 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Q-Mix: Selecting the Right Action for LLM Multi-Agent Systems through Reinforcement Learning
Apr 01, 2026Large Language Models (LLMs) have shown remarkable performance in completing various tasks. However, solving complex problems often requires the coordination of multiple agents, raising a fundamental question: how to effectively select and interconnect these agents. In this paper, we propose \textbf{Agent Q-Mix}, a reinforcement learning framework that reformulates topology selection as a cooperative Multi-Agent Reinforcement Learning (MARL) problem. Our method learns decentralized communication decisions using QMIX value factorization, where each agent selects from a set of communication actions that jointly induce a round-wise communication graph. At its core, Agent Q-Mix combines a topology-aware GNN encoder, GRU memory, and per-agent Q-heads under a Centralized Training with Decentralized Execution (CTDE) paradigm. The framework optimizes a reward function that balances task accuracy with token cost. Across seven core benchmarks in coding, reasoning, and mathematics, Agent Q-Mix achieves the highest average accuracy compared to existing methods while demonstrating superior token efficiency and robustness against agent failure. Notably, on the challenging Humanity's Last Exam (HLE) using Gemini-3.1-Flash-Lite as a backbone, Agent Q-Mix achieves 20.8\% accuracy, outperforming Microsoft Agent Framework (19.2\%) and LangGraph (19.2\%), followed by AutoGen and Lobster by OpenClaw. These results underscore the effectiveness of learned, decentralized topology optimization in pushing the boundaries of multi-agent reasoning.
Contrastive Reasoning Alignment: Reinforcement Learning from Hidden Representations
Mar 18, 2026We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representation learning with reinforcement learning to separate safe and unsafe reasoning trajectories, yielding a latent-space geometry that supports robust, reasoning-level safety alignment. Theoretically, we show that incorporating latent-textual consistency into GRPO eliminates superficially aligned policies by ruling them out as local optima. Empirically, we evaluate CRAFT on multiple safety benchmarks using two strong reasoning models, Qwen3-4B-Thinking and R1-Distill-Llama-8B, where it consistently outperforms state-of-the-art defenses such as IPO and SafeKey. Notably, CRAFT delivers an average 79.0% improvement in reasoning safety and 87.7% improvement in final-response safety over the base models, demonstrating the effectiveness of hidden-space reasoning alignment.
FROST: Filtering Reasoning Outliers with Attention for Efficient Reasoning
Jan 26, 2026We propose FROST, an attention-aware method for efficient reasoning. Unlike traditional approaches, FROST leverages attention weights to prune uncritical reasoning paths, yielding shorter and more reliable reasoning trajectories. Methodologically, we introduce the concept of reasoning outliers and design an attention-based mechanism to remove them. Theoretically, FROST preserves and enhances the model's reasoning capacity while eliminating outliers at the sentence level. Empirically, we validate FROST on four benchmarks using two strong reasoning models (Phi-4-Reasoning and GPT-OSS-20B), outperforming state-of-the-art methods such as TALE and ThinkLess. Notably, FROST achieves an average 69.68% reduction in token usage and a 26.70% improvement in accuracy over the base model. Furthermore, in evaluations of attention outlier metrics, FROST reduces the maximum infinity norm by 15.97% and the average kurtosis by 91.09% compared to the base model. Code is available at https://github.com/robinzixuan/FROST
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025



LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
GenoArmory: A Unified Evaluation Framework for Adversarial Attacks on Genomic Foundation Models
May 16, 2025

