 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandaPose: 3D Human Pose Lifting from a Single Image via Propagating 2D Pose Prior to 3D Anchor Space
Feb 01, 20263D human pose lifting from a single RGB image is a challenging task in 3D vision. Existing methods typically establish a direct joint-to-joint mapping from 2D to 3D poses based on 2D features. This formulation suffers from two fundamental limitations: inevitable error propagation from input predicted 2D pose to 3D predictions and inherent difficulties in handling self-occlusion cases. In this paper, we propose PandaPose, a 3D human pose lifting approach via propagating 2D pose prior to 3D anchor space as the unified intermediate representation. Specifically, our 3D anchor space comprises: (1) Joint-wise 3D anchors in the canonical coordinate system, providing accurate and robust priors to mitigate 2D pose estimation inaccuracies. (2) Depth-aware joint-wise feature lifting that hierarchically integrates depth information to resolve self-occlusion ambiguities. (3) The anchor-feature interaction decoder that incorporates 3D anchors with lifted features to generate unified anchor queries encapsulating joint-wise 3D anchor set, visual cues and geometric depth information. The anchor queries are further employed to facilitate anchor-to-joint ensemble prediction. Experiments on three well-established benchmarks (i.e., Human3.6M, MPI-INF-3DHP and 3DPW) demonstrate the superiority of our proposition. The substantial reduction in error by $14.7\%$ compared to SOTA methods on the challenging conditions of Human3.6M and qualitative comparisons further showcase the effectiveness and robustness of our approach.
Self-Distilled Depth Refinement with Noisy Poisson Fusion
Sep 26, 2024
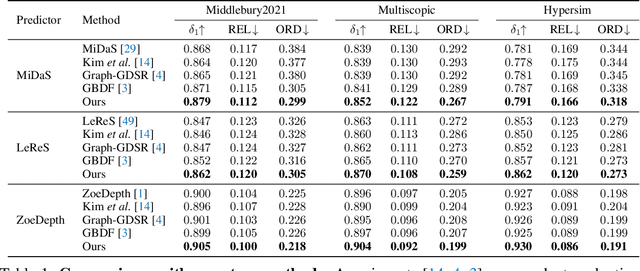

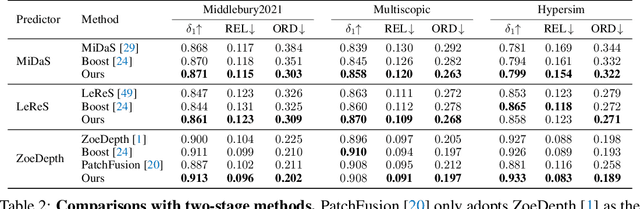
Depth refinement aims to infer high-resolution depth with fine-grained edges and details, refining low-resolution results of depth estimation models. The prevailing methods adopt tile-based manners by merging numerous patches, which lacks efficiency and produces inconsistency. Besides, prior arts suffer from fuzzy depth boundaries and limited generalizability. Analyzing the fundamental reasons for these limitations, we model depth refinement as a noisy Poisson fusion problem with local inconsistency and edge deformation noises. We propose the Self-distilled Depth Refinement (SDDR) framework to enforce robustness against the noises, which mainly consists of depth edge representation and edge-based guidance. With noisy depth predictions as input, SDDR generates low-noise depth edge representations as pseudo-labels by coarse-to-fine self-distillation. Edge-based guidance with edge-guided gradient loss and edge-based fusion loss serves as the optimization objective equivalent to Poisson fusion. When depth maps are better refined, the labels also become more noise-free. Our model can acquire strong robustness to the noises, achieving significant improvements in accuracy, edge quality, efficiency, and generalizability on five different benchmarks. Moreover, directly training another model with edge labels produced by SDDR brings improvements, suggesting that our method could help with training robust refinement models in future works.
