 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrofit: Continual Learning with Bounded Forgetting for Security Applications
Nov 14, 2025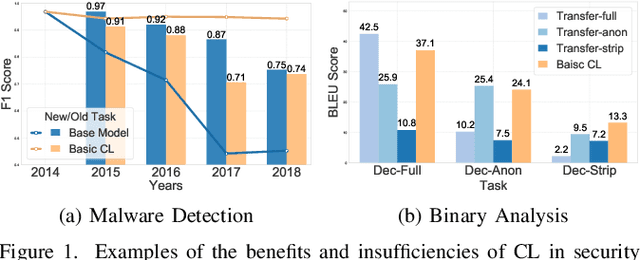
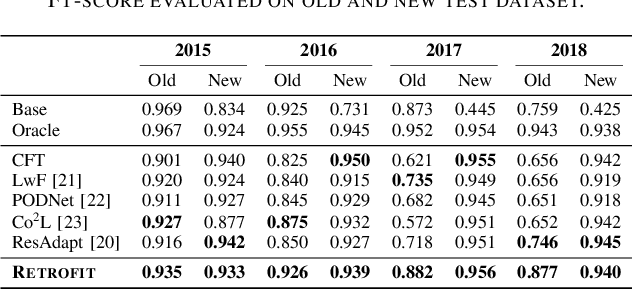

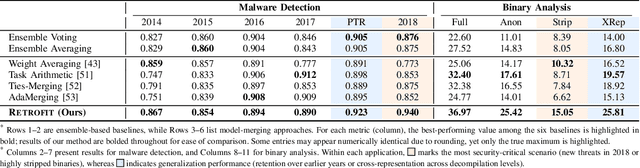
Modern security analytics are increasingly powered by deep learning models, but their performance often degrades as threat landscapes evolve and data representations shift. While continual learning (CL) offers a promising paradigm to maintain model effectiveness, many approaches rely on full retraining or data replay, which are infeasible in data-sensitive environments. Moreover, existing methods remain inadequate for security-critical scenarios, facing two coupled challenges in knowledge transfer: preserving prior knowledge without old data and integrating new knowledge with minimal interference. We propose RETROFIT, a data retrospective-free continual learning method that achieves bounded forgetting for effective knowledge transfer. Our key idea is to consolidate previously trained and newly fine-tuned models, serving as teachers of old and new knowledge, through parameter-level merging that eliminates the need for historical data. To mitigate interference, we apply low-rank and sparse updates that confine parameter changes to independent subspaces, while a knowledge arbitration dynamically balances the teacher contributions guided by model confidence. Our evaluation on two representative applications demonstrates that RETROFIT consistently mitigates forgetting while maintaining adaptability. In malware detection under temporal drift, it substantially improves the retention score, from 20.2% to 38.6% over CL baselines, and exceeds the oracle upper bound on new data. In binary summarization across decompilation levels, where analyzing stripped binaries is especially challenging, RETROFIT achieves around twice the BLEU score of transfer learning used in prior work and surpasses all baselines in cross-representation generalization.
SoK: Large Language Model Copyright Auditing via Fingerprinting
Aug 27, 2025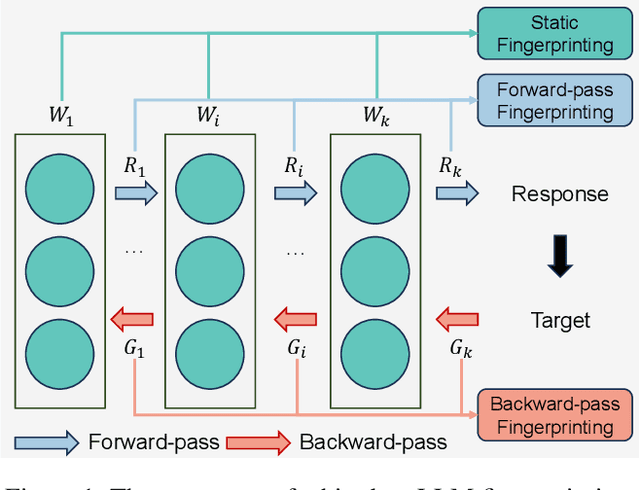

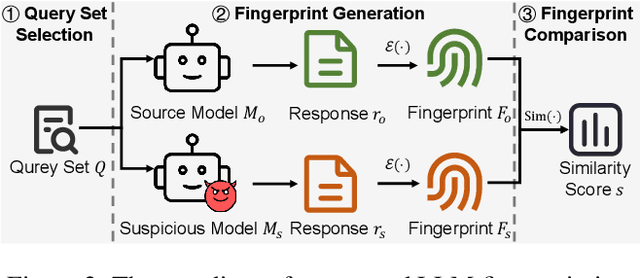

The broad capabilities and substantial resources required to train Large Language Models (LLMs) make them valuable intellectual property, yet they remain vulnerable to copyright infringement, such as unauthorized use and model theft. LLM fingerprinting, a non-intrusive technique that extracts and compares the distinctive features from LLMs to identify infringements, offers a promising solution to copyright auditing. However, its reliability remains uncertain due to the prevalence of diverse model modifications and the lack of standardized evaluation. In this SoK, we present the first comprehensive study of LLM fingerprinting. We introduce a unified framework and formal taxonomy that categorizes existing methods into white-box and black-box approaches, providing a structured overview of the state of the art. We further propose LeaFBench, the first systematic benchmark for evaluating LLM fingerprinting under realistic deployment scenarios. Built upon mainstream foundation models and comprising 149 distinct model instances, LeaFBench integrates 13 representative post-development techniques, spanning both parameter-altering methods (e.g., fine-tuning, quantization) and parameter-independent mechanisms (e.g., system prompts, RAG). Extensive experiments on LeaFBench reveal the strengths and weaknesses of existing methods, thereby outlining future research directions and critical open problems in this emerging field. The code is available at https://github.com/shaoshuo-ss/LeaFBench.
