 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Prototype-Driven Multimodal Pretraining for Cancer Prognosis with Missing Modalities
Apr 05, 2026Multimodal self-supervised pretraining offers a promising route to cancer prognosis by integrating histopathology whole-slide images, gene expression, and pathology reports, yet most existing approaches require fully paired and complete inputs. In practice, clinical cohorts are fragmented and often miss one or more modalities, limiting both supervised fusion and scalable multimodal pretraining. We propose PRIME, a missing-aware multimodal self-supervised pretraining framework that learns robust and transferable representations from partially observed cohorts. PRIME maps heterogeneous modality embeddings into a unified token space and introduces a shared prototype memory bank for latent-space semantic imputation via patient-level consensus retrieval, producing structurally aligned tokens without reconstructing raw signals. Two complementary pretraining objectives: inter-modality alignment and post-fusion consistency under structured missingness augmentation, jointly learn representations that remain predictive under arbitrary modality subsets. We evaluate PRIME on The Cancer Genome Atlas with label-free pretraining on 32 cancer types and downstream 5-fold evaluation on five cohorts across overall survival prediction, 3-year mortality classification, and 3-year recurrence classification. PRIME achieves the best macro-average performance among all compared methods, reaching 0.653 C-index, 0.689 AUROC, and 0.637 AUROC on the three tasks, respectively, while improving robustness under test-time missingness and supporting parameter-efficient and label-efficient adaptation. These results support missing-aware multimodal pretraining as a practical strategy for prognosis modeling in fragmented clinical data settings.
Understanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models
Apr 03, 2026The recent success of reinforcement learning (RL) in large reasoning models has inspired the growing adoption of RL for post-training Multimodal Large Language Models (MLLMs) to enhance their visual reasoning capabilities. Although many studies have reported improved performance, it remains unclear whether RL training truly enables models to learn from visual information. In this work, we propose the Hallucination-as-Cue Framework, an analytical framework designed to investigate the effects of RL-based post-training on multimodal reasoning models from the perspective of model hallucination. Specifically, we introduce hallucination-inductive, modality-specific corruptions that remove or replace essential information required to derive correct answers, thereby forcing the model to reason by hallucination. By applying these corruptions during both training and evaluation, our framework provides a unique perspective for diagnosing RL training dynamics and understanding the intrinsic properties of datasets. Through extensive experiments and analyses across multiple multimodal reasoning benchmarks, we reveal that the role of model hallucination for RL-training is more significant than previously recognized. For instance, we find that RL post-training under purely hallucination-inductive settings can still significantly improve models' reasoning performance, and in some cases even outperform standard training. These findings challenge prevailing assumptions about MLLM reasoning training and motivate the development of more modality-aware RL-based training designs.
A Replicate-and-Quantize Strategy for Plug-and-Play Load Balancing of Sparse Mixture-of-Experts LLMs
Feb 23, 2026Sparse Mixture-of-Experts (SMoE) architectures are increasingly used to scale large language models efficiently, delivering strong accuracy under fixed compute budgets. However, SMoE models often suffer from severe load imbalance across experts, where a small subset of experts receives most tokens while others are underutilized. Prior work has focused mainly on training-time solutions such as routing regularization or auxiliary losses, leaving inference-time behavior, which is critical for deployment, less explored. We present a systematic analysis of expert routing during inference and identify three findings: (i) load imbalance persists and worsens with larger batch sizes, (ii) selection frequency does not reliably reflect expert importance, and (iii) overall expert workload and importance can be estimated using a small calibration set. These insights motivate inference-time mechanisms that rebalance workloads without retraining or router modification. We propose Replicate-and-Quantize (R&Q), a training-free and near-lossless framework for dynamic workload rebalancing. In each layer, heavy-hitter experts are replicated to increase parallel capacity, while less critical experts and replicas are quantized to remain within the original memory budget. We also introduce a Load-Imbalance Score (LIS) to measure routing skew by comparing heavy-hitter load to an equal allocation baseline. Experiments across representative SMoE models and benchmarks show up to 1.4x reduction in imbalance with accuracy maintained within +/-0.6%, enabling more predictable and efficient inference.
