 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRACONTEUR: A Knowledgeable, Insightful, and Portable LLM-Powered Shell Command Explainer
Sep 03, 2024



Malicious shell commands are linchpins to many cyber-attacks, but may not be easy to understand by security analysts due to complicated and often disguised code structures. Advances in large language models (LLMs) have unlocked the possibility of generating understandable explanations for shell commands. However, existing general-purpose LLMs suffer from a lack of expert knowledge and a tendency to hallucinate in the task of shell command explanation. In this paper, we present Raconteur, a knowledgeable, expressive and portable shell command explainer powered by LLM. Raconteur is infused with professional knowledge to provide comprehensive explanations on shell commands, including not only what the command does (i.e., behavior) but also why the command does it (i.e., purpose). To shed light on the high-level intent of the command, we also translate the natural-language-based explanation into standard technique & tactic defined by MITRE ATT&CK, the worldwide knowledge base of cybersecurity. To enable Raconteur to explain unseen private commands, we further develop a documentation retriever to obtain relevant information from complementary documentations to assist the explanation process. We have created a large-scale dataset for training and conducted extensive experiments to evaluate the capability of Raconteur in shell command explanation. The experiments verify that Raconteur is able to provide high-quality explanations and in-depth insight of the intent of the command.
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
Apr 19, 2024



Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.
FakeWake: Understanding and Mitigating Fake Wake-up Words of Voice Assistants
Sep 21, 2021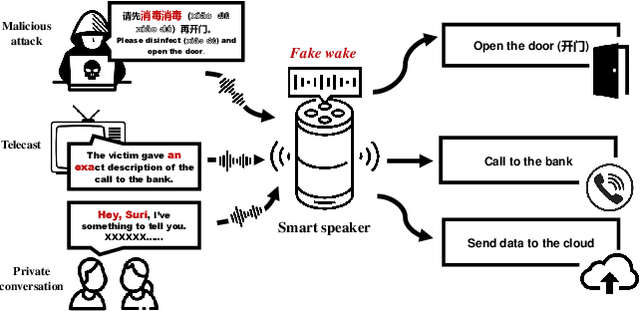
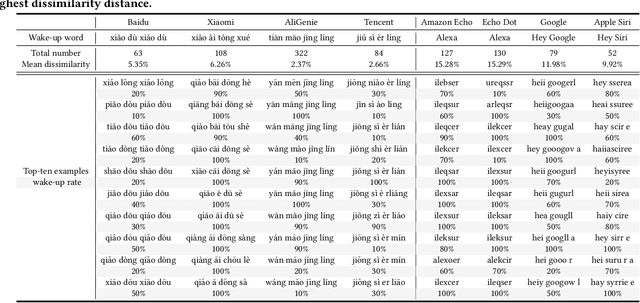
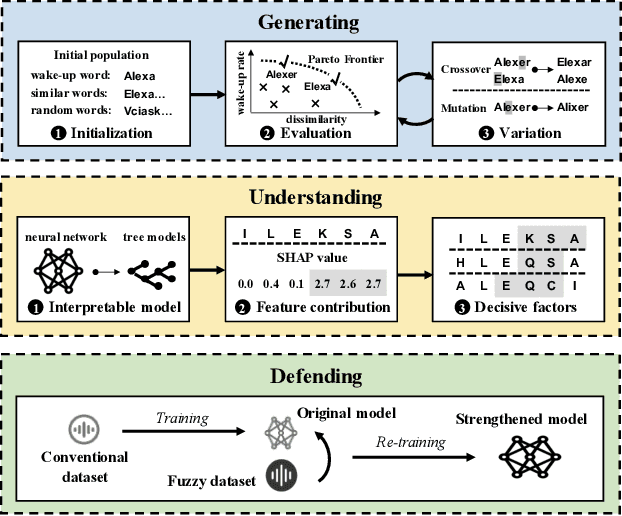

In the area of Internet of Things (IoT) voice assistants have become an important interface to operate smart speakers, smartphones, and even automobiles. To save power and protect user privacy, voice assistants send commands to the cloud only if a small set of pre-registered wake-up words are detected. However, voice assistants are shown to be vulnerable to the FakeWake phenomena, whereby they are inadvertently triggered by innocent-sounding fuzzy words. In this paper, we present a systematic investigation of the FakeWake phenomena from three aspects. To start with, we design the first fuzzy word generator to automatically and efficiently produce fuzzy words instead of searching through a swarm of audio materials. We manage to generate 965 fuzzy words covering 8 most popular English and Chinese smart speakers. To explain the causes underlying the FakeWake phenomena, we construct an interpretable tree-based decision model, which reveals phonetic features that contribute to false acceptance of fuzzy words by wake-up word detectors. Finally, we propose remedies to mitigate the effect of FakeWake. The results show that the strengthened models are not only resilient to fuzzy words but also achieve better overall performance on original training datasets.