Module-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.
Quantifying Conversation Drift in MCP via Latent Polytope
Aug 08, 2025The Model Context Protocol (MCP) enhances large language models (LLMs) by integrating external tools, enabling dynamic aggregation of real-time data to improve task execution. However, its non-isolated execution context introduces critical security and privacy risks. In particular, adversarially crafted content can induce tool poisoning or indirect prompt injection, leading to conversation hijacking, misinformation propagation, or data exfiltration. Existing defenses, such as rule-based filters or LLM-driven detection, remain inadequate due to their reliance on static signatures, computational inefficiency, and inability to quantify conversational hijacking. To address these limitations, we propose SecMCP, a secure framework that detects and quantifies conversation drift, deviations in latent space trajectories induced by adversarial external knowledge. By modeling LLM activation vectors within a latent polytope space, SecMCP identifies anomalous shifts in conversational dynamics, enabling proactive detection of hijacking, misleading, and data exfiltration. We evaluate SecMCP on three state-of-the-art LLMs (Llama3, Vicuna, Mistral) across benchmark datasets (MS MARCO, HotpotQA, FinQA), demonstrating robust detection with AUROC scores exceeding 0.915 while maintaining system usability. Our contributions include a systematic categorization of MCP security threats, a novel latent polytope-based methodology for quantifying conversation drift, and empirical validation of SecMCP's efficacy.
PRUNE: A Patching Based Repair Framework for Certiffable Unlearning of Neural Networks
May 10, 2025It is often desirable to remove (a.k.a. unlearn) a speciffc part of the training data from a trained neural network model. A typical application scenario is to protect the data holder's right to be forgotten, which has been promoted by many recent regulation rules. Existing unlearning methods involve training alternative models with remaining data, which may be costly and challenging to verify from the data holder or a thirdparty auditor's perspective. In this work, we provide a new angle and propose a novel unlearning approach by imposing carefully crafted "patch" on the original neural network to achieve targeted "forgetting" of the requested data to delete. Speciffcally, inspired by the research line of neural network repair, we propose to strategically seek a lightweight minimum "patch" for unlearning a given data point with certiffable guarantee. Furthermore, to unlearn a considerable amount of data points (or an entire class), we propose to iteratively select a small subset of representative data points to unlearn, which achieves the effect of unlearning the whole set. Extensive experiments on multiple categorical datasets demonstrates our approach's effectiveness, achieving measurable unlearning while preserving the model's performance and being competitive in efffciency and memory consumption compared to various baseline methods.
ControlNET: A Firewall for RAG-based LLM System
Apr 13, 2025Retrieval-Augmented Generation (RAG) has significantly enhanced the factual accuracy and domain adaptability of Large Language Models (LLMs). This advancement has enabled their widespread deployment across sensitive domains such as healthcare, finance, and enterprise applications. RAG mitigates hallucinations by integrating external knowledge, yet introduces privacy risk and security risk, notably data breaching risk and data poisoning risk. While recent studies have explored prompt injection and poisoning attacks, there remains a significant gap in comprehensive research on controlling inbound and outbound query flows to mitigate these threats. In this paper, we propose an AI firewall, ControlNET, designed to safeguard RAG-based LLM systems from these vulnerabilities. ControlNET controls query flows by leveraging activation shift phenomena to detect adversarial queries and mitigate their impact through semantic divergence. We conduct comprehensive experiments on four different benchmark datasets including Msmarco, HotpotQA, FinQA, and MedicalSys using state-of-the-art open source LLMs (Llama3, Vicuna, and Mistral). Our results demonstrate that ControlNET achieves over 0.909 AUROC in detecting and mitigating security threats while preserving system harmlessness. Overall, ControlNET offers an effective, robust, harmless defense mechanism, marking a significant advancement toward the secure deployment of RAG-based LLM systems.