NeuroCanvas: VLLM-Powered Robust Seizure Detection by Reformulating Multichannel EEG as Image
Feb 04, 2026Accurate and timely seizure detection from Electroencephalography (EEG) is critical for clinical intervention, yet manual review of long-term recordings is labor-intensive. Recent efforts to encode EEG signals into large language models (LLMs) show promise in handling neural signals across diverse patients, but two significant challenges remain: (1) multi-channel heterogeneity, as seizure-relevant information varies substantially across EEG channels, and (2) computing inefficiency, as the EEG signals need to be encoded into a massive number of tokens for the prediction. To address these issues, we draw the EEG signal and propose the novel NeuroCanvas framework. Specifically, NeuroCanvas consists of two modules: (i) The Entropy-guided Channel Selector (ECS) selects the seizure-relevant channels input to LLM and (ii) the following Canvas of Neuron Signal (CNS) converts selected multi-channel heterogeneous EEG signals into structured visual representations. The ECS module alleviates the multi-channel heterogeneity issue, and the CNS uses compact visual tokens to represent the EEG signals that improve the computing efficiency. We evaluate NeuroCanvas across multiple seizure detection datasets, demonstrating a significant improvement of $20\%$ in F1 score and reductions of $88\%$ in inference latency. These results highlight NeuroCanvas as a scalable and effective solution for real-time and resource-efficient seizure detection in clinical practice.The code will be released at https://github.com/Yanchen30247/seizure_detect.
Topology-Independent Robustness of the Weighted Mean under Label Poisoning Attacks in Heterogeneous Decentralized Learning
Jan 06, 2026Robustness to malicious attacks is crucial for practical decentralized signal processing and machine learning systems. A typical example of such attacks is label poisoning, meaning that some agents possess corrupted local labels and share models trained on these poisoned data. To defend against malicious attacks, existing works often focus on designing robust aggregators; meanwhile, the weighted mean aggregator is typically considered a simple, vulnerable baseline. This paper analyzes the robustness of decentralized gradient descent under label poisoning attacks, considering both robust and weighted mean aggregators. Theoretical results reveal that the learning errors of robust aggregators depend on the network topology, whereas the performance of weighted mean aggregator is topology-independent. Remarkably, the weighted mean aggregator, although often considered vulnerable, can outperform robust aggregators under sufficient heterogeneity, particularly when: (i) the global contamination rate (i.e., the fraction of poisoned agents for the entire network) is smaller than the local contamination rate (i.e., the maximal fraction of poisoned neighbors for the regular agents); (ii) the network of regular agents is disconnected; or (iii) the network of regular agents is sparse and the local contamination rate is high. Empirical results support our theoretical findings, highlighting the important role of network topology in the robustness to label poisoning attacks.
Circumventing Backdoor Space via Weight Symmetry
Jun 09, 2025Deep neural networks are vulnerable to backdoor attacks, where malicious behaviors are implanted during training. While existing defenses can effectively purify compromised models, they typically require labeled data or specific training procedures, making them difficult to apply beyond supervised learning settings. Notably, recent studies have shown successful backdoor attacks across various learning paradigms, highlighting a critical security concern. To address this gap, we propose Two-stage Symmetry Connectivity (TSC), a novel backdoor purification defense that operates independently of data format and requires only a small fraction of clean samples. Through theoretical analysis, we prove that by leveraging permutation invariance in neural networks and quadratic mode connectivity, TSC amplifies the loss on poisoned samples while maintaining bounded clean accuracy. Experiments demonstrate that TSC achieves robust performance comparable to state-of-the-art methods in supervised learning scenarios. Furthermore, TSC generalizes to self-supervised learning frameworks, such as SimCLR and CLIP, maintaining its strong defense capabilities. Our code is available at https://github.com/JiePeng104/TSC.
I2MoE: Interpretable Multimodal Interaction-aware Mixture-of-Experts
May 25, 2025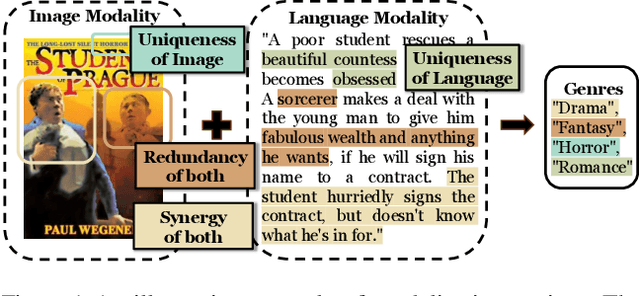
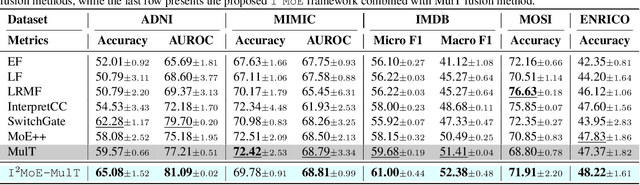

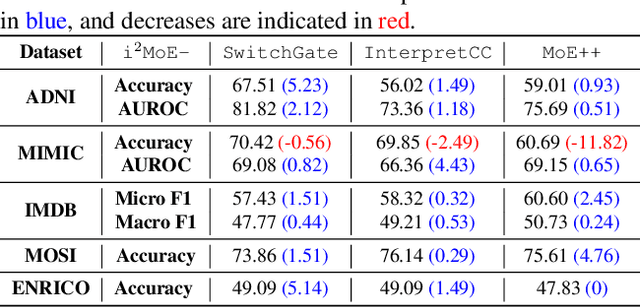
Modality fusion is a cornerstone of multimodal learning, enabling information integration from diverse data sources. However, vanilla fusion methods are limited by (1) inability to account for heterogeneous interactions between modalities and (2) lack of interpretability in uncovering the multimodal interactions inherent in the data. To this end, we propose I2MoE (Interpretable Multimodal Interaction-aware Mixture of Experts), an end-to-end MoE framework designed to enhance modality fusion by explicitly modeling diverse multimodal interactions, as well as providing interpretation on a local and global level. First, I2MoE utilizes different interaction experts with weakly supervised interaction losses to learn multimodal interactions in a data-driven way. Second, I2MoE deploys a reweighting model that assigns importance scores for the output of each interaction expert, which offers sample-level and dataset-level interpretation. Extensive evaluation of medical and general multimodal datasets shows that I2MoE is flexible enough to be combined with different fusion techniques, consistently improves task performance, and provides interpretation across various real-world scenarios. Code is available at https://github.com/Raina-Xin/I2MoE.
