 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
Protego: Detecting Adversarial Examples for Vision Transformers via Intrinsic Capabilities
Jan 13, 2025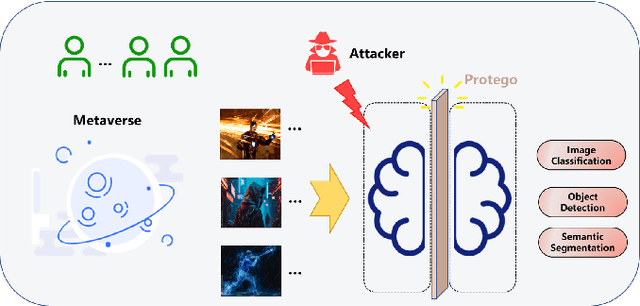
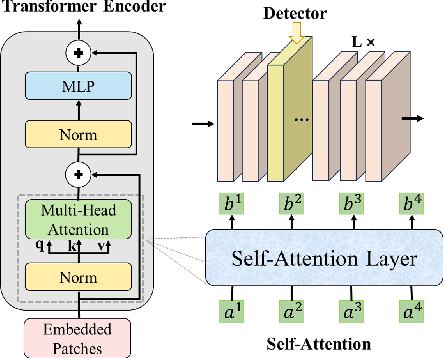
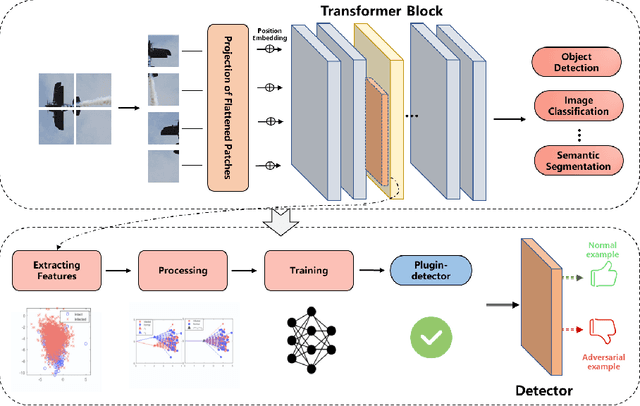
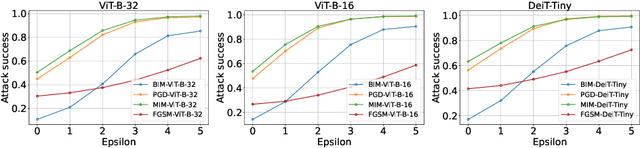
Transformer models have excelled in natural language tasks, prompting the vision community to explore their implementation in computer vision problems. However, these models are still influenced by adversarial examples. In this paper, we investigate the attack capabilities of six common adversarial attacks on three pretrained ViT models to reveal the vulnerability of ViT models. To understand and analyse the bias in neural network decisions when the input is adversarial, we use two visualisation techniques that are attention rollout and grad attention rollout. To prevent ViT models from adversarial attack, we propose Protego, a detection framework that leverages the transformer intrinsic capabilities to detection adversarial examples of ViT models. Nonetheless, this is challenging due to a diversity of attack strategies that may be adopted by adversaries. Inspired by the attention mechanism, we know that the token of prediction contains all the information from the input sample. Additionally, the attention region for adversarial examples differs from that of normal examples. Given these points, we can train a detector that achieves superior performance than existing detection methods to identify adversarial examples. Our experiments have demonstrated the high effectiveness of our detection method. For these six adversarial attack methods, our detector's AUC scores all exceed 0.95. Protego may advance investigations in metaverse security.
Legilimens: Practical and Unified Content Moderation for Large Language Model Services
Sep 05, 2024
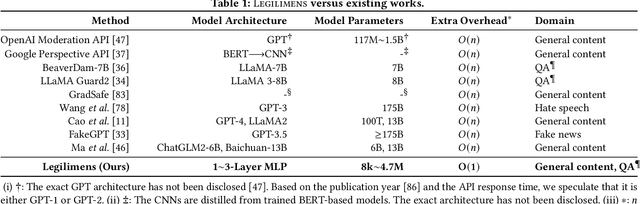
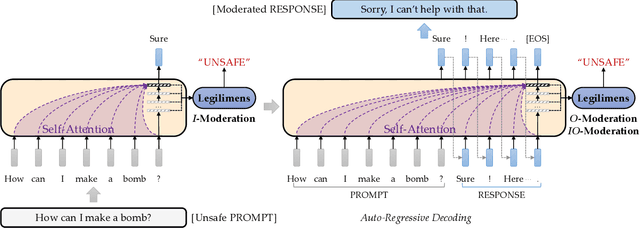
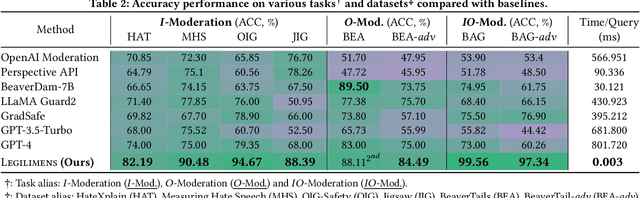
Given the societal impact of unsafe content generated by large language models (LLMs), ensuring that LLM services comply with safety standards is a crucial concern for LLM service providers. Common content moderation methods are limited by an effectiveness-and-efficiency dilemma, where simple models are fragile while sophisticated models consume excessive computational resources. In this paper, we reveal for the first time that effective and efficient content moderation can be achieved by extracting conceptual features from chat-oriented LLMs, despite their initial fine-tuning for conversation rather than content moderation. We propose a practical and unified content moderation framework for LLM services, named Legilimens, which features both effectiveness and efficiency. Our red-team model-based data augmentation enhances the robustness of Legilimens against state-of-the-art jailbreaking. Additionally, we develop a framework to theoretically analyze the cost-effectiveness of Legilimens compared to other methods. We have conducted extensive experiments on five host LLMs, seventeen datasets, and nine jailbreaking methods to verify the effectiveness, efficiency, and robustness of Legilimens against normal and adaptive adversaries. A comparison of Legilimens with both commercial and academic baselines demonstrates the superior performance of Legilimens. Furthermore, we confirm that Legilimens can be applied to few-shot scenarios and extended to multi-label classification tasks.
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
Apr 19, 2024



Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.