 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Generative Solver: Bridging Data-Driven Priors and Conservation Laws for Stable Spatiotemporal Field Reconstruction
May 21, 2026Reconstructing continuous physical fields from sparse measurements is a central inverse problem, but data-driven generative models can produce states that violate governing dynamics. We introduce a physics-informed generative solver that separates stable prior learning from inference-time enforcement of conservation laws. Martingale-Regularized Score Matching regularizes score pretraining with a Score Fokker-Planck constraint, yielding a dynamically stable prior. Physics-Informed Implicit Score Sampling then guides denoising trajectories by gradients of physical residuals, projecting samples toward admissible manifolds without retraining. In acoustics, the method co-generates pressure and particle velocity from sparse sensors, enabling dense virtual arrays that suppress spatial aliasing. The same framework generalizes to real-world ERA5 meteorological fields under extreme sparsity. Together, this work establishes a rigorous and generalizable paradigm for solving high-dimensional inverse problems, bridging the gap between generative artificial intelligence and first-principles science.
Edge-Assisted Multi-Robot Visual-Inertial SLAM with Efficient Communication
Mar 11, 2026The integration of cloud computing and edge computing is an effective way to achieve global consistent and real-time multi-robot Simultaneous Localization and Mapping (SLAM). Cloud computing effectively solves the problem of limited computing, communication and storage capacity of terminal equipment. However, limited bandwidth and extremely long communication links between terminal devices and the cloud result in serious performance degradation of multi-robot SLAM systems. To reduce the computational cost of feature tracking and improve the real-time performance of the robot, a lightweight SLAM method of optical flow tracking based on pyramid IMU prediction is proposed. On this basis, a centralized multi-robot SLAM system based on a robot-edge-cloud layered architecture is proposed to realize real-time collaborative SLAM. It avoids the problems of limited on-board computing resources and low execution efficiency of single robot. In this framework, only the feature points and keyframe descriptors are transmitted and lossless encoding and compression are carried out to realize real-time remote information transmission with limited bandwidth resources. This design reduces the actual bandwidth occupied in the process of data transmission, and does not cause the loss of SLAM accuracy caused by data compression. Through experimental verification on the EuRoC dataset, compared with the current most advanced local feature compression method, our method can achieve lower data volume feature transmission, and compared with the current advanced centralized multi-robot SLAM scheme, it can achieve the same or better positioning accuracy under low computational load.
* 13 pages, 18 figures
Global-Local Dual Perception for MLLMs in High-Resolution Text-Rich Image Translation
Feb 25, 2026Text Image Machine Translation (TIMT) aims to translate text embedded in images in the source-language into target-language, requiring synergistic integration of visual perception and linguistic understanding. Existing TIMT methods, whether cascaded pipelines or end-to-end multimodal large language models (MLLMs),struggle with high-resolution text-rich images due to cluttered layouts, diverse fonts, and non-textual distractions, resulting in text omission, semantic drift, and contextual inconsistency. To address these challenges, we propose GLoTran, a global-local dual visual perception framework for MLLM-based TIMT. GLoTran integrates a low-resolution global image with multi-scale region-level text image slices under an instruction-guided alignment strategy, conditioning MLLMs to maintain scene-level contextual consistency while faithfully capturing fine-grained textual details. Moreover, to realize this dual-perception paradigm, we construct GLoD, a large-scale text-rich TIMT dataset comprising 510K high-resolution global-local image-text pairs covering diverse real-world scenarios. Extensive experiments demonstrate that GLoTran substantially improves translation completeness and accuracy over state-of-the-art MLLMs, offering a new paradigm for fine-grained TIMT under high-resolution and text-rich conditions.