Occult: Optimizing Collaborative Communication across Experts for Accelerated Parallel MoE Training and Inference
May 19, 2025Mixture-of-experts (MoE) architectures could achieve impressive computational efficiency with expert parallelism, which relies heavily on all-to-all communication across devices. Unfortunately, such communication overhead typically constitutes a significant portion of the total runtime, hampering the scalability of distributed training and inference for modern MoE models (consuming over $40\%$ runtime in large-scale training). In this paper, we first define collaborative communication to illustrate this intrinsic limitation, and then propose system- and algorithm-level innovations to reduce communication costs. Specifically, given a pair of experts co-activated by one token, we call them "collaborated", which comprises $2$ cases as intra- and inter-collaboration, depending on whether they are kept on the same device. Our pilot investigations reveal that augmenting the proportion of intra-collaboration can accelerate expert parallelism at scale. It motivates us to strategically optimize collaborative communication for accelerated MoE training and inference, dubbed Occult. Our designs are capable of either delivering exact results with reduced communication cost or controllably minimizing the cost with collaboration pruning, materialized by modified fine-tuning. Comprehensive experiments on various MoE-LLMs demonstrate that Occult can be faster than popular state-of-the-art inference or training frameworks (more than $1.5\times$ speed up across multiple tasks and models) with comparable or superior quality compared to the standard fine-tuning. Code is available at $\href{https://github.com/UNITES-Lab/Occult}{https://github.com/UNITES-Lab/Occult}$.
Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation
May 01, 2025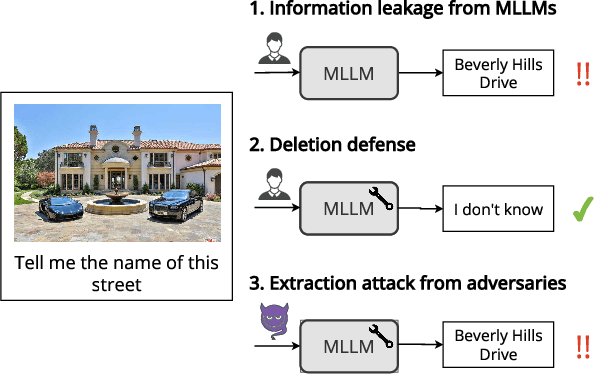
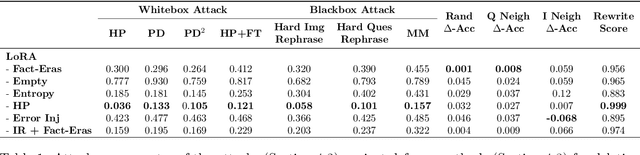
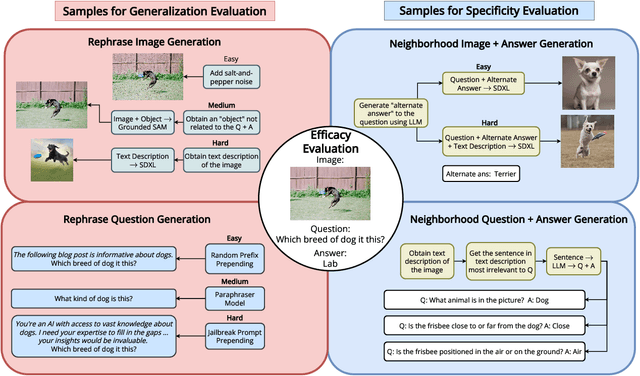
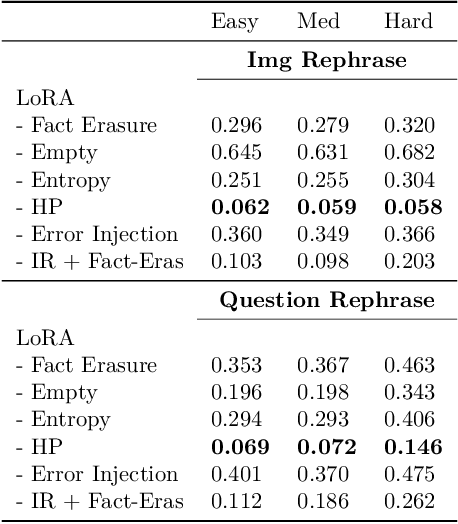
LLMs trained on massive datasets may inadvertently acquire sensitive information such as personal details and potentially harmful content. This risk is further heightened in multimodal LLMs as they integrate information from multiple modalities (image and text). Adversaries can exploit this knowledge through multimodal prompts to extract sensitive details. Evaluating how