 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Bi-Directional Model Steering via Distribution Matching and Distributed Interchange Interventions
Feb 05, 2026Intervention-based model steering offers a lightweight and interpretable alternative to prompting and fine-tuning. However, by adapting strong optimization objectives from fine-tuning, current methods are susceptible to overfitting and often underperform, sometimes generating unnatural outputs. We hypothesize that this is because effective steering requires the faithful identification of internal model mechanisms, not the enforcement of external preferences. To this end, we build on the principles of distributed alignment search (DAS), the standard for causal variable localization, to propose a new steering method: Concept DAS (CDAS). While we adopt the core mechanism of DAS, distributed interchange intervention (DII), we introduce a novel distribution matching objective tailored for the steering task by aligning intervened output distributions with counterfactual distributions. CDAS differs from prior work in two main ways: first, it learns interventions via weak-supervised distribution matching rather than probability maximization; second, it uses DIIs that naturally enable bi-directional steering and allow steering factors to be derived from data, reducing the effort required for hyperparameter tuning and resulting in more faithful and stable control. On AxBench, a large-scale model steering benchmark, we show that CDAS does not always outperform preference-optimization methods but may benefit more from increased model scale. In two safety-related case studies, overriding refusal behaviors of safety-aligned models and neutralizing a chain-of-thought backdoor, CDAS achieves systematic steering while maintaining general model utility. These results indicate that CDAS is complementary to preference-optimization approaches and conditionally constitutes a robust approach to intervention-based model steering. Our code is available at https://github.com/colored-dye/concept_das.
RACONTEUR: A Knowledgeable, Insightful, and Portable LLM-Powered Shell Command Explainer
Sep 03, 2024



Malicious shell commands are linchpins to many cyber-attacks, but may not be easy to understand by security analysts due to complicated and often disguised code structures. Advances in large language models (LLMs) have unlocked the possibility of generating understandable explanations for shell commands. However, existing general-purpose LLMs suffer from a lack of expert knowledge and a tendency to hallucinate in the task of shell command explanation. In this paper, we present Raconteur, a knowledgeable, expressive and portable shell command explainer powered by LLM. Raconteur is infused with professional knowledge to provide comprehensive explanations on shell commands, including not only what the command does (i.e., behavior) but also why the command does it (i.e., purpose). To shed light on the high-level intent of the command, we also translate the natural-language-based explanation into standard technique & tactic defined by MITRE ATT&CK, the worldwide knowledge base of cybersecurity. To enable Raconteur to explain unseen private commands, we further develop a documentation retriever to obtain relevant information from complementary documentations to assist the explanation process. We have created a large-scale dataset for training and conducted extensive experiments to evaluate the capability of Raconteur in shell command explanation. The experiments verify that Raconteur is able to provide high-quality explanations and in-depth insight of the intent of the command.
Course-Correction: Safety Alignment Using Synthetic Preferences
Jul 23, 2024
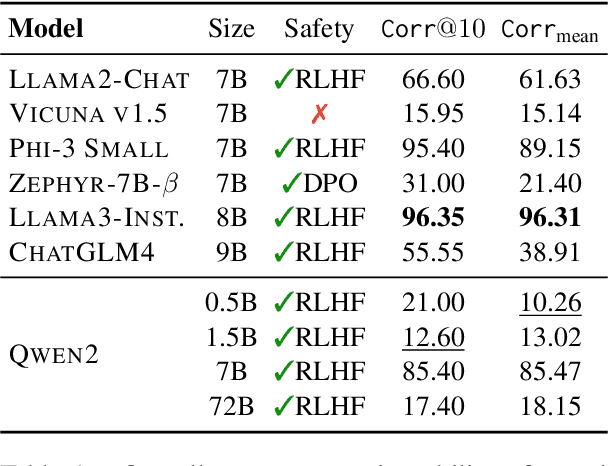