On Benchmarking Code LLMs for Android Malware Analysis
Apr 01, 2025Large Language Models (LLMs) have demonstrated strong capabilities in various code intelligence tasks. However, their effectiveness for Android malware analysis remains underexplored. Decompiled Android code poses unique challenges for analysis, primarily due to its large volume of functions and the frequent absence of meaningful function names. This paper presents Cama, a benchmarking framework designed to systematically evaluate the effectiveness of Code LLMs in Android malware analysis tasks. Cama specifies structured model outputs (comprising function summaries, refined function names, and maliciousness scores) to support key malware analysis tasks, including malicious function identification and malware purpose summarization. Built on these, it integrates three domain-specific evaluation metrics, consistency, fidelity, and semantic relevance, enabling rigorous stability and effectiveness assessment and cross-model comparison. We construct a benchmark dataset consisting of 118 Android malware samples, encompassing over 7.5 million distinct functions, and use Cama to evaluate four popular open-source models. Our experiments provide insights into how Code LLMs interpret decompiled code and quantify the sensitivity to function renaming, highlighting both the potential and current limitations of Code LLMs in malware analysis tasks.
Imperceptible but Forgeable: Practical Invisible Watermark Forgery via Diffusion Models
Mar 28, 2025Invisible watermarking is critical for content provenance and accountability in Generative AI. Although commercial companies have increasingly committed to using watermarks, the robustness of existing watermarking schemes against forgery attacks is understudied. This paper proposes DiffForge, the first watermark forgery framework capable of forging imperceptible watermarks under a no-box setting. We estimate the watermark distribution using an unconditional diffusion model and introduce shallow inversion to inject the watermark into a non-watermarked image seamlessly. This approach facilitates watermark injection while preserving image quality by adaptively selecting the depth of inversion steps, leveraging our key insight that watermarks degrade with added noise during the early diffusion phases. Comprehensive evaluations show that DiffForge deceives open-source watermark detectors with a 96.38% success rate and misleads a commercial watermark system with over 97% success rate, achieving high confidence.1 This work reveals fundamental security limitations in current watermarking paradigms.
Towards Label-Only Membership Inference Attack against Pre-trained Large Language Models
Feb 26, 2025Membership Inference Attacks (MIAs) aim to predict whether a data sample belongs to the model's training set or not. Although prior research has extensively explored MIAs in Large Language Models (LLMs), they typically require accessing to complete output logits (\ie, \textit{logits-based attacks}), which are usually not available in practice. In this paper, we study the vulnerability of pre-trained LLMs to MIAs in the \textit{label-only setting}, where the adversary can only access generated tokens (text). We first reveal that existing label-only MIAs have minor effects in attacking pre-trained LLMs, although they are highly effective in inferring fine-tuning datasets used for personalized LLMs. We find that their failure stems from two main reasons, including better generalization and overly coarse perturbation. Specifically, due to the extensive pre-training corpora and exposing each sample only a few times, LLMs exhibit minimal robustness differences between members and non-members. This makes token-level perturbations too coarse to capture such differences. To alleviate these problems, we propose \textbf{PETAL}: a label-only membership inference attack based on \textbf{PE}r-\textbf{T}oken sem\textbf{A}ntic simi\textbf{L}arity. Specifically, PETAL leverages token-level semantic similarity to approximate output probabilities and subsequently calculate the perplexity. It finally exposes membership based on the common assumption that members are `better' memorized and have smaller perplexity. We conduct extensive experiments on the WikiMIA benchmark and the more challenging MIMIR benchmark. Empirically, our PETAL performs better than the extensions of existing label-only attacks against personalized LLMs and even on par with other advanced logit-based attacks across all metrics on five prevalent open-source LLMs.
REFINE: Inversion-Free Backdoor Defense via Model Reprogramming
Feb 22, 2025Backdoor attacks on deep neural networks (DNNs) have emerged as a significant security threat, allowing adversaries to implant hidden malicious behaviors during the model training phase. Pre-processing-based defense, which is one of the most important defense paradigms, typically focuses on input transformations or backdoor trigger inversion (BTI) to deactivate or eliminate embedded backdoor triggers during the inference process. However, these methods suffer from inherent limitations: transformation-based defenses often fail to balance model utility and defense performance, while BTI-based defenses struggle to accurately reconstruct trigger patterns without prior knowledge. In this paper, we propose REFINE, an inversion-free backdoor defense method based on model reprogramming. REFINE consists of two key components: \textbf{(1)} an input transformation module that disrupts both benign and backdoor patterns, generating new benign features; and \textbf{(2)} an output remapping module that redefines the model's output domain to guide the input transformations effectively. By further integrating supervised contrastive loss, REFINE enhances the defense capabilities while maintaining model utility. Extensive experiments on various benchmark datasets demonstrate the effectiveness of our REFINE and its resistance to potential adaptive attacks.