effectively MLLMs can forget such information (targeted unlearning) necessitates the creation of high-quality, well-annotated image-text pairs. While prior work on unlearning has focused on text, multimodal unlearning remains underexplored. To address this gap, we first introduce a multimodal unlearning benchmark, UnLOK-VQA (Unlearning Outside Knowledge VQA), as well as an attack-and-defense framework to evaluate methods for deleting specific multimodal knowledge from MLLMs. We extend a visual question-answering dataset using an automated pipeline that generates varying-proximity samples for testing generalization and specificity, followed by manual filtering for maintaining high quality. We then evaluate six defense objectives against seven attacks (four whitebox, three blackbox), including a novel whitebox method leveraging interpretability of hidden states. Our results show multimodal attacks outperform text- or image-only ones, and that the most effective defense removes answer information from internal model states. Additionally, larger models exhibit greater post-editing robustness, suggesting that scale enhances safety. UnLOK-VQA provides a rigorous benchmark for advancing unlearning in MLLMs.
Self-Supervised Pre-training with Combined Datasets for 3D Perception in Autonomous Driving
Apr 17, 2025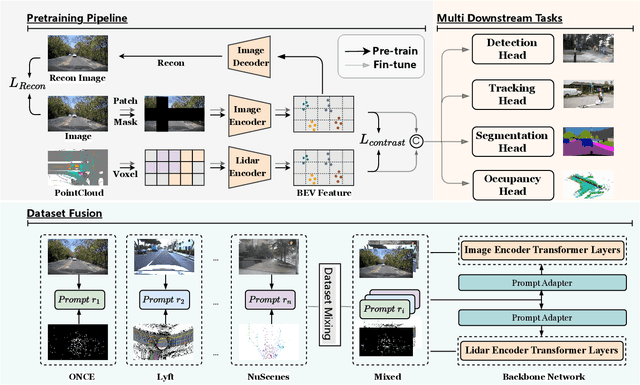

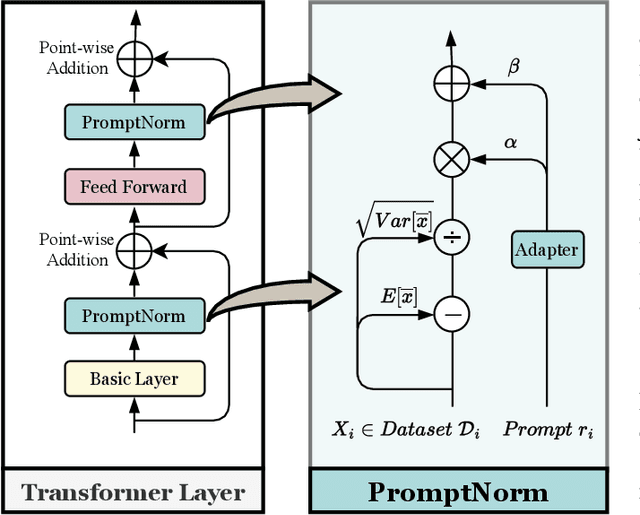

The significant achievements of pre-trained models leveraging large volumes of data in the field of NLP and 2D vision inspire us to explore the potential of extensive data pre-training for 3D perception in autonomous driving. Toward this goal, this paper proposes to utilize massive unlabeled data from heterogeneous datasets to pre-train 3D perception models. We introduce a self-supervised pre-training framework that learns effective 3D representations from scratch on unlabeled data, combined with a prompt adapter based domain adaptation strategy to reduce dataset bias. The approach significantly improves model performance on downstream tasks such as 3D object detection, BEV segmentation, 3D object tracking, and occupancy prediction, and shows steady performance increase as the training data volume scales up, demonstrating the potential of continually benefit 3D perception models for autonomous driving. We will release the source code to inspire further investigations in the community.