The risk of harmful content generated by large language models (LLMs) becomes a critical concern. This paper presents a systematic study on assessing and improving LLMs' capability to perform the task of \textbf{course-correction}, \ie, the model can steer away from generating harmful content autonomously. To start with, we introduce the \textsc{C$^2$-Eval} benchmark for quantitative assessment and analyze 10 popular LLMs, revealing varying proficiency of current safety-tuned LLMs in course-correction. To improve, we propose fine-tuning LLMs with preference learning, emphasizing the preference for timely course-correction. Using an automated pipeline, we create \textsc{C$^2$-Syn}, a synthetic dataset with 750K pairwise preferences, to teach models the concept of timely course-correction through data-driven preference learning. Experiments on 2 LLMs, \textsc{Llama2-Chat 7B} and \textsc{Qwen2 7B}, show that our method effectively enhances course-correction skills without affecting general performance. Additionally, it effectively improves LLMs' safety, particularly in resisting jailbreak attacks.
SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models
Apr 19, 2024



Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.
A Survey of Privacy Threats and Defense in Vertical Federated Learning: From Model Life Cycle Perspective
Feb 06, 2024Vertical Federated Learning (VFL) is a federated learning paradigm where multiple participants, who share the same set of samples but hold different features, jointly train machine learning models. Although VFL enables collaborative machine learning without sharing raw data, it is still susceptible to various privacy threats. In this paper, we conduct the first comprehensive survey of the state-of-the-art in privacy attacks and defenses in VFL. We provide taxonomies for both attacks and defenses, based on their characterizations, and discuss open challenges and future research directions. Specifically, our discussion is structured around the model's life cycle, by delving into the privacy threats encountered during different stages of machine learning and their corresponding countermeasures. This survey not only serves as a resource for the research community but also offers clear guidance and actionable insights for practitioners to safeguard data privacy throughout the model's life cycle.
How ChatGPT is Solving Vulnerability Management Problem
Nov 11, 2023
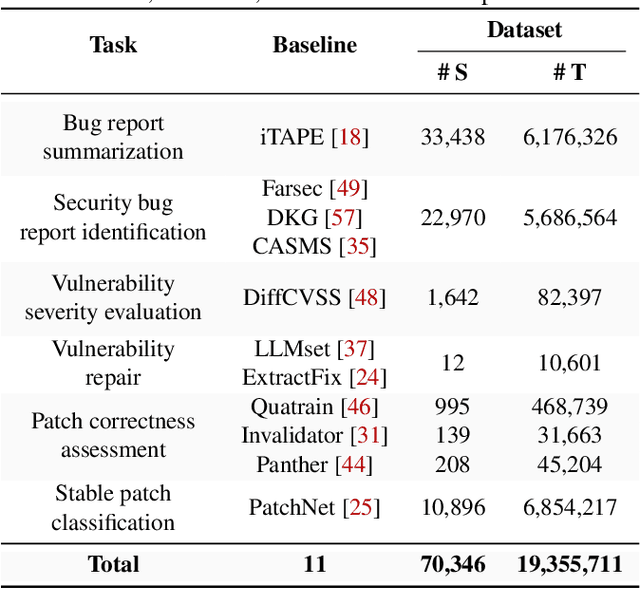


