 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAFE-AD: Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving
Apr 09, 2025Imitation learning based planning tasks on the nuPlan dataset have gained great interest due to their potential to generate human-like driving behaviors. However, open-loop training on the nuPlan dataset tends to cause causal confusion during closed-loop testing, and the dataset also presents a long-tail distribution of scenarios. These issues introduce challenges for imitation learning. To tackle these problems, we introduce CAFE-AD, a Cross-Scenario Adaptive Feature Enhancement for Trajectory Planning in Autonomous Driving method, designed to enhance feature representation across various scenario types. We develop an adaptive feature pruning module that ranks feature importance to capture the most relevant information while reducing the interference of noisy information during training. Moreover, we propose a cross-scenario feature interpolation module that enhances scenario information to introduce diversity, enabling the network to alleviate over-fitting in dominant scenarios. We evaluate our method CAFE-AD on the challenging public nuPlan Test14-Hard closed-loop simulation benchmark. The results demonstrate that CAFE-AD outperforms state-of-the-art methods including rule-based and hybrid planners, and exhibits the potential in mitigating the impact of long-tail distribution within the dataset. Additionally, we further validate its effectiveness in real-world environments. The code and models will be made available at https://github.com/AlniyatRui/CAFE-AD.
Towards Robust Monocular Depth Estimation in Non-Lambertian Surfaces
Aug 12, 2024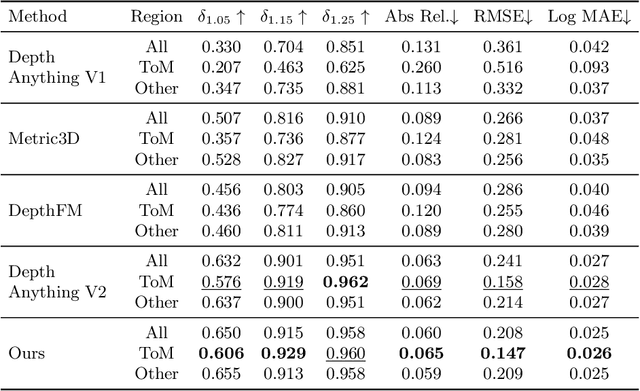
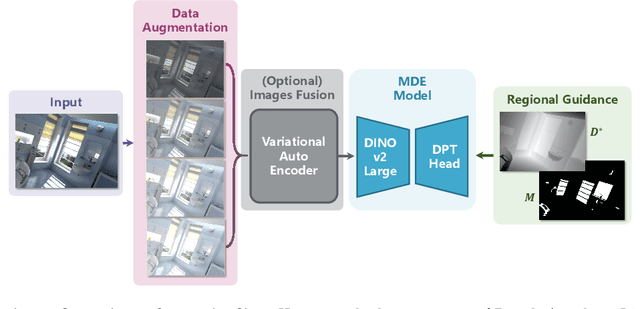
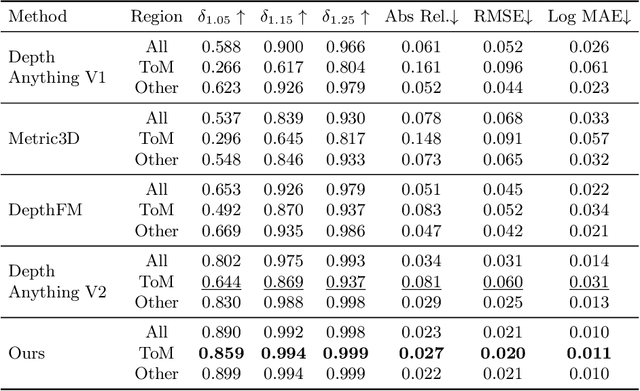

In the field of monocular depth estimation (MDE), many models with excellent zero-shot performance in general scenes emerge recently. However, these methods often fail in predicting non-Lambertian surfaces, such as transparent or mirror (ToM) surfaces, due to the unique reflective properties of these regions. Previous methods utilize externally provided ToM masks and aim to obtain correct depth maps through direct in-painting of RGB images. These methods highly depend on the accuracy of additional input masks, and the use of random colors during in-painting makes them insufficiently robust. We are committed to incrementally enabling the baseline model to directly learn the uniqueness of non-Lambertian surface regions for depth estimation through a well-designed training framework. Therefore, we propose non-Lambertian surface regional guidance, which constrains the predictions of MDE model from the gradient domain to enhance its robustness. Noting the significant impact of lighting on this task, we employ the random tone-mapping augmentation during training to ensure the network can predict correct results for varying lighting inputs. Additionally, we propose an optional novel lighting fusion module, which uses Variational Autoencoders to fuse multiple images and obtain the most advantageous input RGB image for depth estimation when multi-exposure images are available. Our method achieves accuracy improvements of 33.39% and 5.21% in zero-shot testing on the Booster and Mirror3D dataset for non-Lambertian surfaces, respectively, compared to the Depth Anything V2. The state-of-the-art performance of 90.75 in delta1.05 within the ToM regions on the TRICKY2024 competition test set demonstrates the effectiveness of our approach.
LDP: A Local Diffusion Planner for Efficient Robot Navigation and Collision Avoidance
Jul 02, 2024The conditional diffusion model has been demonstrated as an efficient tool for learning robot policies, owing to its advancement to accurately model the conditional distribution of policies. The intricate nature of real-world scenarios, characterized by dynamic obstacles and maze-like structures, underscores the complexity of robot local navigation decision-making as a conditional distribution problem. Nevertheless, leveraging the diffusion model for robot local navigation is not trivial and encounters several under-explored challenges: (1) Data Urgency. The complex conditional distribution in local navigation needs training data to include diverse policy in diverse real-world scenarios; (2) Myopic Observation. Due to the diversity of the perception scenarios, diffusion decisions based on the local perspective of robots may prove suboptimal for completing the entire task, as they often lack foresight. In certain scenarios requiring detours, the robot may become trapped. To address these issues, our approach begins with an exploration of a diverse data generation mechanism that encompasses multiple agents exhibiting distinct preferences through target selection informed by integrated global-local insights. Then, based on this diverse training data, a diffusion agent is obtained, capable of excellent collision avoidance in diverse scenarios. Subsequently, we augment our Local Diffusion Planner, also known as LDP by incorporating global observations in a lightweight manner. This enhancement broadens the observational scope of LDP, effectively mitigating the risk of becoming ensnared in local optima and promoting more robust navigational decisions.
TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Apr 18, 2024As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.