Elo-Evolve: A Co-evolutionary Framework for Language Model Alignment
Feb 14, 2026Current alignment methods for Large Language Models (LLMs) rely on compressing vast amounts of human preference data into static, absolute reward functions, leading to data scarcity, noise sensitivity, and training instability. We introduce Elo-Evolve, a co-evolutionary framework that redefines alignment as dynamic multi-agent competition within an adaptive opponent pool. Our approach makes two key innovations: (1) eliminating Bradley-Terry model dependencies by learning directly from binary win/loss outcomes in pairwise competitions, and (2) implementing Elo-orchestrated opponent selection that provides automatic curriculum learning through temperature-controlled sampling. We ground our approach in PAC learning theory, demonstrating that pairwise comparison achieves superior sample complexity and empirically validate a 4.5x noise reduction compared to absolute scoring approaches. Experimentally, we train a Qwen2.5-7B model using our framework with opponents including Qwen2.5-14B, Qwen2.5-32B, and Qwen3-8B models. Results demonstrate a clear performance hierarchy: point-based methods < static pairwise training < Elo-Evolve across Alpaca Eval 2.0 and MT-Bench, validating the progressive benefits of pairwise comparison and dynamic opponent selection for LLM alignment.
LEMON: How Well Do MLLMs Perform Temporal Multimodal Understanding on Instructional Videos?
Jan 27, 2026Recent multimodal large language models (MLLMs) have shown remarkable progress across vision, audio, and language tasks, yet their performance on long-form, knowledge-intensive, and temporally structured educational content remains largely unexplored. To bridge this gap, we introduce LEMON, a Lecture-based Evaluation benchmark for MultimOdal uNderstanding, focusing on STEM lecture videos that require long-horizon reasoning and cross-modal integration. LEMON comprises 2,277 video segments spanning 5 disciplines and 29 courses, with an average duration of 196.1 seconds, yielding 4,181 high-quality QA pairs, including 3,413 multiple-choice and 768 open-ended questions. Distinct from existing video benchmarks, LEMON features: (1) semantic richness and disciplinary density, (2) tightly coupled video-audio-text modalities, (3) explicit temporal and pedagogical structure, and (4) contextually linked multi-turn questioning. It further encompasses six major tasks and twelve subtasks, covering the full cognitive spectrum from perception to reasoning and then to generation. Comprehensive experiments reveal substantial performance gaps across tasks, highlighting that even state-of-the-art MLLMs like GPT-4o struggle with temporal reasoning and instructional prediction. We expect LEMON to serve as an extensible and challenging benchmark for advancing multimodal perception, reasoning, and generation in long-form instructional contents.
QSMnet-INR: Single-Orientation Quantitative Susceptibility Mapping via Implicit Neural Representation in k-Space
Dec 10, 2025Quantitative Susceptibility Mapping (QSM) quantifies tissue magnetic susceptibility from magnetic-resonance phase data and plays a crucial role in brain microstructure imaging, iron-deposition assessment, and neurological-disease research. However, single-orientation QSM inversion remains highly ill-posed because the dipole kernel exhibits a cone-null region in the Fourier domain, leading to streaking artifacts and structural loss. To overcome this limitation, we propose QSMnet-INR, a deep, physics-informed framework that integrates an Implicit Neural Representation (INR) into the k-space domain. The INR module continuously models multi-directional dipole responses and explicitly completes the cone-null region, while a frequency-domain residual-weighted Dipole Loss enforces physical consistency. The overall network combines a 3D U-Net-based QSMnet backbone with the INR module through alternating optimization for end-to-end joint training. Experiments on the 2016 QSM Reconstruction Challenge, a multi-orientation GRE dataset, and both in-house and public single-orientation clinical data demonstrate that QSMnet-INR consistently outperforms conventional and recent deep-learning approaches across multiple quantitative metrics. The proposed framework shows notable advantages in structural recovery within cone-null regions and in artifact suppression. Ablation studies further confirm the complementary contributions of the INR module and Dipole Loss to detail preservation and physical stability. Overall, QSMnet-INR effectively alleviates the ill-posedness of single-orientation QSM without requiring multi-orientation acquisition, achieving high accuracy, robustness, and strong cross-scenario generalization-highlighting its potential for clinical translation.