Towards Robust Monocular Depth Estimation in Non-Lambertian Surfaces
Aug 12, 2024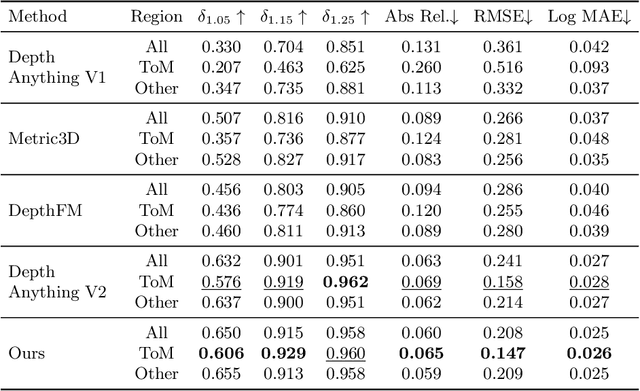
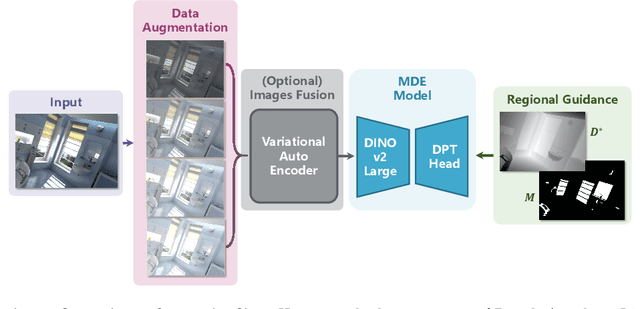
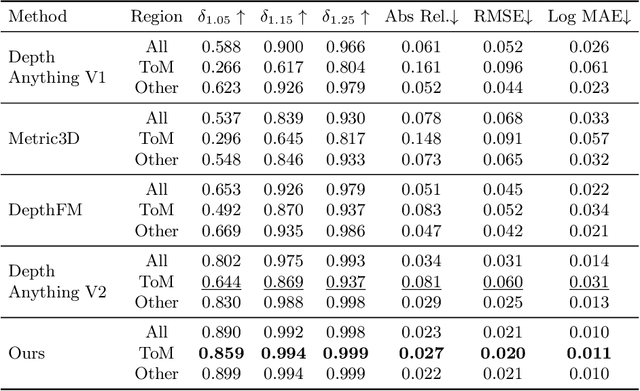

In the field of monocular depth estimation (MDE), many models with excellent zero-shot performance in general scenes emerge recently. However, these methods often fail in predicting non-Lambertian surfaces, such as transparent or mirror (ToM) surfaces, due to the unique reflective properties of these regions. Previous methods utilize externally provided ToM masks and aim to obtain correct depth maps through direct in-painting of RGB images. These methods highly depend on the accuracy of additional input masks, and the use of random colors during in-painting makes them insufficiently robust. We are committed to incrementally enabling the baseline model to directly learn the uniqueness of non-Lambertian surface regions for depth estimation through a well-designed training framework. Therefore, we propose non-Lambertian surface regional guidance, which constrains the predictions of MDE model from the gradient domain to enhance its robustness. Noting the significant impact of lighting on this task, we employ the random tone-mapping augmentation during training to ensure the network can predict correct results for varying lighting inputs. Additionally, we propose an optional novel lighting fusion module, which uses Variational Autoencoders to fuse multiple images and obtain the most advantageous input RGB image for depth estimation when multi-exposure images are available. Our method achieves accuracy improvements of 33.39% and 5.21% in zero-shot testing on the Booster and Mirror3D dataset for non-Lambertian surfaces, respectively, compared to the Depth Anything V2. The state-of-the-art performance of 90.75 in delta1.05 within the ToM regions on the TRICKY2024 competition test set demonstrates the effectiveness of our approach.
