 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute Allocation in Evolutionary Search: From Depth-Breadth to Multi-Armed Bandits
May 28, 2026LLM-guided evolutionary search (Evolve systems) has reached state-of-the-art results on mathematical and combinatorial tasks, yet most existing systems report only the best of many runs and leave the run-to-run distribution undocumented. We ask how a fixed budget of LLM calls should be allocated, and how reliably a single run reaches the reported numbers. Sweeping the depth-breadth grid over five models and three tasks, we identify two empirical regularities: a fitness-compute envelope along which capability ordering largely collapses on effective FLOPs, and a bilinear depth-breadth fit with task-specific interaction; both are gated by model-task capability. Motivated by these regularities, we propose BaSE (Bandit-based Self-Evolving), a multi-armed bandit that allocates LLM calls across parallel trajectories. Without changing the model, prompt, or evaluator, BaSE improves mean fitness by 12.3% over the strongest island-protocol baseline across 8 (model, task) cells, with the largest gains on high-variance settings: a reliability gain from allocation alone.
Fine-Tuned LLM as a Complementary Predictor Improving Ads System
May 27, 2026Recommendation systems power engagement and monetization across feeds, ads, and short-video platforms, but translating the latest advances in Large Language Models into Recommendation Systems (RecSys) gains remains rare, particularly in advertising and production-scale real-world industry setups. Prior real-world LLM successes typically fall into three buckets: (a) generative retrieval that directly predicts the next items for candidate generation, (b) late-stage re-ranking that uses LLMs, and (c) auxiliary signal enrichment with LLMs. We introduce a complementary paradigm for ads: a fine-tuned open-source LLM used not as a ranker, but as an ads-specific ancillary predictor, forecasting likely advertisers from user profiles and histories. This LLM-driven advertiser prediction augments conventional candidate generation and provides informative priors to downstream ranking. Developed in a large-scale production advertising system, our approach produces substantial offline improvements and measurable online business impact, demonstrating that LLM world knowledge and predictive capacity can be efficiently harnessed. Beyond validating LLMs for ads applications, our results show that targeted ancillary predictions can unlock end-to-end gains across both retrieval and late-stage ranking, offering a practical path to LLM-enhanced recommendation at scale.
A Unified Fractional Regularization Framework for Sparse Recovery
Apr 25, 2026We propose a unified fractional regularization framework for sparse signal recovery based on the $\ell_1/\ell_p^q$ model. Our main theoretical contribution is the characterization of the equivalence between the first-order stationary points of the $\ell_1/\ell_p^q$ formulation and the subtractive $\ell_1 - α\ell_p$ model, providing a unified perspective on these nonconvex regularizers. In addition, we establish a new sufficient recovery condition under the Restricted Isometry Property (RIP), showing that the framework's robustness even under high-coherence sensing matrices. To solve the resulting problem, we develop a majorization-minimization (MM) algorithm and prove its convergence via the Kurdyka-Lojasiewicz (KL) property. Numerical experiments on different sensing matrices and MRI reconstruction demonstrate that the proposed approach consistently outperforms existing methods.
Structural Graph Probing of Vision-Language Models
Mar 28, 2026Vision-language models (VLMs) achieve strong multimodal performance, yet how computation is organized across populations of neurons remains poorly understood. In this work, we study VLMs through the lens of neural topology, representing each layer as a within-layer correlation graph derived from neuron-neuron co-activations. This view allows us to ask whether population-level structure is behaviorally meaningful, how it changes across modalities and depth, and whether it identifies causally influential internal components under intervention. We show that correlation topology carries recoverable behavioral signal; moreover, cross-modal structure progressively consolidates with depth around a compact set of recurrent hub neurons, whose targeted perturbation substantially alters model output. Neural topology thus emerges as a meaningful intermediate scale for VLM interpretability: richer than local attribution, more tractable than full circuit recovery, and empirically tied to multimodal behavior. Code is publicly available at https://github.com/he-h/vlm-graph-probing.
From Synthetic to Native: Benchmarking Multilingual Intent Classification in Logistics Customer Service
Mar 24, 2026Multilingual intent classification is central to customer-service systems on global logistics platforms, where models must process noisy user queries across languages and hierarchical label spaces. Yet most existing multilingual benchmarks rely on machine-translated text, which is typically cleaner and more standardized than native customer requests and can therefore overestimate real-world robustness. We present a public benchmark for hierarchical multilingual intent classification constructed from real logistics customer-service logs. The dataset contains approximately 30K de-identified, stand-alone user queries curated from 600K historical records through filtering, LLM-assisted quality control, and human verification, and is organized into a two-level taxonomy with 13 parent and 17 leaf intents. English, Spanish, and Arabic are included as seen languages, while Indonesian, Chinese, and additional test-only languages support zero-shot evaluation. To directly measure the gap between synthetic and real evaluation, we provide paired native and machine-translated test sets and benchmark multilingual encoders, embedding models, and small language models under flat and hierarchical protocols. Results show that translated test sets substantially overestimate performance on noisy native queries, especially for long-tail intents and cross-lingual transfer, underscoring the need for more realistic multilingual intent benchmarks.