ClinicalTrialsHub: Bridging Registries and Literature for Comprehensive Clinical Trial Access
Dec 09, 2025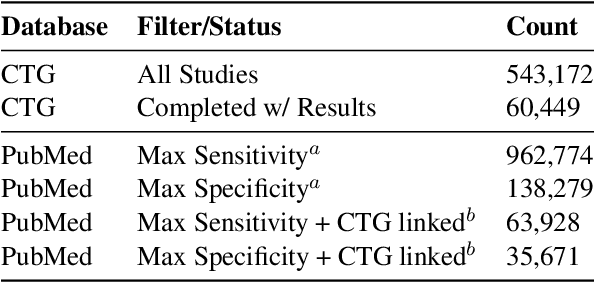
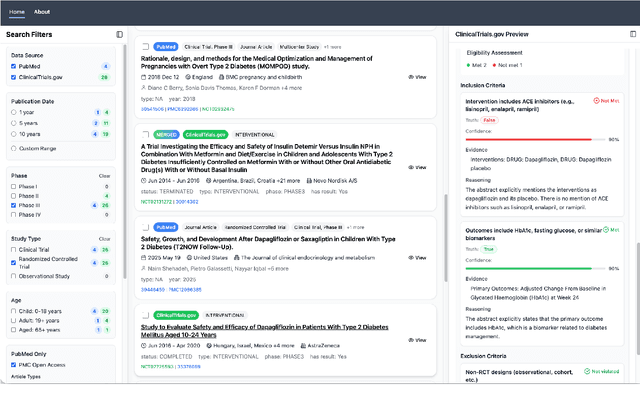
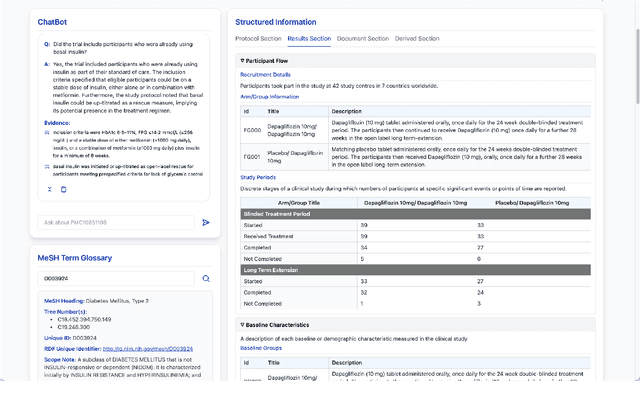

We present ClinicalTrialsHub, an interactive search-focused platform that consolidates all data from ClinicalTrials.gov and augments it by automatically extracting and structuring trial-relevant information from PubMed research articles. Our system effectively increases access to structured clinical trial data by 83.8% compared to relying on ClinicalTrials.gov alone, with potential to make access easier for patients, clinicians, researchers, and policymakers, advancing evidence-based medicine. ClinicalTrialsHub uses large language models such as GPT-5.1 and Gemini-3-Pro to enhance accessibility. The platform automatically parses full-text research articles to extract structured trial information, translates user queries into structured database searches, and provides an attributed question-answering system that generates evidence-grounded answers linked to specific source sentences. We demonstrate its utility through a user study involving clinicians, clinical researchers, and PhD students of pharmaceutical sciences and nursing, and a systematic automatic evaluation of its information extraction and question answering capabilities.
BeyondFacial: Identity-Preserving Personalized Generation Beyond Facial Close-ups
Nov 15, 2025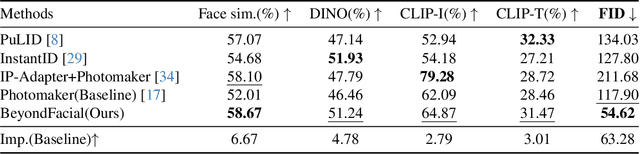
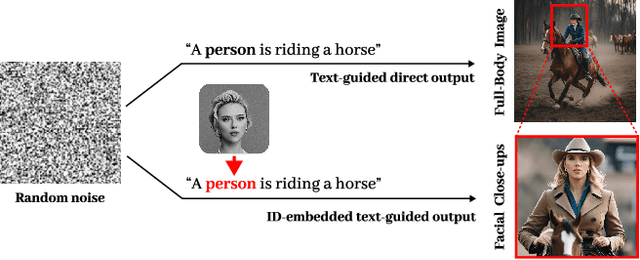
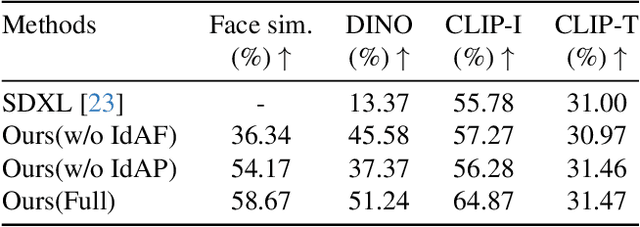
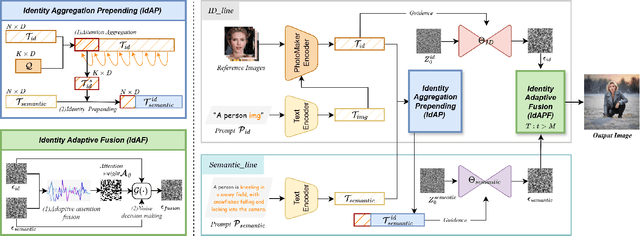
Identity-Preserving Personalized Generation (IPPG) has advanced film production and artistic creation, yet existing approaches overemphasize facial regions, resulting in outputs dominated by facial close-ups.These methods suffer from weak visual narrativity and poor semantic consistency under complex text prompts, with the core limitation rooted in identity (ID) feature embeddings undermining the semantic expressiveness of generative models. To address these issues, this paper presents an IPPG method that breaks the constraint of facial close-ups, achieving synergistic optimization of identity fidelity and scene semantic creation. Specifically, we design a Dual-Line Inference (DLI) pipeline with identity-semantic separation, resolving the representation conflict between ID and semantics inherent in traditional single-path architectures. Further, we propose an Identity Adaptive Fusion (IdAF) strategy that defers ID-semantic fusion to the noise prediction stage, integrating adaptive attention fusion and noise decision masking to avoid ID embedding interference on semantics without manual masking. Finally, an Identity Aggregation Prepending (IdAP) module is introduced to aggregate ID information and replace random initializations, further enhancing identity preservation. Experimental results validate that our method achieves stable and effective performance in IPPG tasks beyond facial close-ups, enabling efficient generation without manual masking or fine-tuning. As a plug-and-play component, it can be rapidly deployed in existing IPPG frameworks, addressing the over-reliance on facial close-ups, facilitating film-level character-scene creation, and providing richer personalized generation capabilities for related domains.
