 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBokehFlow: Depth-Free Controllable Bokeh Rendering via Flow Matching
Nov 19, 2025
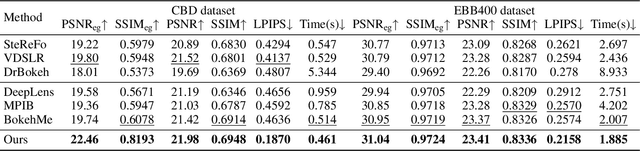
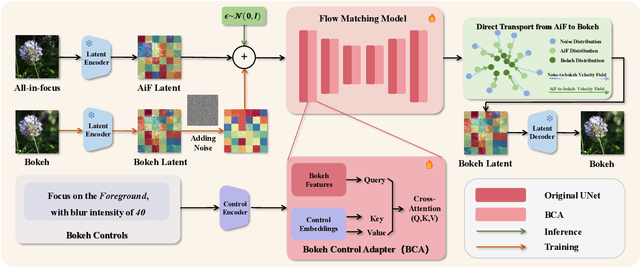
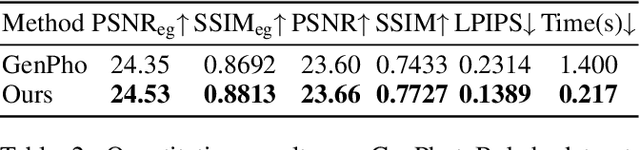
Bokeh rendering simulates the shallow depth-of-field effect in photography, enhancing visual aesthetics and guiding viewer attention to regions of interest. Although recent approaches perform well, rendering controllable bokeh without additional depth inputs remains a significant challenge. Existing classical and neural controllable methods rely on accurate depth maps, while generative approaches often struggle with limited controllability and efficiency. In this paper, we propose BokehFlow, a depth-free framework for controllable bokeh rendering based on flow matching. BokehFlow directly synthesizes photorealistic bokeh effects from all-in-focus images, eliminating the need for depth inputs. It employs a cross-attention mechanism to enable semantic control over both focus regions and blur intensity via text prompts. To support training and evaluation, we collect and synthesize four datasets. Extensive experiments demonstrate that BokehFlow achieves visually compelling bokeh effects and offers precise control, outperforming existing depth-dependent and generative methods in both rendering quality and efficiency.
Towards Robust Monocular Depth Estimation in Non-Lambertian Surfaces
Aug 12, 2024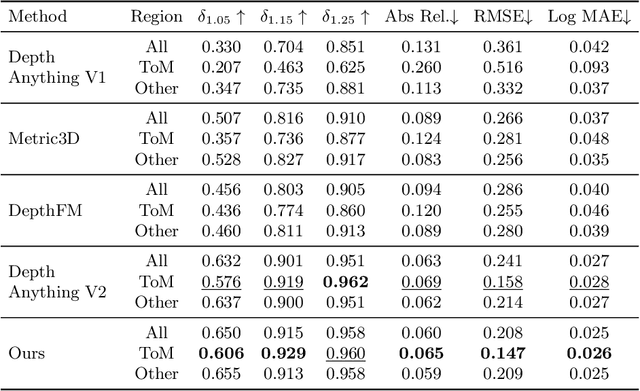
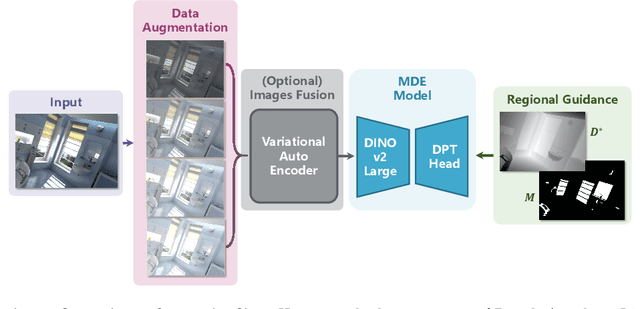
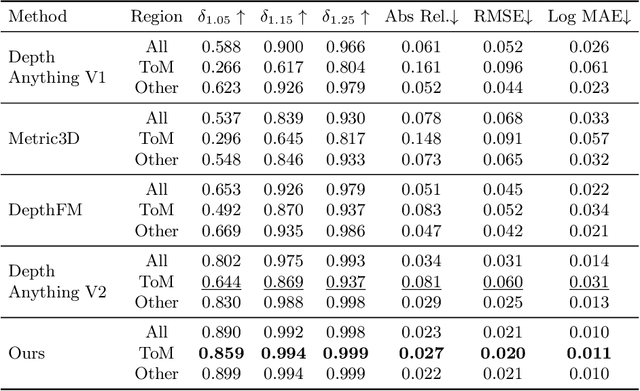

In the field of monocular depth estimation (MDE), many models with excellent zero-shot performance in general scenes emerge recently. However, these methods often fail in predicting non-Lambertian surfaces, such as transparent or mirror (ToM) surfaces, due to the unique reflective properties of these regions. Previous methods utilize externally provided ToM masks and aim to obtain correct depth maps through direct in-painting of RGB images. These methods highly depend on the accuracy of additional input masks, and the use of random colors during in-painting makes them insufficiently robust. We are committed to incrementally enabling the baseline model to directly learn the uniqueness of non-Lambertian surface regions for depth estimation through a well-designed training framework. Therefore, we propose non-Lambertian surface regional guidance, which constrains the predictions of MDE model from the gradient domain to enhance its robustness. Noting the significant impact of lighting on this task, we employ the random tone-mapping augmentation during training to ensure the network can predict correct results for varying lighting inputs. Additionally, we propose an optional novel lighting fusion module, which uses Variational Autoencoders to fuse multiple images and obtain the most advantageous input RGB image for depth estimation when multi-exposure images are available. Our method achieves accuracy improvements of 33.39% and 5.21% in zero-shot testing on the Booster and Mirror3D dataset for non-Lambertian surfaces, respectively, compared to the Depth Anything V2. The state-of-the-art performance of 90.75 in delta1.05 within the ToM regions on the TRICKY2024 competition test set demonstrates the effectiveness of our approach.