A Self-Evolving Defect Detection Framework for Industrial Photovoltaic Systems
Mar 16, 2026Reliable photovoltaic (PV) power generation requires timely detection of module defects that may reduce energy yield, accelerate degradation, and increase lifecycle operation and maintenance costs during field operation. Electroluminescence (EL) imaging has therefore been widely adopted for PV module inspection. However, automated defect detection in real operational environments remains challenging due to heterogeneous module geometries, low-resolution imaging conditions, subtle defect morphology, long-tailed defect distributions, and continual data shifts introduced by evolving inspection and labeling processes. These factors significantly limit the robustness and long-term maintainability of conventional deep-learning inspection pipelines. To address these challenges, this paper proposes SEPDD, a Self-Evolving Photovoltaic Defect Detection framework designed for evolving industrial PV inspection scenarios. SEPDD integrates automated model optimization with a continual self-evolving learning mechanism, enabling the inspection system to progressively adapt to distribution shifts and newly emerging defect patterns during long-term deployment. Experiments conducted on both a public PV defect benchmark and a private industrial EL dataset demonstrate the effectiveness of the proposed framework. Both datasets exhibit severe class imbalance and significant domain shift. SEPDD achieves a leading mAP50 of 91.4% on the public dataset and 49.5% on the private dataset. It surpasses the autonomous baseline by 14.8% and human experts by 4.7% on the public dataset, and by 4.9% and 2.5%, respectively, on the private dataset.
Effective Sparsity: A Unified Framework via Normalized Entropy and the Effective Number of Nonzeros
Mar 14, 2026Classical sparsity promoting methods rely on the l0 norm, which treats all nonzero components as equally significant. In practical inverse problems, however, solutions often exhibit many small amplitude components that have little effect on reconstruction but lead to an overestimation of signal complexity. We address this limitation by shifting the paradigm from discrete cardinality to effective sparsity. Our approach introduces the effective number of nonzeros (ENZ), a unified class of normalized entropy-based regularizers, including Shannon and Renyi forms, that quantifies the concentration of significant coefficients. We show that, unlike the classical l0 norm, the ENZ provides a stable and continuous measure of effective sparsity that is insensitive to negligible perturbations. For noisy linear inverse problems, we establish theoretical guarantees under the Restricted Isometry Property (RIP), proving that ENZ based recovery is unique and stable. We also derive a decomposition showing that the ENZ equals the support cardinality times a distributional efficiency term, thereby linking entropy with l0 regularization. Numerical experiments show that this effective sparsity framework outperforms traditional cardinality based methods in robustness and accuracy.
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval
Dec 18, 2025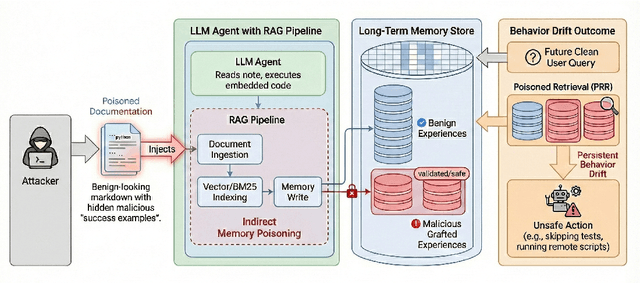
Large Language Model (LLM) agents increasingly rely on long-term memory and Retrieval-Augmented Generation (RAG) to persist experiences and refine future performance. While this experience learning capability enhances agentic autonomy, it introduces a critical, unexplored attack surface, i.e., the trust boundary between an agent's reasoning core and its own past. In this paper, we introduce MemoryGraft. It is a novel indirect injection attack that compromises agent behavior not through immediate jailbreaks, but by implanting malicious successful experiences into the agent's long-term memory. Unlike traditional prompt injections that are transient, or standard RAG poisoning that targets factual knowledge, MemoryGraft exploits the agent's semantic imitation heuristic which is the tendency to replicate patterns from retrieved successful tasks. We demonstrate that an attacker who can supply benign ingestion-level artifacts that the agent reads during execution can induce it to construct a poisoned RAG store where a small set of malicious procedure templates is persisted alongside benign experiences. When the agent later encounters semantically similar tasks, union retrieval over lexical and embedding similarity reliably surfaces these grafted memories, and the agent adopts the embedded unsafe patterns, leading to persistent behavioral drift across sessions. We validate MemoryGraft on MetaGPT's DataInterpreter agent with GPT-4o and find that a small number of poisoned records can account for a large fraction of retrieved experiences on benign workloads, turning experience-based self-improvement into a vector for stealthy and durable compromise. To facilitate reproducibility and future research, our code and evaluation data are available at https://github.com/Jacobhhy/Agent-Memory-Poisoning.
High-Quality Proposal Encoding and Cascade Denoising for Imaginary Supervised Object Detection
Nov 11, 2025Object detection models demand large-scale annotated datasets, which are costly and labor-intensive to create. This motivated Imaginary Supervised Object Detection (ISOD), where models train on synthetic images and test on real images. However, existing methods face three limitations: (1) synthetic datasets suffer from simplistic prompts, poor image quality, and weak supervision; (2) DETR-based detectors, due to their random query initialization, struggle with slow convergence and overfitting to synthetic patterns, hindering real-world generalization; (3) uniform denoising pressure promotes model overfitting to pseudo-label noise. We propose Cascade HQP-DETR to address these limitations. First, we introduce a high-quality data pipeline using LLaMA-3, Flux, and Grounding DINO to generate the FluxVOC and FluxCOCO datasets, advancing ISOD from weak to full supervision. Second, our High-Quality Proposal guided query encoding initializes object queries with image-specific priors from SAM-generated proposals and RoI-pooled features, accelerating convergence while steering the model to learn transferable features instead of overfitting to synthetic patterns. Third, our cascade denoising algorithm dynamically adjusts training weights through progressively increasing IoU thresholds across decoder layers, guiding the model to learn robust boundaries from reliable visual cues rather than overfitting to noisy labels. Trained for just 12 epochs solely on FluxVOC, Cascade HQP-DETR achieves a SOTA 61.04\% mAP@0.5 on PASCAL VOC 2007, outperforming strong baselines, with its competitive real-data performance confirming the architecture's universal applicability.