Relative-Absolute Fusion: Rethinking Feature Extraction in Image-Based Iterative Method Selection for Solving Sparse Linear Systems
Oct 01, 2025Iterative method selection is crucial for solving sparse linear systems because these methods inherently lack robustness. Though image-based selection approaches have shown promise, their feature extraction techniques might encode distinct matrices into identical image representations, leading to the same selection and suboptimal method. In this paper, we introduce RAF (Relative-Absolute Fusion), an efficient feature extraction technique to enhance image-based selection approaches. By simultaneously extracting and fusing image representations as relative features with corresponding numerical values as absolute features, RAF achieves comprehensive matrix representations that prevent feature ambiguity across distinct matrices, thus improving selection accuracy and unlocking the potential of image-based selection approaches. We conducted comprehensive evaluations of RAF on SuiteSparse and our developed BMCMat (Balanced Multi-Classification Matrix dataset), demonstrating solution time reductions of 0.08s-0.29s for sparse linear systems, which is 5.86%-11.50% faster than conventional image-based selection approaches and achieves state-of-the-art (SOTA) performance. BMCMat is available at https://github.com/zkqq/BMCMat.
Circumventing Backdoor Space via Weight Symmetry
Jun 09, 2025Deep neural networks are vulnerable to backdoor attacks, where malicious behaviors are implanted during training. While existing defenses can effectively purify compromised models, they typically require labeled data or specific training procedures, making them difficult to apply beyond supervised learning settings. Notably, recent studies have shown successful backdoor attacks across various learning paradigms, highlighting a critical security concern. To address this gap, we propose Two-stage Symmetry Connectivity (TSC), a novel backdoor purification defense that operates independently of data format and requires only a small fraction of clean samples. Through theoretical analysis, we prove that by leveraging permutation invariance in neural networks and quadratic mode connectivity, TSC amplifies the loss on poisoned samples while maintaining bounded clean accuracy. Experiments demonstrate that TSC achieves robust performance comparable to state-of-the-art methods in supervised learning scenarios. Furthermore, TSC generalizes to self-supervised learning frameworks, such as SimCLR and CLIP, maintaining its strong defense capabilities. Our code is available at https://github.com/JiePeng104/TSC.