Recently, ChatGPT has attracted great attention from the code analysis domain. Prior works show that ChatGPT has the capabilities of processing foundational code analysis tasks, such as abstract syntax tree generation, which indicates the potential of using ChatGPT to comprehend code syntax and static behaviors. However, it is unclear whether ChatGPT can complete more complicated real-world vulnerability management tasks, such as the prediction of security relevance and patch correctness, which require an all-encompassing understanding of various aspects, including code syntax, program semantics, and related manual comments. In this paper, we explore ChatGPT's capabilities on 6 tasks involving the complete vulnerability management process with a large-scale dataset containing 78,445 samples. For each task, we compare ChatGPT against SOTA approaches, investigate the impact of different prompts, and explore the difficulties. The results suggest promising potential in leveraging ChatGPT to assist vulnerability management. One notable example is ChatGPT's proficiency in tasks like generating titles for software bug reports. Furthermore, our findings reveal the difficulties encountered by ChatGPT and shed light on promising future directions. For instance, directly providing random demonstration examples in the prompt cannot consistently guarantee good performance in vulnerability management. By contrast, leveraging ChatGPT in a self-heuristic way -- extracting expertise from demonstration examples itself and integrating the extracted expertise in the prompt is a promising research direction. Besides, ChatGPT may misunderstand and misuse the information in the prompt. Consequently, effectively guiding ChatGPT to focus on helpful information rather than the irrelevant content is still an open problem.
FDINet: Protecting against DNN Model Extraction via Feature Distortion Index
Jun 22, 2023Machine Learning as a Service (MLaaS) platforms have gained popularity due to their accessibility, cost-efficiency, scalability, and rapid development capabilities. However, recent research has highlighted the vulnerability of cloud-based models in MLaaS to model extraction attacks. In this paper, we introduce FDINET, a novel defense mechanism that leverages the feature distribution of deep neural network (DNN) models. Concretely, by analyzing the feature distribution from the adversary's queries, we reveal that the feature distribution of these queries deviates from that of the model's training set. Based on this key observation, we propose Feature Distortion Index (FDI), a metric designed to quantitatively measure the feature distribution deviation of received queries. The proposed FDINET utilizes FDI to train a binary detector and exploits FDI similarity to identify colluding adversaries from distributed extraction attacks. We conduct extensive experiments to evaluate FDINET against six state-of-the-art extraction attacks on four benchmark datasets and four popular model architectures. Empirical results demonstrate the following findings FDINET proves to be highly effective in detecting model extraction, achieving a 100% detection accuracy on DFME and DaST. FDINET is highly efficient, using just 50 queries to raise an extraction alarm with an average confidence of 96.08% for GTSRB. FDINET exhibits the capability to identify colluding adversaries with an accuracy exceeding 91%. Additionally, it demonstrates the ability to detect two types of adaptive attacks.
Noise Doesn't Lie: Towards Universal Detection of Deep Inpainting
Jun 03, 2021
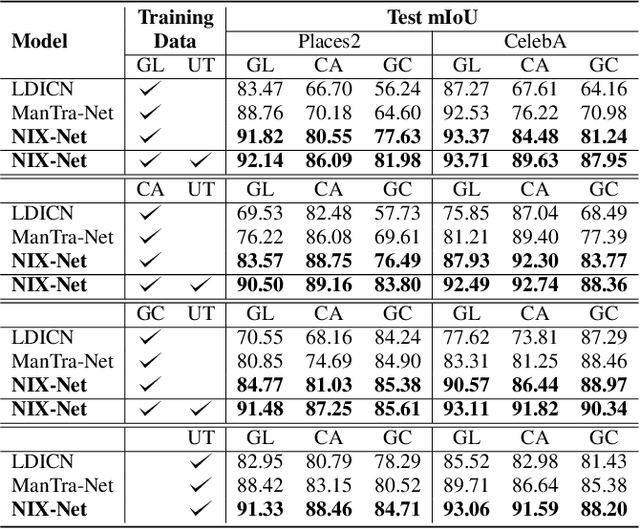

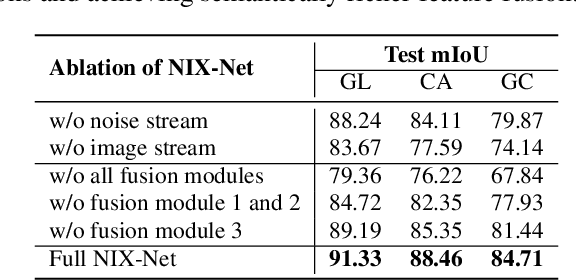
Deep image inpainting aims to restore damaged or missing regions in an image with realistic contents. While having a wide range of applications such as object removal and image recovery, deep inpainting techniques also have the risk of being manipulated for image forgery. A promising countermeasure against such forgeries is deep inpainting detection, which aims to locate the inpainted regions in an image. In this paper, we make the first attempt towards universal detection of deep inpainting, where the detection network can generalize well when detecting different deep inpainting methods. To this end, we first propose a novel data generation approach to generate a universal training dataset, which imitates the noise discrepancies exist in real versus inpainted image contents to train universal detectors. We then design a Noise-Image Cross-fusion Network (NIX-Net) to effectively exploit the discriminative information contained in both the images and their noise patterns. We empirically show, on multiple benchmark datasets, that our approach outperforms existing detection methods by a large margin and generalize well to unseen deep inpainting techniques. Our universal training dataset can also significantly boost the generalizability of existing detection methods.