation for learning-based video depth models. We will release our dataset and code for future research.
Diffusion-Augmented Depth Prediction with Sparse Annotations
Aug 04, 2023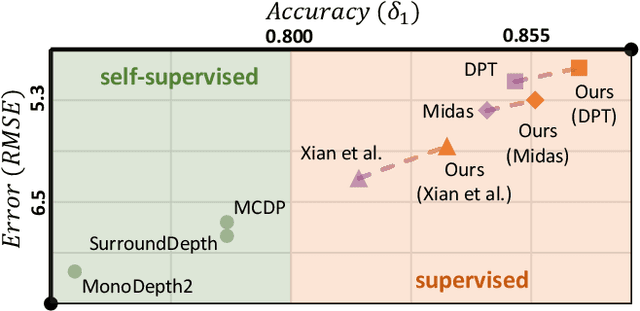



Depth estimation aims to predict dense depth maps. In autonomous driving scenes, sparsity of annotations makes the task challenging. Supervised models produce concave objects due to insufficient structural information. They overfit to valid pixels and fail to restore spatial structures. Self-supervised methods are proposed for the problem. Their robustness is limited by pose estimation, leading to erroneous results in natural scenes. In this paper, we propose a supervised framework termed Diffusion-Augmented Depth Prediction (DADP). We leverage the structural characteristics of diffusion model to enforce depth structures of depth models in a plug-and-play manner. An object-guided integrality loss is also proposed to further enhance regional structure integrality by fetching objective information. We evaluate DADP on three driving benchmarks and achieve significant improvements in depth structures and robustness. Our work provides a new perspective on depth estimation with sparse annotations in autonomous driving scenes.
Defocus to focus: Photo-realistic bokeh rendering by fusing defocus and radiance priors
Jun 07, 2023



We consider the problem of realistic bokeh rendering from a single all-in-focus image. Bokeh rendering mimics aesthetic shallow depth-of-field (DoF) in professional photography, but these visual effects generated by existing methods suffer from simple flat background blur and blurred in-focus regions, giving rise to unrealistic rendered results. In this work, we argue that realistic bokeh rendering should (i) model depth relations and distinguish in-focus regions, (ii) sustain sharp in-focus regions, and (iii) render physically accurate Circle of Confusion (CoC). To this end, we present a Defocus to Focus (D2F) framework to learn realistic bokeh rendering by fusing defocus priors with the all-in-focus image and by implementing radiance priors in layered fusion. Since no depth map is provided, we introduce defocus hallucination to integrate depth by learning to focus. The predicted defocus map implies the blur amount of bokeh and is used to guide weighted layered rendering. In layered rendering, we fuse images blurred by different kernels based on the defocus map. To increase the reality of the bokeh, we adopt radiance virtualization to simulate scene radiance. The scene radiance used in weighted layered rendering reassigns weights in the soft disk kernel to produce the CoC. To ensure the sharpness of in-focus regions, we propose to fuse upsampled bokeh images and original images. We predict the initial fusion mask from our defocus map and refine the mask with a deep network. We evaluate our model on a large-scale bokeh dataset. Extensive experiments show that our approach is capable of rendering visually pleasing bokeh effects in complex scenes. In particular, our solution receives the runner-up award in the AIM 2020 Rendering Realistic Bokeh Challenge.
* Published at Information Fusion 2023 https://www.sciencedirect.com/science/article/pii/S1566253522001221