Diffusion-Augmented Depth Prediction with Sparse Annotations
Aug 04, 2023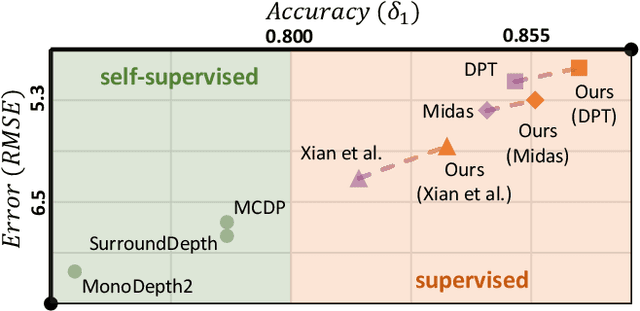



Depth estimation aims to predict dense depth maps. In autonomous driving scenes, sparsity of annotations makes the task challenging. Supervised models produce concave objects due to insufficient structural information. They overfit to valid pixels and fail to restore spatial structures. Self-supervised methods are proposed for the problem. Their robustness is limited by pose estimation, leading to erroneous results in natural scenes. In this paper, we propose a supervised framework termed Diffusion-Augmented Depth Prediction (DADP). We leverage the structural characteristics of diffusion model to enforce depth structures of depth models in a plug-and-play manner. An object-guided integrality loss is also proposed to further enhance regional structure integrality by fetching objective information. We evaluate DADP on three driving benchmarks and achieve significant improvements in depth structures and robustness. Our work provides a new perspective on depth estimation with sparse annotations in autonomous driving scenes.
A2J-Transformer: Anchor-to-Joint Transformer Network for 3D Interacting Hand Pose Estimation from a Single RGB Image
Apr 07, 2023

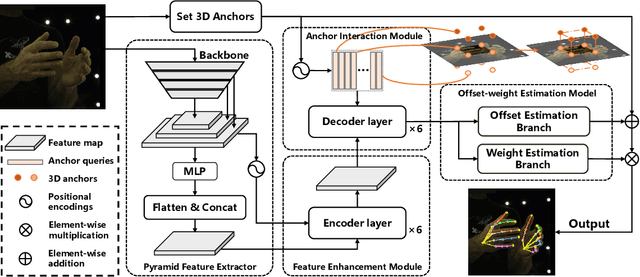
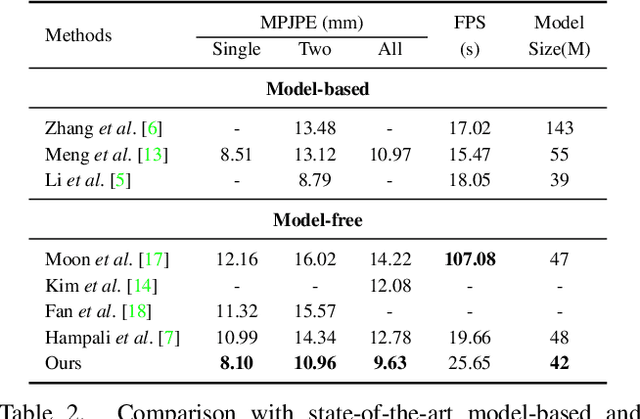
3D interacting hand pose estimation from a single RGB image is a challenging task, due to serious self-occlusion and inter-occlusion towards hands, confusing similar appearance patterns between 2 hands, ill-posed joint position mapping from 2D to 3D, etc.. To address these, we propose to extend A2J-the state-of-the-art depth-based 3D single hand pose estimation method-to RGB domain under interacting hand condition. Our key idea is to equip A2J with strong local-global aware ability to well capture interacting hands' local fine details and global articulated clues among joints jointly. To this end, A2J is evolved under Transformer's non-local encoding-decoding framework to build A2J-Transformer. It holds 3 main advantages over A2J. First, self-attention across local anchor points is built to make them global spatial context aware to better capture joints' articulation clues for resisting occlusion. Secondly, each anchor point is regarded as learnable query with adaptive feature learning for facilitating pattern fitting capacity, instead of having the same local representation with the others. Last but not least, anchor point locates in 3D space instead of 2D as in A2J, to leverage 3D pose prediction. Experiments on challenging InterHand 2.6M demonstrate that, A2J-Transformer can achieve state-of-the-art model-free performance (3.38mm MPJPE advancement in 2-hand case) and can also be applied to depth domain with strong generalization.