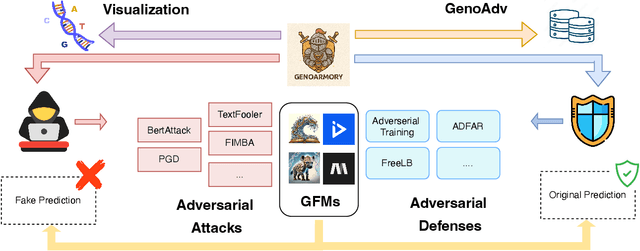

We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GenoArmory. Unlike existing GFM benchmarks, GenoArmory offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Additionally, we introduce GenoAdv, a new adversarial sample dataset designed to improve GFM safety. Empirically, classification models exhibit greater robustness to adversarial perturbations compared to generative models, highlighting the impact of task type on model vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
Fast and Low-Cost Genomic Foundation Models via Outlier Removal
May 01, 2025We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GERM. Unlike existing GFM benchmarks, GERM offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Empirically, transformer-based models exhibit greater robustness to adversarial perturbations compared to HyenaDNA, highlighting the impact of architectural design on vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
ST-MoE-BERT: A Spatial-Temporal Mixture-of-Experts Framework for Long-Term Cross-City Mobility Prediction
Oct 18, 2024



Predicting human mobility across multiple cities presents significant challenges due to the complex and diverse spatial-temporal dynamics inherent in different urban environments. In this study, we propose a robust approach to predict human mobility patterns called ST-MoE-BERT. Compared to existing methods, our approach frames the prediction task as a spatial-temporal classification problem. Our methodology integrates the Mixture-of-Experts architecture with BERT model to capture complex mobility dynamics and perform the downstream human mobility prediction task. Additionally, transfer learning is integrated to solve the challenge of data scarcity in cross-city prediction. We demonstrate the effectiveness of the proposed model on GEO-BLEU and DTW, comparing it to several state-of-the-art methods. Notably, ST-MoE-BERT achieves an average improvement of 8.29%.
Decoupled Alignment for Robust Plug-and-Play Adaptation
Jun 04, 2024
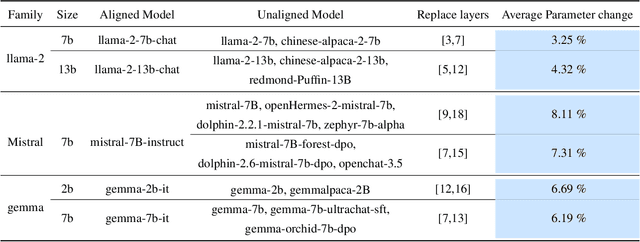
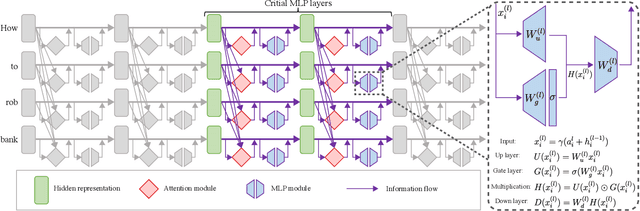
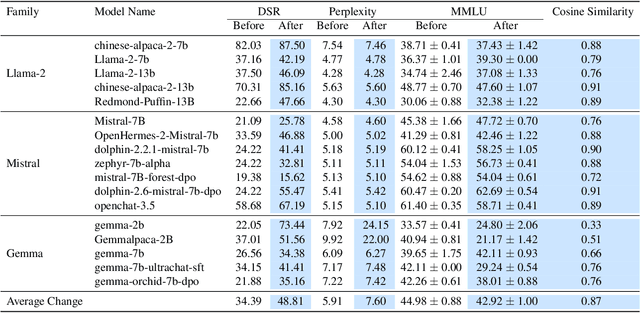
We introduce a low-resource safety enhancement method for aligning large language models (LLMs) without the need for supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF). Our main idea is to exploit knowledge distillation to extract the alignment information from existing well-aligned LLMs and integrate it into unaligned LLMs in a plug-and-play fashion. Methodology, we employ delta debugging to identify the critical components of knowledge necessary for effective distillation. On the harmful question dataset, our method significantly enhances the average defense success rate by approximately 14.41%, reaching as high as 51.39%, in 17 unaligned pre-trained LLMs, without compromising performance.